2 理论算法
Hello 算法 :https://www.hello-algo.com/chapter_preface/
Hello 算法 :https://www.hello-algo.com/chapter_preface/
template <typename Node>
class IListNode
{
Node *mNext;
Node *mPrev;
public:
inline IListNode()
: mNext(nullptr), mPrev(nullptr)
{
}
// 初始化节点
inline void init() { mNext = nullptr, mPrev = nullptr; }
// 获取后继节点
inline Node *getNext() { return mNext; }
// 获取前驱节点
inline Node *getPrev() { return mPrev; };
// 设置后继节点
inline void setNext(Node *next) { mNext = next; }
// 设置前驱节点
inline void setPrev(Node *prev) { mPrev = prev; };
// 设置节点
inline void setNode(Node *next, Node *prev) { mNext = next, mPrev = prev; }
}; template <typename Node>
class IList
{
IListNode<Node> mRoot; // 链表根节点
uint mCount; // 节点计数
public:
// 链表初始化
inline IList()
: mCount(0)
{
mRoot.setNode((Node *)&mRoot, (Node *)&mRoot);
}
// 初始链表
inline void initList() { mCount = 0, mRoot.setNode((Node *)&mRoot, (Node *)&mRoot); }
// 获取根,只读
inline Node *getRoot() { return (Node *)&mRoot; }
// 获取节点计数
inline uint getCount() const { return mCount; }
// 获取第一个节点
inline Node *getEntry()
{
Node *ret = mRoot.getNext();
/* if (ret == &mRoot)
ret = nullptr;*/
return ret;
}
inline Node *front() { return getEntry(); }
// 获取最后一个节点
inline Node *getTail()
{
Node *ret = mRoot.getPrev();
/* if (ret == &mRoot)
ret = nullptr;*/
return ret;
}
inline Node *back() { return getTail(); }
// 从头部插入
inline void insertEntry(Node *node)
{
Node *head = mRoot.getNext();
node->setPrev((Node *)&mRoot);
node->setNext(head);
head->setPrev(node);
mRoot.setNext(node);
++mCount;
}
// 从尾部插入
inline void insertTail(Node *node)
{
Node *tail = mRoot.getPrev();
node->setPrev(tail);
node->setNext((Node *)&mRoot);
tail->setNext(node);
mRoot.setPrev(node);
++mCount;
}
// 从iter前面插入
inline void insert(Node *iter, Node *node)
{
iter->getPrev()->setNext(node);
node->setPrev(iter->getPrev());
node->setNext(iter);
iter->setPrev(node);
++mCount;
}
// 移除节点
inline Node *remove(Node *entry)
{
// 根节点并不能移除
if ((Node *)&mRoot == entry)
return nullptr;
Node *prev = entry->getPrev();
Node *next = entry->getNext();
prev->setNext(next);
next->setPrev(prev);
entry->init();
--mCount;
return entry;
}
// 移除头部节点
inline Node *removeEntry() { return remove(mRoot.getNext()); }
// 移除尾部节点
inline Node *removeTail() { return remove(mRoot.getPrev()); }
};// 向上大小对齐
template <typename T>
inline constexpr T alignup(T num, T base) { return (num + base - 1) & (~(base - 1)); }
// 向下大小对齐
template <typename T>
inline constexpr T aligndown(T num, T base) { return (num & ~(base - 1)); }MD系列算法是信息摘要三大算法中的一种,全称:Message Digest算法,按照规范版本分为MD2、MD4、MD5三种算法,目前最常用的是MD5版本算法。
原文来自:https://www.cnblogs.com/Kingfans/p/16546430.html
MD系列算法是信息摘要三大算法中的一种,全称:Message Digest算法,按照规范版本分为MD2、MD4、MD5三种算法,目前最常用的是MD5版本算法。本文介绍MD2算法的实现原理。
1989年,MD2是由著名的非对称算法RSA发明人之一–麻省理工学院教授罗纳德-里维斯特开发的;这个算法首先对信息进行数据补位,使信息的字节长度是16的倍数,再以16位的检验和作为补充信息追加到原信息的末尾。最后根据这个新产生的信息计算出一个128位的散列值,MD2算法由此诞生。
有关MD2 算法详情请参见 RFC 1319 http://www.ietf.org/rfc/rfc1319.txt,RFC 1319 是MD2算法的官方文档,其实现原理共分为5步:
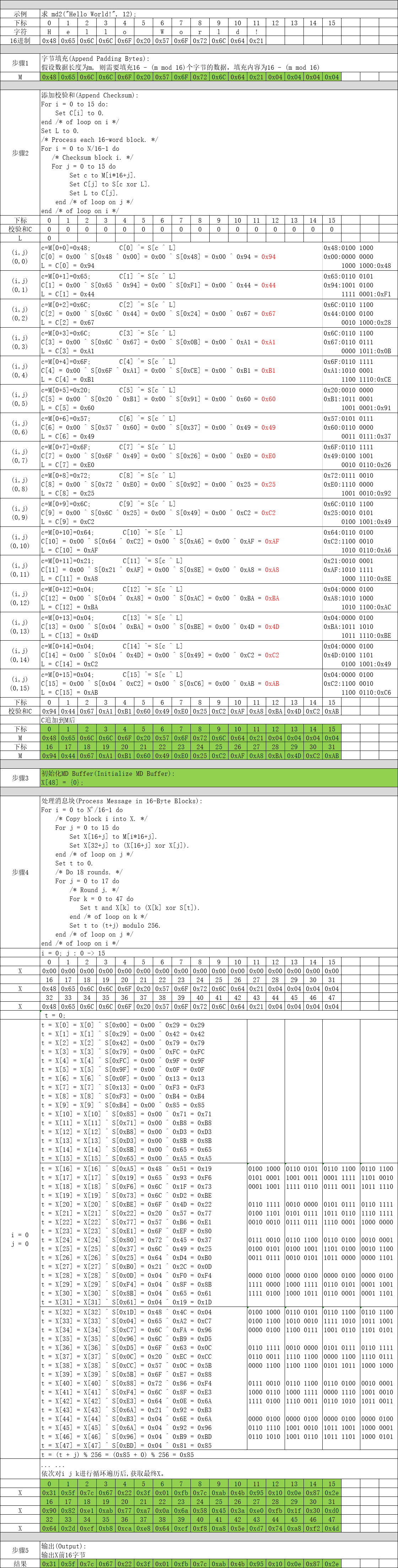
填充1~16个字节,确保是16字节的倍数,填充规则如下:
假设数据长度为m, 则需要填充16 - (m mod 16)个字节的数据,填充内容为16 - (m mod 16)。
根据下列算法计算校验和,并追加到第1步填充数据的后面。
/* Clear checksum. */
For i = 0 to 15 do:
Set C[i] to 0.
end /* of loop on i */
Set L to 0.
/* Process each 16-word block. */
For i = 0 to N/16-1 do
/* Checksum block i. */
For j = 0 to 15 do
Set c to M[i*16+j].
Set C[j] to S[c xor L].
Set L to C[j].
end /* of loop on j */
end /* of loop on i */最简单不过了,定义一个48字节数组X并初始化为0。
这个是MD2算法最核心的部分了,对第2步组装数据进行分块依次处理。
/* Process each 16-word block. */
For i = 0 to N'/16-1 do
/* Copy block i into X. */
For j = 0 to 15 do
Set X[16+j] to M[i*16+j].
Set X[32+j] to (X[16+j] xor X[j]).
end /* of loop on j */
Set t to 0.
/* Do 18 rounds. */
For j = 0 to 17 do
/* Round j. */
For k = 0 to 47 do
Set t and X[k] to (X[k] xor S[t]).
end /* of loop on k */
Set t to (t+j) modulo 256.
end /* of loop on j */
end /* of loop on i */这一步也非常简单,只需要将计算后的X前16字节进行输出就可以了
#include <string.h>
#include <stdio.h>
#define HASH_BLOCK_SIZE 16
#define HASH_DIGEST_SIZE 16
#define HASH_ROUND_NUM 18
#define MD2_CHECKSUM_SIZE 16
#define ASSERT_RETURN_INT(x, d) if(!(x)) { return d; }
/*
* The S Box of MD2 are generated from Pi digits.
*/
static const unsigned char S[256] =
{
0x29, 0x2E, 0x43, 0xC9, 0xA2, 0xD8, 0x7C, 0x01, 0x3D, 0x36, 0x54, 0xA1, 0xEC, 0xF0, 0x06, 0x13,
0x62, 0xA7, 0x05, 0xF3, 0xC0, 0xC7, 0x73, 0x8C, 0x98, 0x93, 0x2B, 0xD9, 0xBC, 0x4C, 0x82, 0xCA,
0x1E, 0x9B, 0x57, 0x3C, 0xFD, 0xD4, 0xE0, 0x16, 0x67, 0x42, 0x6F, 0x18, 0x8A, 0x17, 0xE5, 0x12,
0xBE, 0x4E, 0xC4, 0xD6, 0xDA, 0x9E, 0xDE, 0x49, 0xA0, 0xFB, 0xF5, 0x8E, 0xBB, 0x2F, 0xEE, 0x7A,
0xA9, 0x68, 0x79, 0x91, 0x15, 0xB2, 0x07, 0x3F, 0x94, 0xC2, 0x10, 0x89, 0x0B, 0x22, 0x5F, 0x21,
0x80, 0x7F, 0x5D, 0x9A, 0x5A, 0x90, 0x32, 0x27, 0x35, 0x3E, 0xCC, 0xE7, 0xBF, 0xF7, 0x97, 0x03,
0xFF, 0x19, 0x30, 0xB3, 0x48, 0xA5, 0xB5, 0xD1, 0xD7, 0x5E, 0x92, 0x2A, 0xAC, 0x56, 0xAA, 0xC6,
0x4F, 0xB8, 0x38, 0xD2, 0x96, 0xA4, 0x7D, 0xB6, 0x76, 0xFC, 0x6B, 0xE2, 0x9C, 0x74, 0x04, 0xF1,
0x45, 0x9D, 0x70, 0x59, 0x64, 0x71, 0x87, 0x20, 0x86, 0x5B, 0xCF, 0x65, 0xE6, 0x2D, 0xA8, 0x02,
0x1B, 0x60, 0x25, 0xAD, 0xAE, 0xB0, 0xB9, 0xF6, 0x1C, 0x46, 0x61, 0x69, 0x34, 0x40, 0x7E, 0x0F,
0x55, 0x47, 0xA3, 0x23, 0xDD, 0x51, 0xAF, 0x3A, 0xC3, 0x5C, 0xF9, 0xCE, 0xBA, 0xC5, 0xEA, 0x26,
0x2C, 0x53, 0x0D, 0x6E, 0x85, 0x28, 0x84, 0x09, 0xD3, 0xDF, 0xCD, 0xF4, 0x41, 0x81, 0x4D, 0x52,
0x6A, 0xDC, 0x37, 0xC8, 0x6C, 0xC1, 0xAB, 0xFA, 0x24, 0xE1, 0x7B, 0x08, 0x0C, 0xBD, 0xB1, 0x4A,
0x78, 0x88, 0x95, 0x8B, 0xE3, 0x63, 0xE8, 0x6D, 0xE9, 0xCB, 0xD5, 0xFE, 0x3B, 0x00, 0x1D, 0x39,
0xF2, 0xEF, 0xB7, 0x0E, 0x66, 0x58, 0xD0, 0xE4, 0xA6, 0x77, 0x72, 0xF8, 0xEB, 0x75, 0x4B, 0x0A,
0x31, 0x44, 0x50, 0xB4, 0x8F, 0xED, 0x1F, 0x1A, 0xDB, 0x99, 0x8D, 0x33, 0x9F, 0x11, 0x83, 0x14
};
int md2(unsigned char *out, const unsigned char* in, const int inlen)
{
ASSERT_RETURN_INT(out && in && (inlen >= 0), 1);
int i = 0, j = 0, k = 0;
unsigned char L = 0, t = 0;
// step 1: 字节填充(Append Padding Bytes)
// 假设数据长度为m, 则需要填充16 - (m mod 16)个字节的数据,填充内容为16 - (m mod 16).
int iLen = (inlen / HASH_BLOCK_SIZE + 1) * HASH_BLOCK_SIZE;
unsigned char* M = malloc(iLen + MD2_CHECKSUM_SIZE);
memcpy(M, in, inlen);
for (i = inlen; i < iLen; i++)
{
M[i] = iLen - inlen;
}
// step 2: 添加校验和(Append Checksum)
unsigned char C[MD2_CHECKSUM_SIZE];
memset(C, 0, MD2_CHECKSUM_SIZE);
for (i = 0; i < iLen / HASH_BLOCK_SIZE; i++)
{
for (j = 0; j < HASH_BLOCK_SIZE; j++)
{
unsigned char c = M[i * 16 + j];
C[j] = C[j] ^ S[c ^ L];
L = C[j];
}
}
memcpy(M + iLen, C, HASH_BLOCK_SIZE);
// step 3: 初始化MD Buffer(Initialize MD Buffer):
unsigned char X[48];
memset(X, 0, 48);
// step 4: 处理消息块(Process Message in 16-Byte Blocks)
for (i = 0; i < (iLen + 16) / HASH_BLOCK_SIZE; i++)
{
/* Copy block i into X. */
for (j = 0; j < HASH_BLOCK_SIZE; j++)
{
X[16 + j] = M[i * 16 + j];
X[32 + j] = X[16 + j] ^ X[j];
}
t = 0;
/* Do 18 rounds. */
for (j = 0; j < HASH_ROUND_NUM; j++)
{
/* Round j */
for (k = 0; k < 48; k++)
{
t = X[k] = X[k] ^ S[t];
}
t = (t + j) % 256;
}
}
memcpy(out, X, HASH_DIGEST_SIZE);
free(M);
return 0;
}
int main()
{
unsigned char digest[16] = { 0 };
md2(digest, "Hello World!", strlen("Hello World!"));
return 0;
}原文来自:https://www.cnblogs.com/Kingfans/p/16552308.html
MD系列算法是信息摘要三大算法中的一种,全称:Message Digest算法,按照规范版本分为MD2、MD4、MD5三种算法,目前最常用的是MD5版本算法。本文介绍MD4算法的实现原理。
1990 年,罗纳德·李维斯特教授开发出较之 MD2 算法有着更高安全性的 MD4 算法。在这个算法中,我们仍需对信息进行数据补位。不同的是,这种补位使其信息的字节长度加上 448 个字节后能成为 512 的倍数(信息字节长度 mod 512 = 448)。此外,关于 MD4 算法的处理与 MD2 算法又有很大差别。但最终仍旧是会获得一个 128 位的散列值。MD4 算法对后续消息摘要算法起到了推动作用,许多比较有名的消息摘要算法都是在 MD4 算法的基础上发展而来的,如 MD5、SHA-1、RIPE-MD 和 HAVAL 算法等。
有关 MD4 算法详情请参见 RFC 1320 http://www.ietf.org/rfc/rfc1320.txt,RFC 1320 是MD4算法的官方文档,其实现原理共分为5步:
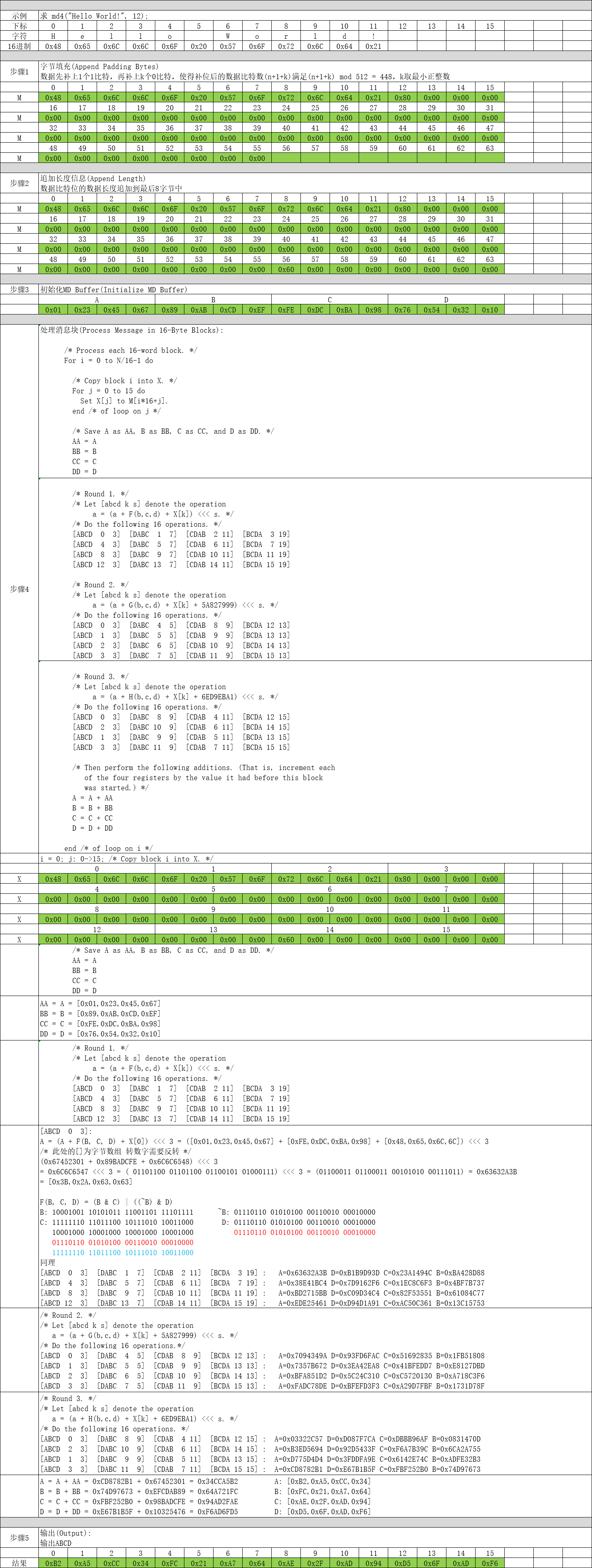
数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数。
数据比特位的数据长度追加到最后8字节中。
这一步最简单了,定义ABCD四个4字节数组,分别赋初值即可。
1
2
3
4
uint32_t A = 0x67452301; // [ 0x01, 0x23, 0x45, 0x67 ]
uint32_t B = 0xEFCDAB89; // [ 0x89, 0xAB, 0xCD, 0xEF ]
uint32_t C = 0x98BADCFE; // [ 0xFE, 0xDC, 0xBA, 0x98 ]
uint32_t D = 0x10325476; // [ 0x76, 0x54, 0x32, 0x10 ] 这个是MD4算法最核心的部分了,对第2步组装数据进行分块依次处理。
Process each 16-word block. */
For i = 0 to N/16-1 do
/* Copy block i into X. */
For j = 0 to 15 do
Set X[j] to M[i*16+j].
end /* of loop on j */
/* Save A as AA, B as BB, C as CC, and D as DD. */
AA = A
BB = B
CC = C
DD = D
/* Round 1. */
/* Let [abcd k s] denote the operation
a = (a + F(b,c,d) + X[k]) <<< s. */
/* Do the following 16 operations. */
[ABCD 0 3] [DABC 1 7] [CDAB 2 11] [BCDA 3 19]
[ABCD 4 3] [DABC 5 7] [CDAB 6 11] [BCDA 7 19]
[ABCD 8 3] [DABC 9 7] [CDAB 10 11] [BCDA 11 19]
[ABCD 12 3] [DABC 13 7] [CDAB 14 11] [BCDA 15 19]
/* Round 2. */
/* Let [abcd k s] denote the operation
a = (a + G(b,c,d) + X[k] + 5A827999) <<< s. */
/* Do the following 16 operations. */
[ABCD 0 3] [DABC 4 5] [CDAB 8 9] [BCDA 12 13]
[ABCD 1 3] [DABC 5 5] [CDAB 9 9] [BCDA 13 13]
[ABCD 2 3] [DABC 6 5] [CDAB 10 9] [BCDA 14 13]
[ABCD 3 3] [DABC 7 5] [CDAB 11 9] [BCDA 15 13]
/* Round 3. */
/* Let [abcd k s] denote the operation
a = (a + H(b,c,d) + X[k] + 6ED9EBA1) <<< s. */
/* Do the following 16 operations. */
[ABCD 0 3] [DABC 8 9] [CDAB 4 11] [BCDA 12 15]
[ABCD 2 3] [DABC 10 9] [CDAB 6 11] [BCDA 14 15]
[ABCD 1 3] [DABC 9 9] [CDAB 5 11] [BCDA 13 15]
[ABCD 3 3] [DABC 11 9] [CDAB 7 11] [BCDA 15 15]
/* Then perform the following additions. (That is, increment each
of the four registers by the value it had before this block
was started.) */
A = A + AA
B = B + BB
C = C + CC
D = D + DD
end /* of loop on i */这一步也非常简单,只需要将计算后的A、B、C、D进行拼接输出即可。
#include <string.h>
#include <stdio.h>
#define HASH_BLOCK_SIZE 64 /* 512 bits = 64 bytes */
#define HASH_LEN_SIZE 8 /* 64 bits = 8 bytes */
#define HASH_LEN_OFFSET 56 /* 64 bytes - 8 bytes */
#define HASH_DIGEST_SIZE 16 /* 128 bits = 16 bytes */
#define HASH_ROUND_NUM 64
typedef unsigned char uint8_t;
typedef unsigned short int uint16_t;
typedef unsigned int uint32_t;
typedef unsigned long long uint64_t;
static uint32_t F(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) | ((~X) & Z);
}
static uint32_t G(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) | (X & Z) | (Y & Z);
}
static uint32_t H(uint32_t X, uint32_t Y, uint32_t Z)
{
return X ^ Y ^ Z;
}
/* 循环向左移动offset个单位 */
static uint32_t MoveLeft(uint32_t X, uint8_t offset)
{
return (X << offset) | (X >> (32 - offset));
}
static uint32_t Round1(uint32_t A, uint32_t B, uint32_t C, uint32_t D, uint32_t M, uint32_t N)
{
return MoveLeft(A + F(B, C, D) + M, N);
}
static uint32_t Round2(uint32_t A, uint32_t B, uint32_t C, uint32_t D, uint32_t M, uint32_t N)
{
return MoveLeft(A + G(B, C, D) + M + 0x5A827999, N);
}
static uint32_t Round3(uint32_t A, uint32_t B, uint32_t C, uint32_t D, uint32_t M, uint32_t N)
{
return MoveLeft(A + H(B, C, D) + M + 0x6ED9EBA1, N);
}
#define ASSERT_RETURN_INT(x, d) if(!(x)) { return d; }
int md4(unsigned char *out, const unsigned char* in, const int inlen)
{
ASSERT_RETURN_INT(out && in && (inlen > 0), 1);
int i = 0, j = 0, k = 0;
unsigned char L = 0, t = 0;
// step 1: 字节填充(Append Padding Bytes)
// 数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数
int iX = inlen / HASH_BLOCK_SIZE;
int iY = inlen % HASH_BLOCK_SIZE;
iX = (iY < HASH_LEN_OFFSET) ? iX : (iX + 1);
int iLen = (iX + 1) * HASH_BLOCK_SIZE;
unsigned char* M = malloc(iLen);
memcpy(M, in, inlen);
// 先补上1个1比特+7个0比特
M[inlen] = 0x80;
// 再补上(k-7)个0比特
for (i = inlen + 1; i < (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET); i++)
{
M[i] = 0;
}
// step 2: 追加长度信息(Append Length)
uint64_t *pLen = (uint64_t*)(M + (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET));
*pLen = inlen << 3;
// Step 3. 初始化MD Buffer(Initialize MD Buffer)
uint32_t A = 0x67452301; // [ 0x01, 0x23, 0x45, 0x67 ]
uint32_t B = 0xEFCDAB89; // [ 0x89, 0xAB, 0xCD, 0xEF ]
uint32_t C = 0x98BADCFE; // [ 0xFE, 0xDC, 0xBA, 0x98 ]
uint32_t D = 0x10325476; // [ 0x76, 0x54, 0x32, 0x10 ]
uint32_t X[HASH_BLOCK_SIZE / 4] = { 0 };
// step 4: 处理消息块(Process Message in 64-Byte Blocks)
for (i = 0; i < iLen / HASH_BLOCK_SIZE; i++)
{
/* Copy block i into X. */
for (j = 0; j < HASH_BLOCK_SIZE; j = j + 4)
{
uint32_t* temp = &M[i * HASH_BLOCK_SIZE + j];
X[j/4] = *temp;
}
/* Save A as AA, B as BB, C as CC, and D as DD. */
uint32_t AA = A;
uint32_t BB = B;
uint32_t CC = C;
uint32_t DD = D;
/* Round 1. */
/* Let [abcd k s] denote the operation
a = (a + F(b,c,d) + X[k]) <<< s. */
/* Do the following 16 operations.
[ABCD 0 3][DABC 1 7][CDAB 2 11][BCDA 3 19]
[ABCD 4 3][DABC 5 7][CDAB 6 11][BCDA 7 19]
[ABCD 8 3][DABC 9 7][CDAB 10 11][BCDA 11 19]
[ABCD 12 3][DABC 13 7][CDAB 14 11][BCDA 15 19]
*/
A = Round1(A, B, C, D, X[0], 3); D = Round1(D, A, B, C, X[1], 7); C = Round1(C, D, A, B, X[2], 11); B = Round1(B, C, D, A, X[3], 19);
A = Round1(A, B, C, D, X[4], 3); D = Round1(D, A, B, C, X[5], 7); C = Round1(C, D, A, B, X[6], 11); B = Round1(B, C, D, A, X[7], 19);
A = Round1(A, B, C, D, X[8], 3); D = Round1(D, A, B, C, X[9], 7); C = Round1(C, D, A, B, X[10], 11); B = Round1(B, C, D, A, X[11], 19);
A = Round1(A, B, C, D, X[12], 3); D = Round1(D, A, B, C, X[13], 7); C = Round1(C, D, A, B, X[14], 11); B = Round1(B, C, D, A, X[15], 19);
/* Round 2. */
/* Let [abcd k s] denote the operation
a = (a + G(b,c,d) + X[k] + 5A827999) <<< s. */
/* Do the following 16 operations.
[ABCD 0 3][DABC 4 5][CDAB 8 9][BCDA 12 13]
[ABCD 1 3][DABC 5 5][CDAB 9 9][BCDA 13 13]
[ABCD 2 3][DABC 6 5][CDAB 10 9][BCDA 14 13]
[ABCD 3 3][DABC 7 5][CDAB 11 9][BCDA 15 13]
*/
A = Round2(A, B, C, D, X[0], 3); D = Round2(D, A, B, C, X[4], 5); C = Round2(C, D, A, B, X[8], 9); B = Round2(B, C, D, A, X[12], 13);
A = Round2(A, B, C, D, X[1], 3); D = Round2(D, A, B, C, X[5], 5); C = Round2(C, D, A, B, X[9], 9); B = Round2(B, C, D, A, X[13], 13);
A = Round2(A, B, C, D, X[2], 3); D = Round2(D, A, B, C, X[6], 5); C = Round2(C, D, A, B, X[10], 9); B = Round2(B, C, D, A, X[14], 13);
A = Round2(A, B, C, D, X[3], 3); D = Round2(D, A, B, C, X[7], 5); C = Round2(C, D, A, B, X[11], 9); B = Round2(B, C, D, A, X[15], 13);
/* Round 3. */
/* Let [abcd k s] denote the operation
a = (a + H(b,c,d) + X[k] + 6ED9EBA1) <<< s. */
/* Do the following 16 operations.
[ABCD 0 3][DABC 8 9][CDAB 4 11][BCDA 12 15]
[ABCD 2 3][DABC 10 9][CDAB 6 11][BCDA 14 15]
[ABCD 1 3][DABC 9 9][CDAB 5 11][BCDA 13 15]
[ABCD 3 3][DABC 11 9][CDAB 7 11][BCDA 15 15]
*/
A = Round3(A, B, C, D, X[0], 3); D = Round3(D, A, B, C, X[8], 9); C = Round3(C, D, A, B, X[4], 11); B = Round3(B, C, D, A, X[12], 15);
A = Round3(A, B, C, D, X[2], 3); D = Round3(D, A, B, C, X[10], 9); C = Round3(C, D, A, B, X[6], 11); B = Round3(B, C, D, A, X[14], 15);
A = Round3(A, B, C, D, X[1], 3); D = Round3(D, A, B, C, X[9], 9); C = Round3(C, D, A, B, X[5], 11); B = Round3(B, C, D, A, X[13], 15);
A = Round3(A, B, C, D, X[3], 3); D = Round3(D, A, B, C, X[11], 9); C = Round3(C, D, A, B, X[7], 11); B = Round3(B, C, D, A, X[15], 15);
/* Then perform the following additions. (That is, increment each
of the four registers by the value it had before this block
was started.) */
A = A + AA;
B = B + BB;
C = C + CC;
D = D + DD;
}
// step 5: 输出ABCD
memcpy(out + 0, &A, 4);
memcpy(out + 4, &B, 4);
memcpy(out + 8, &C, 4);
memcpy(out + 12, &D, 4);
free(M);
return 0;
}
int main()
{
unsigned char digest[16] = { 0 };
md4(digest, "Hello World!", strlen("Hello World!"));
return 0;
}原文来自:https://www.cnblogs.com/Kingfans/p/16554047.html
MD系列算法是信息摘要三大算法中的一种,全称:Message Digest算法,按照规范版本分为MD2、MD4、MD5三种算法,目前最常用的是MD5版本算法。本文介绍MD5算法的实现原理。
1991年,继 MD4 算法后,罗纳德·李维斯特教授开发了 MD5 算法,将 MD 算法推向成熟。MD5 算法经 MD2、MD3 和 MD4 算法发展而来,算法复杂程度和安全强度大大提高。但不管是 MD2、MD4 还是 MD5 算法,其算法的最终结果均是产生一个 128 位的消息摘要,这也是 MD 系列算法的特点。MD5 算法执行效率略次于 MD4 算法,但在安全性方面,MD5 算法更胜一筹。随着计算机技术的发展和计算水平的不断提高,MD5 算法暴露出来的漏洞也越来越多。1996 年后被证实存在弱点,可以被加以破解,对于需要高度安全性的数据,专家一般建议改用其他算法,如 SHA-2。2004 年,证实 MD5 算法无法防止碰撞(collision),因此不适用于安全性认证,如 SSL 公开密钥认证或是数字签名等用途。
有关 MD5 算法详情请参见 RFC 1321 http://www.ietf.org/rfc/rfc1321.txt,RFC 1321 是MD5算法的官方文档,其实现原理共分为5步:
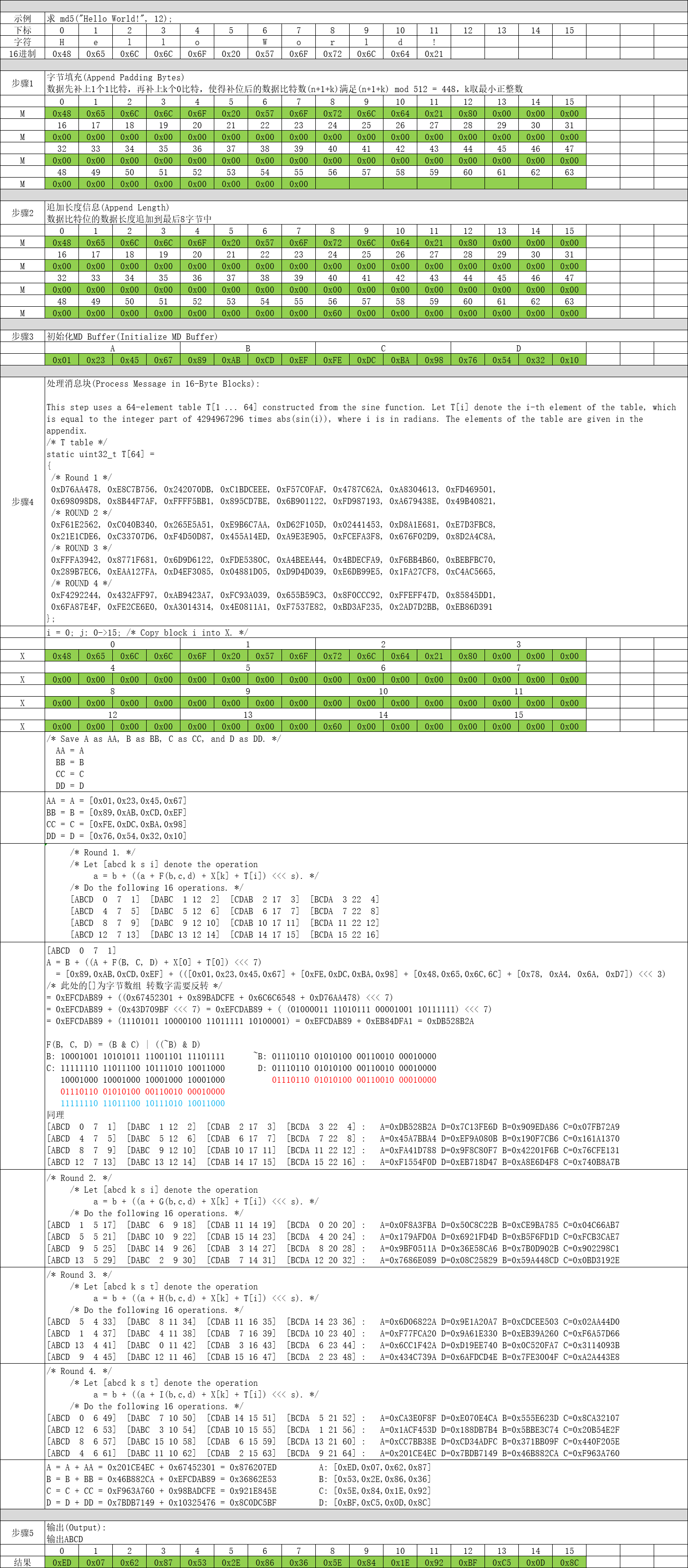
数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数。
数据比特位的数据长度追加到最后8字节中。
这一步最简单了,定义ABCD四个4字节数组,分别赋初值即可。
uint32_t A = 0x67452301; // [ 0x01, 0x23, 0x45, 0x67 ]
uint32_t B = 0xEFCDAB89; // [ 0x89, 0xAB, 0xCD, 0xEF ]
uint32_t C = 0x98BADCFE; // [ 0xFE, 0xDC, 0xBA, 0x98 ]
uint32_t D = 0x10325476; // [ 0x76, 0x54, 0x32, 0x10 ]以上操作与md4完全一致。
这个是MD5算法最核心的部分了,对第2步组装数据进行分块依次处理。
/* Process each 16-word block. */
For i = 0 to N/16-1 do
/* Copy block i into X. */
For j = 0 to 15 do
Set X[j] to M[i*16+j].
end /* of loop on j */
/* Save A as AA, B as BB, C as CC, and D as DD. */
AA = A
BB = B
CC = C
DD = D
/* Round 1. */
/* Let [abcd k s i] denote the operation
a = b + ((a + F(b,c,d) + X[k] + T[i]) <<< s). */
/* Do the following 16 operations. */
[ABCD 0 7 1] [DABC 1 12 2] [CDAB 2 17 3] [BCDA 3 22 4]
[ABCD 4 7 5] [DABC 5 12 6] [CDAB 6 17 7] [BCDA 7 22 8]
[ABCD 8 7 9] [DABC 9 12 10] [CDAB 10 17 11] [BCDA 11 22 12]
[ABCD 12 7 13] [DABC 13 12 14] [CDAB 14 17 15] [BCDA 15 22 16]
/* Round 2. */
/* Let [abcd k s i] denote the operation
a = b + ((a + G(b,c,d) + X[k] + T[i]) <<< s). */
/* Do the following 16 operations. */
[ABCD 1 5 17] [DABC 6 9 18] [CDAB 11 14 19] [BCDA 0 20 20]
[ABCD 5 5 21] [DABC 10 9 22] [CDAB 15 14 23] [BCDA 4 20 24]
[ABCD 9 5 25] [DABC 14 9 26] [CDAB 3 14 27] [BCDA 8 20 28]
[ABCD 13 5 29] [DABC 2 9 30] [CDAB 7 14 31] [BCDA 12 20 32]
/* Round 3. */
/* Let [abcd k s t] denote the operation
a = b + ((a + H(b,c,d) + X[k] + T[i]) <<< s). */
/* Do the following 16 operations. */
[ABCD 5 4 33] [DABC 8 11 34] [CDAB 11 16 35] [BCDA 14 23 36]
[ABCD 1 4 37] [DABC 4 11 38] [CDAB 7 16 39] [BCDA 10 23 40]
[ABCD 13 4 41] [DABC 0 11 42] [CDAB 3 16 43] [BCDA 6 23 44]
[ABCD 9 4 45] [DABC 12 11 46] [CDAB 15 16 47] [BCDA 2 23 48]
/* Round 4. */
/* Let [abcd k s t] denote the operation
a = b + ((a + I(b,c,d) + X[k] + T[i]) <<< s). */
/* Do the following 16 operations. */
[ABCD 0 6 49] [DABC 7 10 50] [CDAB 14 15 51] [BCDA 5 21 52]
[ABCD 12 6 53] [DABC 3 10 54] [CDAB 10 15 55] [BCDA 1 21 56]
[ABCD 8 6 57] [DABC 15 10 58] [CDAB 6 15 59] [BCDA 13 21 60]
[ABCD 4 6 61] [DABC 11 10 62] [CDAB 2 15 63] [BCDA 9 21 64]
/* Then perform the following additions. (That is increment each
of the four registers by the value it had before this block
was started.) */
A = A + AA
B = B + BB
C = C + CC
D = D + DD
end /* of loop on i */这一步也非常简单,只需要将计算后的A、B、C、D进行拼接输出即可。
以下为C/C++代码实现:
#include <string.h>
#include <stdio.h>
#define HASH_BLOCK_SIZE 64 /* 512 bits = 64 bytes */
#define HASH_LEN_SIZE 8 /* 64 bits = 8 bytes */
#define HASH_LEN_OFFSET 56 /* 64 bytes - 8 bytes */
#define HASH_DIGEST_SIZE 16 /* 128 bits = 16 bytes */
typedef unsigned char uint8_t;
typedef unsigned short int uint16_t;
typedef unsigned int uint32_t;
typedef unsigned long long uint64_t;
/* T table */
static uint32_t T[64] =
{
/* Round 1 */
0xD76AA478, 0xE8C7B756, 0x242070DB, 0xC1BDCEEE, 0xF57C0FAF, 0x4787C62A, 0xA8304613, 0xFD469501,
0x698098D8, 0x8B44F7AF, 0xFFFF5BB1, 0x895CD7BE, 0x6B901122, 0xFD987193, 0xA679438E, 0x49B40821,
/* ROUND 2 */
0xF61E2562, 0xC040B340, 0x265E5A51, 0xE9B6C7AA, 0xD62F105D, 0x02441453, 0xD8A1E681, 0xE7D3FBC8,
0x21E1CDE6, 0xC33707D6, 0xF4D50D87, 0x455A14ED, 0xA9E3E905, 0xFCEFA3F8, 0x676F02D9, 0x8D2A4C8A,
/* ROUND 3 */
0xFFFA3942, 0x8771F681, 0x6D9D6122, 0xFDE5380C, 0xA4BEEA44, 0x4BDECFA9, 0xF6BB4B60, 0xBEBFBC70,
0x289B7EC6, 0xEAA127FA, 0xD4EF3085, 0x04881D05, 0xD9D4D039, 0xE6DB99E5, 0x1FA27CF8, 0xC4AC5665,
/* ROUND 4 */
0xF4292244, 0x432AFF97, 0xAB9423A7, 0xFC93A039, 0x655B59C3, 0x8F0CCC92, 0xFFEFF47D, 0x85845DD1,
0x6FA87E4F, 0xFE2CE6E0, 0xA3014314, 0x4E0811A1, 0xF7537E82, 0xBD3AF235, 0x2AD7D2BB, 0xEB86D391
};
static uint32_t F(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) | ((~X) & Z);
}
static uint32_t G(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Z) | (Y & (~Z));
}
static uint32_t H(uint32_t X, uint32_t Y, uint32_t Z)
{
return X ^ Y ^ Z;
}
static uint32_t I(uint32_t X, uint32_t Y, uint32_t Z)
{
return Y ^ ( X | (~Z));
}
/* 循环向左移动offset个比特位 */
static uint32_t MoveLeft(uint32_t X, uint8_t offset)
{
uint32_t res = (X << offset) | (X >> (32 - offset));
return res;
}
static uint32_t Round1(uint32_t A, uint32_t B, uint32_t C, uint32_t D, uint32_t M, uint32_t N, uint32_t T)
{
return B + MoveLeft(A + F(B, C, D) + M + T, N);
}
static uint32_t Round2(uint32_t A, uint32_t B, uint32_t C, uint32_t D, uint32_t M, uint32_t N, uint32_t T)
{
return B + MoveLeft(A + G(B, C, D) + M + T, N);
}
static uint32_t Round3(uint32_t A, uint32_t B, uint32_t C, uint32_t D, uint32_t M, uint32_t N, uint32_t T)
{
return B + MoveLeft(A + H(B, C, D) + M + T, N);
}
static uint32_t Round4(uint32_t A, uint32_t B, uint32_t C, uint32_t D, uint32_t M, uint32_t N, uint32_t T)
{
return B + MoveLeft(A + I(B, C, D) + M + T, N);
}
#define ASSERT_RETURN_INT(x, d) if(!(x)) { return d; }
int md5(unsigned char *out, const unsigned char* in, const int inlen)
{
ASSERT_RETURN_INT(out && in && (inlen >= 0), 1);
int i = 0, j = 0;
// step 1: 字节填充(Append Padding Bytes)
// 数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数
int iX = inlen / HASH_BLOCK_SIZE;
int iY = inlen % HASH_BLOCK_SIZE;
iX = (iY < HASH_LEN_OFFSET) ? iX : (iX + 1);
int iLen = (iX + 1) * HASH_BLOCK_SIZE;
unsigned char* M = malloc(iLen);
memcpy(M, in, inlen);
// 先补上1个1比特+7个0比特
M[inlen] = 0x80;
// 再补上(k-7)个0比特
for (i = inlen + 1; i < (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET); i++)
{
M[i] = 0;
}
// step 2: 追加长度信息(Append Length)
uint64_t *pLen = (uint64_t*)(M + (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET));
*pLen = inlen << 3;
// Step 3. 初始化MD Buffer(Initialize MD Buffer)
uint32_t A = 0x67452301; // 0x01, 0x23, 0x45, 0x67
uint32_t B = 0xEFCDAB89; // 0x89, 0xAB, 0xCD, 0xEF
uint32_t C = 0x98BADCFE; // 0xFE, 0xDC, 0xBA, 0x98
uint32_t D = 0x10325476; // 0x76, 0x54, 0x32, 0x10
uint32_t X[HASH_BLOCK_SIZE / 4] = { 0 };
// step 4: 处理消息块(Process Message in 64-Byte Blocks)
for (i = 0; i < iLen / HASH_BLOCK_SIZE; i++)
{
/* Copy block i into X. */
for (j = 0; j < HASH_BLOCK_SIZE; j = j + 4)
{
uint32_t* temp = &M[i * HASH_BLOCK_SIZE + j];
X[j / 4] = *temp;
}
/* Save A as AA, B as BB, C as CC, and D as DD. */
uint32_t AA = A;
uint32_t BB = B;
uint32_t CC = C;
uint32_t DD = D;
/* Round 1. */
/* Let [abcd k s i] denote the operation
a = b + ((a + F(b,c,d) + X[k] + T[i]) <<< s). */
/* Do the following 16 operations.
[ABCD 0 7 1][DABC 1 12 2][CDAB 2 17 3][BCDA 3 22 4]
[ABCD 4 7 5][DABC 5 12 6][CDAB 6 17 7][BCDA 7 22 8]
[ABCD 8 7 9][DABC 9 12 10][CDAB 10 17 11][BCDA 11 22 12]
[ABCD 12 7 13][DABC 13 12 14][CDAB 14 17 15][BCDA 15 22 16]
此处T[i]有问题 应该是i-1 索引下标从0开始
*/
A = Round1(A, B, C, D, X[0], 7, T[0]); D = Round1(D, A, B, C, X[1], 12, T[1]); C = Round1(C, D, A, B, X[2], 17, T[2]); B = Round1(B, C, D, A, X[3], 22, T[3]);
A = Round1(A, B, C, D, X[4], 7, T[4]); D = Round1(D, A, B, C, X[5], 12, T[5]); C = Round1(C, D, A, B, X[6], 17, T[6]); B = Round1(B, C, D, A, X[7], 22, T[7]);
A = Round1(A, B, C, D, X[8], 7, T[8]); D = Round1(D, A, B, C, X[9], 12, T[9]); C = Round1(C, D, A, B, X[10], 17, T[10]); B = Round1(B, C, D, A, X[11], 22, T[11]);
A = Round1(A, B, C, D, X[12], 7, T[12]); D = Round1(D, A, B, C, X[13], 12, T[13]); C = Round1(C, D, A, B, X[14], 17, T[14]); B = Round1(B, C, D, A, X[15], 22, T[15]);
/* Round 2. */
/* Let [abcd k s i] denote the operation
a = b + ((a + G(b,c,d) + X[k] + T[i]) <<< s). */
/* Do the following 16 operations.
[ABCD 1 5 17][DABC 6 9 18][CDAB 11 14 19][BCDA 0 20 20]
[ABCD 5 5 21][DABC 10 9 22][CDAB 15 14 23][BCDA 4 20 24]
[ABCD 9 5 25][DABC 14 9 26][CDAB 3 14 27][BCDA 8 20 28]
[ABCD 13 5 29][DABC 2 9 30][CDAB 7 14 31][BCDA 12 20 32]
*/
A = Round2(A, B, C, D, X[1], 5, T[16]); D = Round2(D, A, B, C, X[6], 9, T[17]); C = Round2(C, D, A, B, X[11], 14, T[18]); B = Round2(B, C, D, A, X[0], 20, T[19]);
A = Round2(A, B, C, D, X[5], 5, T[20]); D = Round2(D, A, B, C, X[10], 9, T[21]); C = Round2(C, D, A, B, X[15], 14, T[22]); B = Round2(B, C, D, A, X[4], 20, T[23]);
A = Round2(A, B, C, D, X[9], 5, T[24]); D = Round2(D, A, B, C, X[14], 9, T[25]); C = Round2(C, D, A, B, X[3], 14, T[26]); B = Round2(B, C, D, A, X[8], 20, T[27]);
A = Round2(A, B, C, D, X[13], 5, T[28]); D = Round2(D, A, B, C, X[2], 9, T[29]); C = Round2(C, D, A, B, X[7], 14, T[30]); B = Round2(B, C, D, A, X[12], 20, T[31]);
/* Round 3. */
/* Let [abcd k s t] denote the operation
a = b + ((a + H(b,c,d) + X[k] + T[i]) <<< s). */
/* Do the following 16 operations.
[ABCD 5 4 33][DABC 8 11 34][CDAB 11 16 35][BCDA 14 23 36]
[ABCD 1 4 37][DABC 4 11 38][CDAB 7 16 39][BCDA 10 23 40]
[ABCD 13 4 41][DABC 0 11 42][CDAB 3 16 43][BCDA 6 23 44]
[ABCD 9 4 45][DABC 12 11 46][CDAB 15 16 47][BCDA 2 23 48]
*/
A = Round3(A, B, C, D, X[5], 4, T[32]); D = Round3(D, A, B, C, X[8], 11, T[33]); C = Round3(C, D, A, B, X[11], 16, T[34]); B = Round3(B, C, D, A, X[14], 23, T[35]);
A = Round3(A, B, C, D, X[1], 4, T[36]); D = Round3(D, A, B, C, X[4], 11, T[37]); C = Round3(C, D, A, B, X[7], 16, T[38]); B = Round3(B, C, D, A, X[10], 23, T[39]);
A = Round3(A, B, C, D, X[13], 4, T[40]); D = Round3(D, A, B, C, X[0], 11, T[41]); C = Round3(C, D, A, B, X[3], 16, T[42]); B = Round3(B, C, D, A, X[6], 23, T[43]);
A = Round3(A, B, C, D, X[9], 4, T[44]); D = Round3(D, A, B, C, X[12], 11, T[45]); C = Round3(C, D, A, B, X[15], 16, T[46]); B = Round3(B, C, D, A, X[2], 23, T[47]);
/* Round 4. */
/* Let [abcd k s t] denote the operation
a = b + ((a + I(b,c,d) + X[k] + T[i]) <<< s). */
/* Do the following 16 operations.
[ABCD 0 6 49][DABC 7 10 50][CDAB 14 15 51][BCDA 5 21 52]
[ABCD 12 6 53][DABC 3 10 54][CDAB 10 15 55][BCDA 1 21 56]
[ABCD 8 6 57][DABC 15 10 58][CDAB 6 15 59][BCDA 13 21 60]
[ABCD 4 6 61][DABC 11 10 62][CDAB 2 15 63][BCDA 9 21 64]
*/
A = Round4(A, B, C, D, X[0], 6, T[48]); D = Round4(D, A, B, C, X[7], 10, T[49]); C = Round4(C, D, A, B, X[14], 15, T[50]); B = Round4(B, C, D, A, X[5], 21, T[51]);
A = Round4(A, B, C, D, X[12], 6, T[52]); D = Round4(D, A, B, C, X[3], 10, T[53]); C = Round4(C, D, A, B, X[10], 15, T[54]); B = Round4(B, C, D, A, X[1], 21, T[55]);
A = Round4(A, B, C, D, X[8], 6, T[56]); D = Round4(D, A, B, C, X[15], 10, T[57]); C = Round4(C, D, A, B, X[6], 15, T[58]); B = Round4(B, C, D, A, X[13], 21, T[59]);
A = Round4(A, B, C, D, X[4], 6, T[60]); D = Round4(D, A, B, C, X[11], 10, T[61]); C = Round4(C, D, A, B, X[2], 15, T[62]); B = Round4(B, C, D, A, X[9], 21, T[63]);
/* Then perform the following additions. (That is, increment each
of the four registers by the value it had before this block
was started.) */
A = A + AA;
B = B + BB;
C = C + CC;
D = D + DD;
}
// step 5: 输出ABCD
memcpy(out + 0, &A, 4);
memcpy(out + 4, &B, 4);
memcpy(out + 8, &C, 4);
memcpy(out + 12, &D, 4);
free(M);
return 0;
}
int main()
{
unsigned char digest[16] = { 0 };
md5(digest, "Hello World!", strlen("Hello World!"));
return 0;
}原文来自:https://www.cnblogs.com/Kingfans/p/16546386.html
SHA (Security Hash Algorithm) 是美国的 NIST 和 NSA 设计的一种标准的 Hash 算法,SHA 用于数字签名的标准算法的 DSS 中,也是安全性很高的一种 Hash 算法。
原文来自:https://www.cnblogs.com/Kingfans/p/16561821.html
SHA (Security Hash Algorithm) 是美国的 NIST 和 NSA 设计的一种标准的 Hash 算法,SHA 用于数字签名的标准算法的 DSS 中,也是安全性很高的一种 Hash 算法。
SHA-1 是第一代 SHA 算法标准,后来的 SHA-224、SHA-256、SHA-384 和 SHA-512 被统称为 SHA-2。
有关 SHA1 算法详情请参见 RFC 3174 http://www.ietf.org/rfc/rfc3174.txt。
RFC 3174 是SHA1算法的官方文档,(建议了解SHA1算法前,先了解下MD4 md4算法实现原理深剖 )其实现原理共分为5步:
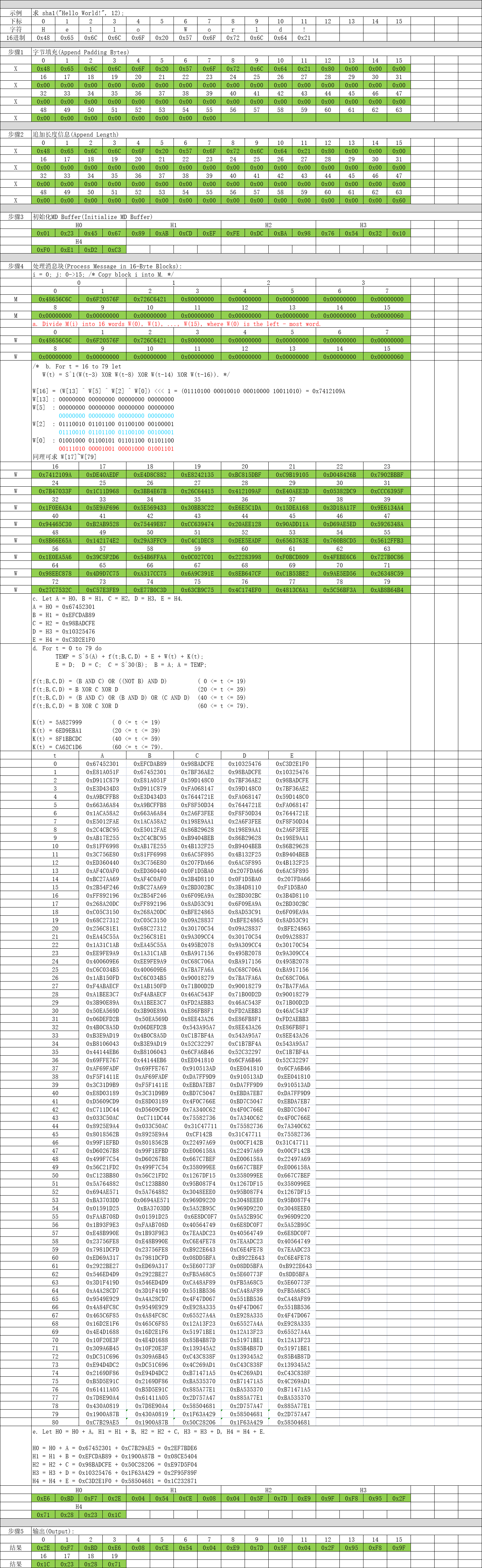
数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数。
数据比特位的数据长度追加到最后8字节中。【注意字节顺序与MD4不同 大小端之分】
这一步最简单了,定义ABCD四个4字节数组,分别赋初值即可。【注意相对于MD4 添加了H4】
uint32_t H0 = 0x67452301; // 0x01, 0x23, 0x45, 0x67
uint32_t H1 = 0xEFCDAB89; // 0x89, 0xAB, 0xCD, 0xEF
uint32_t H2 = 0x98BADCFE; // 0xFE, 0xDC, 0xBA, 0x98
uint32_t H3 = 0x10325476; // 0x76, 0x54, 0x32, 0x10
uint32_t H4 = 0xC3D2E1F0; // 0xF0, 0xE1, 0xD2, 0xC3
这个是SHA1算法最核心的部分了,对第2步组装数据进行分块依次处理。
/* Process each 16-word block. */
For i = 0 to N/16-1 do
/* Copy block i into X. */
For j = 0 to 15 do
Set X[j] to M[i*16+j].
end /* of loop on j */
a. Divide M(i) into 16 words W(0), W(1), ... , W(15), where W(0) is the left-most word.
b. For t = 16 to 79 let
W(t) = S^1(W(t-3) XOR W(t-8) XOR W(t-14) XOR W(t-16)).
c. Let A = H0, B = H1, C = H2, D = H3, E = H4.
d. For t = 0 to 79 do
TEMP = S^5(A) + f(t;B,C,D) + E + W(t) + K(t);
E = D; D = C; C = S^30(B); B = A; A = TEMP;
e. Let H0 = H0 + A, H1 = H1 + B, H2 = H2 + C, H3 = H3 + D, H4 = H4 + E.
end /* of loop on i */这一步也非常简单,只需要将计算后的H0、H1、H2、H3、H4进行拼接输出即可。
三、示例讲解
四、代码实现 以下为C/C++代码实现:
#include <string.h>
#include <stdio.h>
#define HASH_BLOCK_SIZE 64 /* 512 bits = 64 bytes */
#define HASH_LEN_SIZE 8 /* 64 bits = 8 bytes */
#define HASH_LEN_OFFSET 56 /* 64 bytes - 8 bytes */
#define HASH_DIGEST_SIZE 16 /* 128 bits = 16 bytes */
#define HASH_ROUND_NUM 80
typedef unsigned char uint8_t;
typedef unsigned short int uint16_t;
typedef unsigned int uint32_t;
typedef unsigned long long uint64_t;
/* Swap bytes in 32 bit value. 0x01234567 -> 0x67452301 */
#define __bswap_32(x) \
((((x) & 0xff000000) >> 24) \
| (((x) & 0x00ff0000) >> 8) \
| (((x) & 0x0000ff00) << 8) \
| (((x) & 0x000000ff) << 24))
/* SHA1 Constants */
static uint32_t K[4] =
{
0x5A827999, /* [0, 19] */
0x6ED9EBA1, /* [20, 39] */
0x8F1BBCDC, /* [40, 59] */
0xCA62C1D6 /* [60, 79] */
};
/* f(X, Y, Z) */
/* [0, 19] */
static uint32_t Ch(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) ^ ((~X) & Z);
}
/* [20, 39] */ /* [60, 79] */
static uint32_t Parity(uint32_t X, uint32_t Y, uint32_t Z)
{
return X ^ Y ^ Z;
}
/* [40, 59] */
static uint32_t Maj(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) ^ (X & Z) ^ (Y & Z);
}
/* 循环向左移动offset个比特位 */
static uint32_t MoveLeft(uint32_t X, uint8_t offset)
{
uint32_t res = (X << offset) | (X >> (32 - offset));
return res;
}
#define ASSERT_RETURN_INT(x, d) if(!(x)) { return d; }
int sha1(unsigned char *out, const unsigned char* in, const int inlen)
{
ASSERT_RETURN_INT(out && in && (inlen >= 0), 1);
int i = 0, j = 0, t = 0;
// step 1: 字节填充(Append Padding Bytes)
// 数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数
int iX = inlen / HASH_BLOCK_SIZE;
int iY = inlen % HASH_BLOCK_SIZE;
iX = (iY < HASH_LEN_OFFSET) ? iX : (iX + 1);
int iLen = (iX + 1) * HASH_BLOCK_SIZE;
unsigned char* X = malloc(iLen);
memcpy(X, in, inlen);
// 先补上1个1比特+7个0比特
X[inlen] = 0x80;
// 再补上(k-7)个0比特
for (i = inlen + 1; i < (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET); i++)
{
X[i] = 0;
}
// step 2: 追加长度信息(Append Length)
uint8_t *pLen = (uint64_t*)(X + (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET));
uint64_t iTempLen = inlen << 3;
uint8_t *pTempLen = &iTempLen;
pLen[0] = pTempLen[7]; pLen[1] = pTempLen[6]; pLen[2] = pTempLen[5]; pLen[3] = pTempLen[4];
pLen[4] = pTempLen[3]; pLen[5] = pTempLen[2]; pLen[6] = pTempLen[1]; pLen[7] = pTempLen[0];
// Step 3. 初始化MD Buffer(Initialize MD Buffer)
uint32_t H0 = 0x67452301; // 0x01, 0x23, 0x45, 0x67
uint32_t H1 = 0xEFCDAB89; // 0x89, 0xAB, 0xCD, 0xEF
uint32_t H2 = 0x98BADCFE; // 0xFE, 0xDC, 0xBA, 0x98
uint32_t H3 = 0x10325476; // 0x76, 0x54, 0x32, 0x10
uint32_t H4 = 0xC3D2E1F0; // 0xF0, 0xE1, 0xD2, 0xC3
uint32_t M[HASH_BLOCK_SIZE / 4] = { 0 };
uint32_t W[HASH_ROUND_NUM] = { 0 };
// step 4: 处理消息块(Process Message in 64-Byte Blocks)
for (i = 0; i < iLen / HASH_BLOCK_SIZE; i++)
{
/* Copy block i into X. */
for (j = 0; j < HASH_BLOCK_SIZE; j = j + 4)
{
uint64_t k = i * HASH_BLOCK_SIZE + j;
M[j / 4] = (X[k] << 24) | (X[k + 1] << 16) | (X[k + 2] << 8) | X[k + 3];
}
/* a. Divide M(i) into 16 words W(0), W(1), ..., W(15), where W(0) is the left - most word. */
for (t = 0; t <= 15; t++)
{
W[t] = M[t];
}
/* b. For t = 16 to 79 let
W(t) = S^1(W(t-3) XOR W(t-8) XOR W(t-14) XOR W(t-16)). */
for (t = 16; t <= 79; t++)
{
W[t] = MoveLeft(W[t - 3] ^ W[t - 8] ^ W[t - 14] ^ W[t - 16], 1);
}
/* c. Let A = H0, B = H1, C = H2, D = H3, E = H4. */
uint32_t A = H0;
uint32_t B = H1;
uint32_t C = H2;
uint32_t D = H3;
uint32_t E = H4;
/* d. For t = 0 to 79 do
TEMP = S^5(A) + f(t;B,C,D) + E + W(t) + K(t);
E = D; D = C; C = S^30(B); B = A; A = TEMP; */
for (t = 0; t <= 19; t++)
{
uint32_t temp = MoveLeft(A, 5) + Ch(B, C, D) + E + W[t] + K[0];
E = D;
D = C;
C = MoveLeft(B, 30);
B = A;
A = temp;
}
for (t = 20; t <= 39; t++)
{
uint32_t temp = MoveLeft(A, 5) + Parity(B, C, D) + E + W[t] + K[1];
E = D;
D = C;
C = MoveLeft(B, 30);
B = A;
A = temp;
}
for (t = 40; t <= 59; t++)
{
uint32_t temp = MoveLeft(A, 5) + Maj(B, C, D) + E + W[t] + K[2];
E = D;
D = C;
C = MoveLeft(B, 30);
B = A;
A = temp;
}
for (t = 60; t <= 79; t++)
{
uint32_t temp = MoveLeft(A, 5) + Parity(B, C, D) + E + W[t] + K[3];
E = D;
D = C;
C = MoveLeft(B, 30);
B = A;
A = temp;
}
/* e. Let H0 = H0 + A, H1 = H1 + B, H2 = H2 + C, H3 = H3 + D, H4 = H4 + E. */
H0 = H0 + A;
H1 = H1 + B;
H2 = H2 + C;
H3 = H3 + D;
H4 = H4 + E;
}
// step 5: 输出ABCD
uint32_t* pOut = (uint8_t*)out;
pOut[0] = __bswap_32(H0);
pOut[1] = __bswap_32(H1);
pOut[2] = __bswap_32(H2);
pOut[3] = __bswap_32(H3);
pOut[4] = __bswap_32(H4);
free(X);
return 0;
}
int main()
{
unsigned char digest[20] = { 0 };
sha1(digest, "Hello World!", strlen("Hello World!"));
return 0;
}原文来自:https://www.cnblogs.com/Kingfans/p/16572411.html
SHA (Security Hash Algorithm) 是美国的 NIST 和 NSA 设计的一种标准的 Hash 算法,SHA 用于数字签名的标准算法的 DSS 中,也是安全性很高的一种 Hash 算法。
SHA-1 是第一代 SHA 算法标准,后来的 SHA-224、SHA-256、SHA-384 和 SHA-512 被统称为 SHA-2。本文介绍SHA2-224算法的实现原理。
有关 SHA2-224 算法详情请参见 NIST.FIPS.180-4 。

NIST.FIPS.180-4 是SHA2-224算法的官方文档,(建议了解SHA2-224算法前,先了解下SHA2-256 sha2-256算法实现原理深剖 )其实现原理共分为5步:
数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数。
数据比特位的数据长度追加到最后8字节中。
这一步最简单了,定义ABCD四个4字节数组,分别赋初值即可。
uint32_t H0 = 0xC1059ED8;
uint32_t H1 = 0x367CD507;
uint32_t H2 = 0x3070DD17;
uint32_t H3 = 0xF70E5939;
uint32_t H4 = 0xFFC00B31;
uint32_t H5 = 0x68581511;
uint32_t H6 = 0x64F98FA7;
uint32_t H7 = 0xBEFA4FA4;这个是SHA2-224算法最核心的部分了,对第2步组装数据进行分块依次处理。

这一步也非常简单,只需要将计算后的H0、H1、H2、H3、H4、H5、H6进行拼接输出即可。
由于SHA2–224与SHA2-256算法完全一致,只是hash value初始赋值和输出结果不同。
具体示例讲解看参考SHA2-256示例讲解,此处不再重复。
以下为C/C++代码实现:
#include <string.h>
#include <stdio.h>
#define HASH_BLOCK_SIZE 64 /* 512 bits = 64 bytes */
#define HASH_LEN_SIZE 8 /* 64 bits = 8 bytes */
#define HASH_LEN_OFFSET 56 /* 64 bytes - 8 bytes */
#define HASH_DIGEST_SIZE 16 /* 128 bits = 16 bytes */
#define HASH_ROUND_NUM 64
typedef unsigned char uint8_t;
typedef unsigned short int uint16_t;
typedef unsigned int uint32_t;
typedef unsigned long long uint64_t;
/* SHA256 Constants */
static const uint32_t K[HASH_ROUND_NUM] = {
0x428A2F98, 0x71374491, 0xB5C0FBCF, 0xE9B5DBA5,
0x3956C25B, 0x59F111F1, 0x923F82A4, 0xAB1C5ED5,
0xD807AA98, 0x12835B01, 0x243185BE, 0x550C7DC3,
0x72BE5D74, 0x80DEB1FE, 0x9BDC06A7, 0xC19BF174,
0xE49B69C1, 0xEFBE4786, 0x0FC19DC6, 0x240CA1CC,
0x2DE92C6F, 0x4A7484AA, 0x5CB0A9DC, 0x76F988DA,
0x983E5152, 0xA831C66D, 0xB00327C8, 0xBF597FC7,
0xC6E00BF3, 0xD5A79147, 0x06CA6351, 0x14292967,
0x27B70A85, 0x2E1B2138, 0x4D2C6DFC, 0x53380D13,
0x650A7354, 0x766A0ABB, 0x81C2C92E, 0x92722C85,
0xA2BFE8A1, 0xA81A664B, 0xC24B8B70, 0xC76C51A3,
0xD192E819, 0xD6990624, 0xF40E3585, 0x106AA070,
0x19A4C116, 0x1E376C08, 0x2748774C, 0x34B0BCB5,
0x391C0CB3, 0x4ED8AA4A, 0x5B9CCA4F, 0x682E6FF3,
0x748F82EE, 0x78A5636F, 0x84C87814, 0x8CC70208,
0x90BEFFFA, 0xA4506CEB, 0xBEF9A3F7, 0xC67178F2
};
/* Swap bytes in 32 bit value. 0x01234567 -> 0x67452301 */
#define __bswap_32(x) \
((((x) & 0xff000000) >> 24) \
| (((x) & 0x00ff0000) >> 8) \
| (((x) & 0x0000ff00) << 8) \
| (((x) & 0x000000ff) << 24))
static uint32_t Ch(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) ^ ((~X) & Z);
}
static uint32_t Maj(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) ^ (X & Z) ^ (Y & Z);
}
/* 循环向右移动offset个比特位 */
static uint32_t ROTR(uint32_t X, uint8_t offset)
{
uint32_t res = (X >> offset) | (X << (32 - offset));
return res;
}
/* 向右移动offset个比特位 */
static uint32_t SHR(uint32_t X, uint8_t offset)
{
uint32_t res = X >> offset;
return res;
}
/* SIGMA0 */
static uint32_t SIGMA0(uint32_t X)
{
return ROTR(X, 2) ^ ROTR(X, 13) ^ ROTR(X, 22);
}
/* SIGMA1 */
static uint32_t SIGMA1(uint32_t X)
{
return ROTR(X, 6) ^ ROTR(X, 11) ^ ROTR(X, 25);
}
/* sigma0, different from SIGMA0 */
static uint32_t sigma0(uint32_t X)
{
uint32_t res = ROTR(X, 7) ^ ROTR(X, 18) ^ SHR(X, 3);
return ROTR(X, 7) ^ ROTR(X, 18) ^ SHR(X, 3);
}
/* sigma1, different from SIGMA1 */
static uint32_t sigma1(uint32_t X)
{
return ROTR(X, 17) ^ ROTR(X, 19) ^ SHR(X, 10);
}
#define ASSERT_RETURN_INT(x, d) if(!(x)) { return d; }
int sha2_224(unsigned char *out, const unsigned char* in, const int inlen)
{
ASSERT_RETURN_INT(out && in && (inlen >= 0), 1);
int i = 0, j = 0, t = 0;
// step 1: 字节填充(Append Padding Bytes)
// 数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数
int iX = inlen / HASH_BLOCK_SIZE;
int iY = inlen % HASH_BLOCK_SIZE;
iX = (iY < HASH_LEN_OFFSET) ? iX : (iX + 1);
int iLen = (iX + 1) * HASH_BLOCK_SIZE;
unsigned char* X = malloc(iLen);
memcpy(X, in, inlen);
// 先补上1个1比特+7个0比特
X[inlen] = 0x80;
// 再补上(k-7)个0比特
for (i = inlen + 1; i < (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET); i++)
{
X[i] = 0;
}
// step 2: 追加长度信息(Append Length)
uint8_t *pLen = (uint64_t*)(X + (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET));
uint64_t iTempLen = inlen << 3;
uint8_t *pTempLen = &iTempLen;
pLen[0] = pTempLen[7]; pLen[1] = pTempLen[6]; pLen[2] = pTempLen[5]; pLen[3] = pTempLen[4];
pLen[4] = pTempLen[3]; pLen[5] = pTempLen[2]; pLen[6] = pTempLen[1]; pLen[7] = pTempLen[0];
// Step 3. 初始化MD Buffer(Initialize MD Buffer)
uint32_t H0 = 0xC1059ED8;
uint32_t H1 = 0x367CD507;
uint32_t H2 = 0x3070DD17;
uint32_t H3 = 0xF70E5939;
uint32_t H4 = 0xFFC00B31;
uint32_t H5 = 0x68581511;
uint32_t H6 = 0x64F98FA7;
uint32_t H7 = 0xBEFA4FA4;
uint32_t M[HASH_BLOCK_SIZE / 4] = { 0 };
uint32_t W[HASH_ROUND_NUM] = { 0 };
// step 4: 处理消息块(Process Message in 64-Byte Blocks)
for (i = 0; i < iLen / HASH_BLOCK_SIZE; i++)
{
/* Copy block i into M. */
for (j = 0; j < HASH_BLOCK_SIZE; j = j + 4)
{
uint64_t k = i * HASH_BLOCK_SIZE + j;
M[j / 4] = (X[k] << 24) | (X[k + 1] << 16) | (X[k + 2] << 8) | X[k + 3];
}
/* W[t]=M[t]; t:[0,15] */
for (t = 0; t <= 15; t++)
{
W[t] = M[t];
}
/* W[t] = sigma1(W[t - 2]) + W[t - 7] + sigma0(W[t - 15]) + W[t - 16]; t:[16,63] */
for (t = 16; t < HASH_ROUND_NUM; t++)
{
W[t] = sigma1(W[t - 2]) + W[t - 7] + sigma0(W[t - 15]) + W[t - 16];
}
uint32_t A = H0;
uint32_t B = H1;
uint32_t C = H2;
uint32_t D = H3;
uint32_t E = H4;
uint32_t F = H5;
uint32_t G = H6;
uint32_t H = H7;
for (t = 0; t < HASH_ROUND_NUM; t++)
{
uint32_t T1 = H + SIGMA1(E) + Ch(E, F, G) + K[t] + W[t];
uint32_t T2 = SIGMA0(A) + Maj(A, B, C);
H = G;
G = F;
F = E;
E = D + T1;
D = C;
C = B;
B = A;
A = T1 + T2;
}
H0 = H0 + A;
H1 = H1 + B;
H2 = H2 + C;
H3 = H3 + D;
H4 = H4 + E;
H5 = H5 + F;
H6 = H6 + G;
H7 = H7 + H;
}
// step 5: 输出
uint32_t* pOut = (uint8_t*)out;
pOut[0] = __bswap_32(H0);
pOut[1] = __bswap_32(H1);
pOut[2] = __bswap_32(H2);
pOut[3] = __bswap_32(H3);
pOut[4] = __bswap_32(H4);
pOut[5] = __bswap_32(H5);
pOut[6] = __bswap_32(H6);
free(X);
return 0;
}
int main()
{
unsigned char digest[28] = { 0 };
sha2_224(digest, "Hello World!", strlen("Hello World!"));
return 0;
}原文来自:https://www.cnblogs.com/Kingfans/p/16571435.html
SHA (Security Hash Algorithm) 是美国的 NIST 和 NSA 设计的一种标准的 Hash 算法,SHA 用于数字签名的标准算法的 DSS 中,也是安全性很高的一种 Hash 算法。
SHA-1 是第一代 SHA 算法标准,后来的 SHA-224、SHA-256、SHA-384 和 SHA-512 被统称为 SHA-2。本文介绍SHA2-256算法的实现原理。
有关 SHA2-256 算法详情请参见 NIST.FIPS.180-4 。

NIST.FIPS.180-4 是SHA2-256算法的官方文档,(建议了解SHA2-256算法前,先了解下SHA1 sha1算法实现原理深剖 )其实现原理共分为5步:
数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数。
数据比特位的数据长度追加到最后8字节中。【以上与sha1完全一致】
这一步最简单了,定义ABCD四个4字节数组,分别赋初值即可。
uint32_t H0 = 0x6A09E667;
uint32_t H1 = 0xBB67AE85;
uint32_t H2 = 0x3C6EF372;
uint32_t H3 = 0xA54FF53A;
uint32_t H4 = 0x510E527F;
uint32_t H5 = 0x9B05688C;
uint32_t H6 = 0x1F83D9AB;
uint32_t H7 = 0x5BE0CD19;这个是SHA2-256算法最核心的部分了,对第2步组装数据进行分块依次处理。

这一步也非常简单,只需要将计算后的H0、H1、H2、H3、H4、H5、H6、H7进行拼接输出即可。
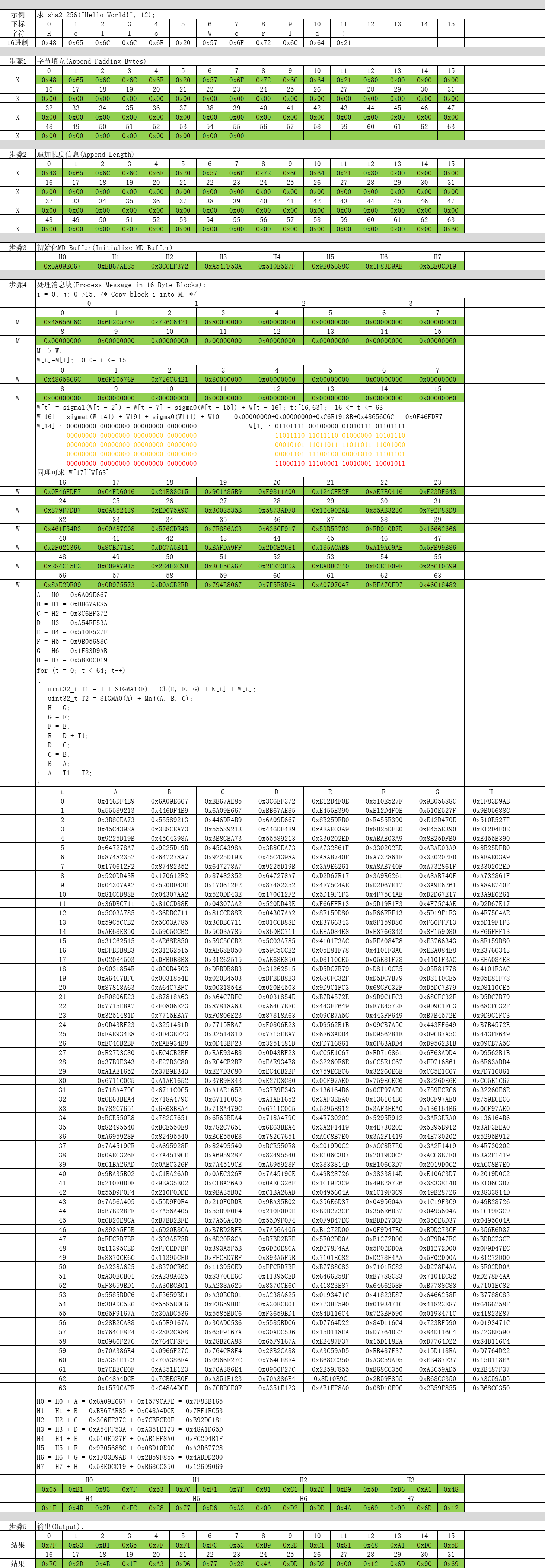
以下为C/C++代码实现:
#include <string.h>
#include <stdio.h>
#define HASH_BLOCK_SIZE 64 /* 512 bits = 64 bytes */
#define HASH_LEN_SIZE 8 /* 64 bits = 8 bytes */
#define HASH_LEN_OFFSET 56 /* 64 bytes - 8 bytes */
#define HASH_DIGEST_SIZE 16 /* 128 bits = 16 bytes */
#define HASH_ROUND_NUM 64
typedef unsigned char uint8_t;
typedef unsigned short int uint16_t;
typedef unsigned int uint32_t;
typedef unsigned long long uint64_t;
/* SHA256 Constants */
static const uint32_t K[HASH_ROUND_NUM] = {
0x428A2F98, 0x71374491, 0xB5C0FBCF, 0xE9B5DBA5,
0x3956C25B, 0x59F111F1, 0x923F82A4, 0xAB1C5ED5,
0xD807AA98, 0x12835B01, 0x243185BE, 0x550C7DC3,
0x72BE5D74, 0x80DEB1FE, 0x9BDC06A7, 0xC19BF174,
0xE49B69C1, 0xEFBE4786, 0x0FC19DC6, 0x240CA1CC,
0x2DE92C6F, 0x4A7484AA, 0x5CB0A9DC, 0x76F988DA,
0x983E5152, 0xA831C66D, 0xB00327C8, 0xBF597FC7,
0xC6E00BF3, 0xD5A79147, 0x06CA6351, 0x14292967,
0x27B70A85, 0x2E1B2138, 0x4D2C6DFC, 0x53380D13,
0x650A7354, 0x766A0ABB, 0x81C2C92E, 0x92722C85,
0xA2BFE8A1, 0xA81A664B, 0xC24B8B70, 0xC76C51A3,
0xD192E819, 0xD6990624, 0xF40E3585, 0x106AA070,
0x19A4C116, 0x1E376C08, 0x2748774C, 0x34B0BCB5,
0x391C0CB3, 0x4ED8AA4A, 0x5B9CCA4F, 0x682E6FF3,
0x748F82EE, 0x78A5636F, 0x84C87814, 0x8CC70208,
0x90BEFFFA, 0xA4506CEB, 0xBEF9A3F7, 0xC67178F2
};
/* Swap bytes in 32 bit value. 0x01234567 -> 0x67452301 */
#define __bswap_32(x) \
((((x) & 0xff000000) >> 24) \
| (((x) & 0x00ff0000) >> 8) \
| (((x) & 0x0000ff00) << 8) \
| (((x) & 0x000000ff) << 24))
static uint32_t Ch(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) ^ ((~X) & Z);
}
static uint32_t Maj(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) ^ (X & Z) ^ (Y & Z);
}
/* 循环向右移动offset个比特位 */
static uint32_t ROTR(uint32_t X, uint8_t offset)
{
uint32_t res = (X >> offset) | (X << (32 - offset));
return res;
}
/* 向右移动offset个比特位 */
static uint32_t SHR(uint32_t X, uint8_t offset)
{
uint32_t res = X >> offset;
return res;
}
/* SIGMA0 */
static uint32_t SIGMA0(uint32_t X)
{
return ROTR(X, 2) ^ ROTR(X, 13) ^ ROTR(X, 22);
}
/* SIGMA1 */
static uint32_t SIGMA1(uint32_t X)
{
return ROTR(X, 6) ^ ROTR(X, 11) ^ ROTR(X, 25);
}
/* sigma0, different from SIGMA0 */
static uint32_t sigma0(uint32_t X)
{
uint32_t res = ROTR(X, 7) ^ ROTR(X, 18) ^ SHR(X, 3);
return ROTR(X, 7) ^ ROTR(X, 18) ^ SHR(X, 3);
}
/* sigma1, different from SIGMA1 */
static uint32_t sigma1(uint32_t X)
{
return ROTR(X, 17) ^ ROTR(X, 19) ^ SHR(X, 10);
}
#define ASSERT_RETURN_INT(x, d) if(!(x)) { return d; }
int sha2_256(unsigned char *out, const unsigned char* in, const int inlen)
{
ASSERT_RETURN_INT(out && in && (inlen >= 0), 1);
int i = 0, j = 0, t = 0;
// step 1: 字节填充(Append Padding Bytes)
// 数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数
int iX = inlen / HASH_BLOCK_SIZE;
int iY = inlen % HASH_BLOCK_SIZE;
iX = (iY < HASH_LEN_OFFSET) ? iX : (iX + 1);
int iLen = (iX + 1) * HASH_BLOCK_SIZE;
unsigned char* X = malloc(iLen);
memcpy(X, in, inlen);
// 先补上1个1比特+7个0比特
X[inlen] = 0x80;
// 再补上(k-7)个0比特
for (i = inlen + 1; i < (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET); i++)
{
X[i] = 0;
}
// step 2: 追加长度信息(Append Length)
uint8_t *pLen = (uint64_t*)(X + (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET));
uint64_t iTempLen = inlen << 3;
uint8_t *pTempLen = &iTempLen;
pLen[0] = pTempLen[7]; pLen[1] = pTempLen[6]; pLen[2] = pTempLen[5]; pLen[3] = pTempLen[4];
pLen[4] = pTempLen[3]; pLen[5] = pTempLen[2]; pLen[6] = pTempLen[1]; pLen[7] = pTempLen[0];
// Step 3. 初始化MD Buffer(Initialize MD Buffer)
uint32_t H0 = 0x6A09E667;
uint32_t H1 = 0xBB67AE85;
uint32_t H2 = 0x3C6EF372;
uint32_t H3 = 0xA54FF53A;
uint32_t H4 = 0x510E527F;
uint32_t H5 = 0x9B05688C;
uint32_t H6 = 0x1F83D9AB;
uint32_t H7 = 0x5BE0CD19;
uint32_t M[HASH_BLOCK_SIZE / 4] = { 0 };
uint32_t W[HASH_ROUND_NUM] = { 0 };
// step 4: 处理消息块(Process Message in 64-Byte Blocks)
for (i = 0; i < iLen / HASH_BLOCK_SIZE; i++)
{
/* Copy block i into M. */
for (j = 0; j < HASH_BLOCK_SIZE; j = j + 4)
{
uint64_t k = i * HASH_BLOCK_SIZE + j;
M[j / 4] = (X[k] << 24) | (X[k + 1] << 16) | (X[k + 2] << 8) | X[k + 3];
}
/* W[t]=M[t]; t:[0,15] */
for (t = 0; t <= 15; t++)
{
W[t] = M[t];
}
/* W[t] = sigma1(W[t - 2]) + W[t - 7] + sigma0(W[t - 15]) + W[t - 16]; t:[16,63] */
for (t = 16; t < HASH_ROUND_NUM; t++)
{
W[t] = sigma1(W[t - 2]) + W[t - 7] + sigma0(W[t - 15]) + W[t - 16];
}
uint32_t A = H0;
uint32_t B = H1;
uint32_t C = H2;
uint32_t D = H3;
uint32_t E = H4;
uint32_t F = H5;
uint32_t G = H6;
uint32_t H = H7;
for (t = 0; t < HASH_ROUND_NUM; t++)
{
uint32_t T1 = H + SIGMA1(E) + Ch(E, F, G) + K[t] + W[t];
uint32_t T2 = SIGMA0(A) + Maj(A, B, C);
H = G;
G = F;
F = E;
E = D + T1;
D = C;
C = B;
B = A;
A = T1 + T2;
//printf("t=%02d:\t 0x%02X\t\t 0x%02X\t\t 0x%02X\t\t 0x%02X\t\t \n", t, E, F, G, H);
}
H0 = H0 + A;
H1 = H1 + B;
H2 = H2 + C;
H3 = H3 + D;
H4 = H4 + E;
H5 = H5 + F;
H6 = H6 + G;
H7 = H7 + H;
}
// step 5: 输出
uint32_t* pOut = (uint8_t*)out;
pOut[0] = __bswap_32(H0);
pOut[1] = __bswap_32(H1);
pOut[2] = __bswap_32(H2);
pOut[3] = __bswap_32(H3);
pOut[4] = __bswap_32(H4);
pOut[5] = __bswap_32(H5);
pOut[6] = __bswap_32(H6);
pOut[7] = __bswap_32(H7);
free(X);
return 0;
}
int main()
{
unsigned char digest[32] = { 0 };
sha2_256(digest, "Hello World!", strlen("Hello World!"));
return 0;
}原文来自
原文来自
CRC的全称为 Cyclic Redundancy Check,中文名称为循环冗余校验。它是一类重要的线性分组码,编码和解码方法简单,检错和纠错能力强,在通信领域广泛地用于实现差错控制。
实际上,除数据通信外,CRC在其它很多领域也是大有用武之地的。例如我们读软盘上的文件,以及解压一个ZIP文件时,偶尔会碰到“Bad CRC”错误,由此它在数据存储方面的应用可略见一斑。
一个数n与0进行与运算,值为0,n & 0 = 0。
一个数n与-1进行与运算,值为n,n & -1 = n。
一个数n与自己进行与运算,值为n,n & n = n。
一个数n与0进行或运算,值为n,n | 0 = n。
一个数n与-1进行或运算,值为-1,n | -1 = -1。
对二进制的每一位都按位取反。
对于数n,n + (~n) = -1。
运算的二进位结果,相异为1,相同为0。
一个数n与0异或,值为n,n ^ 0 = n。
一个数n与-1异或,值为~n,n ^ -1 = ~n。
一个数n与自己异或,值为0,n ^ n = 0。
向左进行移位操作,高位丢弃,低位补 0
向右进行移位操作,对无符号数,高位补 0,对于有符号数,高位补符号位
r = (a + b) >> 1
>> 1 ,相当于 除 2。
C语言中的位域定义:
struct Bits{
uint32_t b2:2;
uint32_t b4:4;
};提取位域定义的值算法如下:
mask = (1 << w) - 1
tv = v >> p
v = tv & mask
r = (v >> p) & ( (1 << w) - 1)
如果v是有符号数,就需要进行符号扩展。
smask = 1 << (w-1)
signed = r & smask
signed != 0 ? ( r = r | (-1 « w) ) : r
( (1 « (w-1)) & r) != 0 ? ( r = r | (-1 « w) ) : r
假设您有一个 32 位系统:
0 和 1 分别位于最高有效位位置,分别表示符号位。
计算INT_MAX和INT_MIN 在 C/C++ 中: 数字 0 表示为 000…000(32个)。
我们计算 0 的 NOT 得到一个有 32 个 1 的数字。这个数字不等于INT_MAX因为符号位是1,即负数。 现在,这个数字的右移将产生011…111 这是INT_MAX。 将INT_MAX 按位取反 就得到INT_MIN。
unsigned int max = 0;
max = ~max;
max = max >> 1;
int min = ~max;
设整数 n 类型为 int_8,值为 3,则 3 + (~3) = 0000 0011 + 1111 1100 = 1111 1111 = -1,所以引出非运算的基础公式 n + (~n) = -1,也可以将 n ^ -1 = ~n 带入。
对n + (~n) = -1进行等式变换可得:
int n;
~n = -(n + 1);
n + 1 = -~n;
n - 1 = ~-n; // 假设n = -n,可推出此等式
一个数的相反数等于其按位取反后再加1,对上等式变换推出:
int n;
-n = ~n + 1;这一块内容也用到了n ^ 0 = n 和 n ^ -1 = ~n:
int abs, n;
abs = (n ^ (n >> 31)) - (n >> 31)不需要第三个临时变量,交换两个数的值
int a, b;
a ^= b; // a = a ^ b;
b ^= a; // b = b ^ a = b ^ a ^ b = (b ^ b) ^ a = 0 ^ a = a
a ^= b; // a = a ^ b = a ^ a ^ b = 0 ^ b = b
如果 x = a,则 a ^ b ^ x = 0 ^ b;如果 x = b,则 a ^ b ^ x = 0 ^ a;
所以下列代码可等价于:x = a ^ b ^ x。
int a, b, x;
if(x == a)
x = b;
else if(x == b)
x = a;
// 上面代码等价于
x = a ^ b ^ xx&(x-1)可以消除数字x二进制表示的最后一个1,如:
int x = 0xf6;
printf("%x\n", x); //0b11110110
printf("%x\n", x&(x-1)); //0b11110100
如果一个正数是2的次幂,则这个数的二进制表示中只含有一个1。
int x;
if(x&(x-1)){
//x至少含有两个1,所以不是2的次幂
}
x中的最后一个1可以通过操作x = x&(x-1)循环消去,当最后x值为0时,便可以求出二进制中1的个数。
int x, total;
while(x > 0){
x = x&(x-1);
total++;
}整数 n 向右移一位,相当于将 n 除以 2;数 n 向左移一位,相当于将 n 乘以 2。
int n = 2;
n >> 1; // 1
n << 1; // 4
m 是2的次方,则其二进制数只有一个1,如 4 => 0100,8 => 1000。m-1 之后,原本 m 二进制的1变成0,原本1后面的0全变成1,如 4-1 = 3 => 0011,8-1 = 7 => 0111。
2 ^ 0 = 1
2 ^ 1 = 2
2 ^ 2 = 4
2^ 3 = 8
2 ^ 4 = 16
2 ^ 5 = 32
…
可以看出 2^(q + 1) 永远都是 2^q 的整数倍,而 2^q 比 2^(q - 1)+2^(q - 2) … + 2^0 的和还要大 1。
假设 m = 2^q ,q 为正整数。n 的二进制数中,第[ n 的最高位, q ]位的和是 m 的整数倍,而第[ q-1, 0 ]位的和是 n/m 的余数,也就是说将n的二进制数的第[ q-1, 0 ]位截取,即可得到 n/m 的余数。
m = 2^q , m − 1 = 2^(q - 1)+2^(q - 2) … + 2^0 => 00011…1([ q-1, 0 ]位全为1),所以 n & (m - 1) 的值为 n/m 的余数。
int mod, n, m; // m是2的次方,如4,8等
mod = n & (m - 1);有 n 和 m 两数,m 为2的次方,找到大于等于 n 且正好是 m 整数倍的最小数。
假设 m = 2^q ,则 m 的倍数的二进制数中,第 q 位为1,其余位全为 0;(m - 1) 的二进制数中[ q-1, 0 ]位全为 1,其余位全为 0。
所以有两种情况:
现给 n 加上一个[ q-1, 0 ]位全为 1,其余位全为 0 的数( m-1 就是这个数),并将所得结果的[ q-1, 0 ]位全部置为 0(结果与 ~(m - 1) 相与即可),便可满足这两种情况。
int min, n, m;
min = (n + m - 1) & ~(m - 1);int max(int a, int b){
return (b & ((a - b) >> 31)) | (a & (~(a - b) >> 31));
}
int min(int a, int b){
return (a & ((a - b) >> 31)) | (b & (~(a - b) >> 31));
}以32位整数为例,循环左移的过程可以分为3步:
以32位整数为例,循环右移的过程可以分为3步:
假如将一个无符号的数据 val ,长度为 N bit,需要循环移动 n bit。可以利用下面的公式:
循环左移:(val >> (N - n) | (val << n))
循环右移:(val << (N - n) | (val >> n))
//循环左移
unsigned int ROL(unsigned int val,unsigned int n){
n&=31;
return (val >> (32 - n) | (val << n));
}
//循环右移
unsigned int ROL(unsigned int val,unsigned int n){
n&=31;
return (val << (32 - n) | (val >> n));
}