demo 的子部分
8.1 异步支持方案
功能示意图
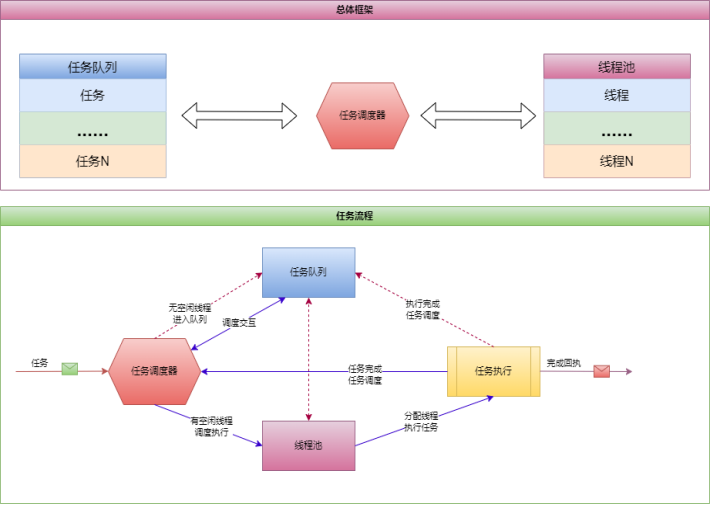
总体框架
线程池是一种可重用线程池,用于执行一系列的任务,而不需要创建和销毁新的线程。异步方案可采用线程池技术,可以将线程池的线程用于执行非阻塞任务,这些任务不需要等待当前线程完成。这种技术可以提高系统的并发性和性能。
线程池的总体框架由三部分组成:任务队列、线程池、任务调度器。
- 任务队列是线程池的核心组成部分,它用于存储和管理任务。任务队列的大小和类型决定了线程池的规模和性能。
- 线程池是任务队列的执行者,它用于执行任务队列中的任务。线程池的大小和类型决定了任务队列的大小和性能。
- 任务调度器是线程池的管理者,它用于控制任务的执行顺序和优先级。任务调度器可以根据任务的优先级和状态来安排线程池中的线程执行任务,从而提高任务的执行效率和并发性。
线程池的总体框架中,任务队列是核心组成部分,它直接决定了线程池的性能和规模。任务队列的大小和类型应该根据实际情况进行选择,以保证线程池的性能和可扩展性。
线程池的大小和类型也应该根据实际情况进行选择,以保证任务队列的大小和性能。任务调度器是线程池的管理者,它应该根据实际情况进行选择,以保证任务的执行顺序和优先级。
线程池的总体框架是一个复杂的系统,需要仔细地设计和实现。在设计和实现线程池时,需要充分考虑各个组成部分之间的关系和依赖性,以保证系统的稳定性和可靠性。
任务调度
任务调度是线程池的核心组成部分之一,它用于控制任务的执行顺序和优先级。任务调度的思想算法通常分为两种:先进先出(FIFO)和优先级调度。
先进先出(FIFO)是最简单的任务调度算法之一,它的思想是按照任务提交的顺序依次执行任务。具体来说,线程池中的任务按照顺序进入任务队列,然后按照顺序从任务队列中取出任务进行执行。先进先出的任务调度算法可以保证每个任务都有机会被执行,但是它无法根据任务的优先级来安排任务的执行顺序,可能会导致低优先级的任务长时间被阻塞,从而影响系统的性能和并发性。
优先级调度是一种更加高效的任务调度算法,它的思想是根据任务的优先级来安排任务的执行顺序。具体来说,线程池中的任务可以被标记为高、中、低三种优先级,然后根据任务的优先级来安排任务的执行顺序。高优先级的任务优先执行,低优先级的任务后执行。优先级调度可以保证高优先级的任务得到更快的执行,从而提高系统的性能和并发性。但是,优先级调度算法也存在一些问题,例如高优先级的任务可能会导致线程池的占用率过高,从而影响系统的性能和稳定性。
因此,在实际应用中,任务调度算法的选择应该根据具体的场景和需求来确定。如果任务的执行顺序对系统的性能和并发性影响较大,可以选择优先级调度算法。如果任务的执行顺序对系统的性能和并发性影响较小,可以选择先进先出的任务调度算法。同时,需要注意任务的优先级应该合理设置,以避免任务之间的冲突和竞争。
优先级调度算法
优先级调度算法是一种根据任务的优先级来安排任务的执行顺序的任务调度算法。
在实际应用中,可以使用一个优先级队列来存储任务,并使用一个优先级栈来存储任务的优先级。
- 任务进入任务队列时,将任务的优先级加入到优先级队列中。
- 线程空闲时,从优先级队列中取出优先级最高的任务,并将其执行。
- 执行完任务后,将任务的优先级从优先级栈中移除,以便在后续的执行中,其他任务可以优先执行。
优先级方案
通常分为两种:
硬编码优先级:硬编码优先级是最简单的优先级确定方案之一,它将任务的优先级直接硬编码在代码中。例如,可以将低优先级的任务的优先级设置为1,中优先级的任务的优先级设置为2,高优先级的任务的优先级设置为3。这种方案的优点是实现简单,易于理解和调试。但是,缺点是当任务数量增多时,需要频繁地修改硬编码的优先级,不够灵活。
动态调整优先级:动态调整优先级是一种更加灵活的优先级确定方案,它可以根据任务的具体需求来动态调整任务的优先级。例如,可以根据任务的重要性、紧急程度、完成时间等因素来确定任务的优先级。这种方案的优点是灵活性强,可以根据具体的需求来动态调整任务的优先级。但是,缺点是需要更多的计算和调试工作,实现起来相对复杂。
在实际应用中,可以根据具体的需求和场景来选择合适的优先级确定方案。
如果任务的优先级比较明确,可以选择硬编码优先级的方案。
如果任务的优先级比较复杂,可以选择动态调整优先级的方案。
同时,需要注意在动态调整优先级时,需要保证优先级的分配合理,避免出现优先级冲突和竞争的问题。
动态调整优先级
动态调整优先级是一种更加灵活的优先级确定方案,它可以根据任务的具体需求来动态调整任务的优先级。
以下是一些常见的动态调整优先级的方案:
优先级堆:优先级堆是一种常见的动态调整优先级的方案。在优先级堆中,任务被赋予一个优先级值,并按照优先级从高到低排序。线程池中的线程从优先级堆中取出优先级最高的任务进行执行。如果有多个任务具有相同的优先级,可以根据任务的创建时间或执行时间等因素来确定优先级。
贪心算法:贪心算法是一种常见的动态调整优先级的方案。在贪心算法中,每次从任务队列中取出一个任务进行执行,并根据任务的状态来更新任务的优先级。如果任务已经完成,可以将其优先级降低;如果任务还未完成,可以将其优先级升高。这种方案的优点是实现简单,易于理解和调试。但是,缺点是可能会导致低优先级的任务长时间被阻塞,从而影响系统的性能和并发性。
模拟器算法:模拟器算法是一种常见的动态调整优先级的方案。在模拟器算法中,任务被赋予一个优先级值,并按照优先级从高到低排序。线程池中的线程从任务队列中取出优先级最高的任务进行执行。如果有多个任务具有相同的优先级,可以根据任务的状态来确定优先级。在模拟器算法中,需要维护一个状态表,记录任务的状态和优先级。每次执行任务时,根据任务的状态更新任务的优先级。
推荐方案
基于优先级和等待时长的方案是一种常见的动态调整优先级的方案。
在这种方案中,任务被赋予一个优先级值和一个等待时长值,并按照优先级从高到低排序。线程池中的线程从任务队列中取出优先级最高的任务进行执行。
如果有多个任务具有相同的优先级,可以根据等待时长来确定优先级。
具体来说,可以定义一个等待时长值,表示任务等待执行的时间长度。在任务进入任务队列时,将其优先级和等待时长值加入到任务的信息中。
当线程池中的线程空闲时,从任务队列中取出优先级最高的任务进行执行。执行完任务后,将任务的信息从任务队列中移除。
如果任务等待的时间超过了其等待时长值,可以将其优先级降低。这样可以保证优先级较高的任务尽快得到执行,并且可以减少等待时间长的任务对系统的影响。
需要注意的是,在实际应用中,等待时长值的设置需要根据具体的场景和需求来确定。
等待时长值过小可能会导致任务执行时间不够准确,等待时长值过大可能会导致任务无法及时得到执行。
因此,在设置等待时长值时,需要进行充分的测试和评估,以保证系统的稳定性和性能。
案列代码
#include <pthread.h>
#include <cstdint>
#include <list>
#include <memory>
#include <atomic>
#include <unistd.h>
//--------------------模型抽象----------------------
// 任务基类
struct ITask
{
// 任务处理入口
virtual void handling() {}
ITask() : mInit(0), mTrue(0) {}
private:
friend struct Scheduler;
uint16_t mInit; // 初始优先级
uint16_t mTrue; // 调度过程中的真实优先级
};
using TaskRef = std::shared_ptr<ITask>;
// 任务调度
struct Scheduler
{
Scheduler();
void lock() { pthread_mutex_lock(&mMutex); }
void unlock() { pthread_mutex_unlock(&mMutex); }
void wait() { pthread_cond_wait(&mCond, &mMutex); }
void notify() { pthread_cond_broadcast(&mCond); }
void stop() { mQuit = true; }
void onstop() { mStopCnt.fetch_add(1); }
void join()
{
while (true)
{
if (mList.empty())
stop();
if (mStopCnt.load() >= 3)
break;
notify();
// sleep(10);
}
}
void addTask(TaskRef task, uint16_t init)
{
// lock();
task->mInit = init;
task->mTrue = init;
mList.push_back(task);
// unlock();
}
bool getTask(TaskRef &task)
{
if (mList.empty() == false)
{
task = mList.front();
mList.pop_front();
for (auto &item : mList)
++item->mTrue; // 更新优先级
return true;
}
return false;
}
private:
std::list<TaskRef> mList; // 任务链表
volatile bool mQuit = false;
// pthread_spinlock_t mSpin; // 调度自旋锁
pthread_mutex_t mMutex;
pthread_cond_t mCond;
pthread_t threads[3];
volatile std::atomic_int32_t mStopCnt;
static void *worker(void *userpoint);
};
Scheduler::Scheduler()
{
mStopCnt = 0;
pthread_attr_t attr;
/* Initialize mutex and condition variable objects */
pthread_mutex_init(&mMutex, NULL);
pthread_cond_init(&mCond, NULL);
/* For portability, explicitly create threads in a joinable state */
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
pthread_create(&threads[0], &attr, worker, this);
pthread_create(&threads[1], &attr, worker, this);
pthread_create(&threads[2], &attr, worker, this);
}
void *Scheduler::worker(void *userpoint)
{
TaskRef task;
Scheduler &domain = *(Scheduler *)userpoint;
while (true)
{
task.reset();
domain.lock();
if (domain.getTask(task) == false)
{
domain.wait();
}
domain.unlock();
if (task.get() != nullptr)
task->handling();
// 判断是否销毁线程池
if (domain.mQuit == true)
break;
}
domain.onstop();
printf("线程[%d] 退出!\n",pthread_self());
return nullptr;
}
//-----------------------------------------测试----------------------------------
struct TaskA : public ITask
{
TaskA(int id, int serial) : mID(id), mSerial(serial) {}
int mID, mSerial;
void handling() override
{
printf("%d: int32 serial number = %d\n", mID, mSerial);
}
};
struct TaskB : public ITask
{
TaskB(int id, float serial) : mID(id), mSerial(serial) {}
int mID;
float mSerial;
void handling() override
{
printf("%d: float serial number = %f\n", mID, mSerial);
}
};
template <typename type, typename... arg>
TaskRef maketask(arg... args)
{
auto tsk = new type(args...);
auto ref = std::make_shared<ITask>();
ref.reset(tsk);
return ref;
}
int main(int argc, char *argv[])
{
Scheduler domain;
int id = 0;
while (true)
{
domain.lock();
domain.addTask(maketask<TaskA>(++id, id * 10), id % 6);
domain.addTask(maketask<TaskA>(++id, id * 100), id % 6);
domain.addTask(maketask<TaskA>(++id, id * 1000), id % 6);
domain.addTask(maketask<TaskB>(++id, id * 3.14159), id % 6);
domain.addTask(maketask<TaskB>(++id, id * 18.2345), id % 6);
domain.addTask(maketask<TaskB>(++id, id * 32.4568), id % 6);
domain.unlock();
domain.notify();
if (id > 100)
break;
}
// domain.stop();
domain.join();
printf("任务全部处理完成\n");
return 0;
}注意事项
实际开发的过程中要使用锁等同步机制。
8.2 深入理解引用计数:原理、实现与应用
在现代编程中,尤其是在处理动态内存管理和对象生命周期控制方面,引用计数是一种极为重要的技术。它为我们提供了一种高效且相对直观的方式来管理对象的创建与销毁,确保资源在不再被使用时能够被正确地释放,避免内存泄漏等问题的发生。本文将深入探讨引用计数的相关知识,并结合一段具体的代码实现来详细解析其工作原理和实际应用场景。
代码未进行运行测试,只是一个原理描述
二、引用计数的基本概念
引用计数的核心思想非常简单:为每个对象维护一个计数器,记录当前有多少个引用指向该对象。当一个新的引用指向对象时,计数器加 1;当一个引用不再指向对象时,计数器减 1。当计数器的值变为 0 时,表示该对象不再被任何引用所指向,此时可以安全地释放该对象所占用的资源。
这种机制的优势在于它能够自动处理对象的生命周期,只要程序员正确地管理引用的增加和减少,就不需要手动去跟踪对象何时应该被销毁。这在复杂的程序结构中,尤其是涉及到对象之间相互引用的情况下,大大降低了内存管理的难度和出错的概率。
三、代码中的引用计数实现
我们来看一段代码示例,它实现了一个包含引用计数和弱引用机制的对象头结构。
(一)对象头结构定义
首先是 ObjectHD 结构体,它作为对象的头部信息,包含了多个重要的成员变量:
struct ObjectHD
{
// 弱引用记录块
struct WeakRefBlk
{
void *mType; // 类型标记
std::atomic<ObjectHD *> mObject; // 对象回访指针
std::atomic_int32_t mWeakRef; // 弱引用计数
std::atomic_flag mSpinlock; // 自旋锁定
};
union
{
WeakRefBlk *mWeakRef;
void *mType; // 类型标记
} mMetaInfo; // 元数据
std::atomic_int32_t mRefCount; // 引用计数
std::atomic_flag mSpinlock; // 自旋锁定
std::atomic_uint8_t mWeakRef; // 存在弱引用
std::atomic_flag mObjlock; // 对象锁
volatile uint8_t arrcols; // 数组维度
};在这个结构中,mRefCount 就是用于记录对象引用计数的变量。mSpinlock 是一个自旋锁,用于在多线程环境下对对象的引用计数操作进行同步,防止并发冲突。WeakRefBlk 结构体则是用于处理弱引用相关信息,包括弱引用计数 mWeakRef 和自旋锁 mSpinlock 等。
(二)引用对象函数 ref_obj
ObjectHD *ref_obj(ObjectHD *objptr)
{
// objref==nullptr 说明本身没有对象,不应该引用
while (objptr!= nullptr)
{
ObjectHD &obj = *objptr;
// 尝试加锁
auto old = obj.mSpinlock.test_and_set();
// 已被锁定
if (old == true)
{
// 可以睡眠一下:后再循环中继续尝试
std::this_thread::sleep_for(std::chrono::microseconds(1));
continue;
}
// 已经加锁成功,进行引用操作
obj.mRefCount.fetch_add(1);
// 解锁
obj.mSpinlock.clear();
// sizeof(std::atomic_flag);
}
return objptr;
}这个函数用于增加对象的引用计数。它首先检查传入的对象指针是否为空,如果不为空,则尝试获取对象的自旋锁。如果锁已经被其他线程获取(old == true),则当前线程睡眠一小段时间后再次尝试获取锁。一旦成功获取锁,就使用 fetch_add 原子操作将引用计数加 1,然后释放锁并返回对象指针。
(三)解引用函数 unref_obj
ObjectHD *unref_obj(ObjectHD *objptr)
{
// objref==nullptr 说明本身没有对象,不应该引用
while (objptr!= nullptr)
{
ObjectHD &obj = *objptr;
// 尝试加锁
auto old = obj.mSpinlock.test_and_set();
// 已被锁定
if (old == true)
{
// 可以睡眠一下:后再循环中继续尝试
std::this_thread::sleep_for(std::chrono::microseconds(1));
continue;
}
// 已经加锁成功,进行引用操作
obj.mRefCount.fetch_sub(1);
// 引用计数为0,可以释放对象了
if (obj.mRefCount.load() == 0)
{
// 判断是否有弱引用
if (obj.mWeakRef!= 0)
{
// 先对弱引用计数块加锁
while (obj.mMetaInfo.mWeakRef->mSpinlock.test_and_set() == true)
;
obj.mMetaInfo.mWeakRef->mObject->store(nullptr);
// 解锁
obj.mMetaInfo.mWeakRef->mSpinlock.clear();
}
delete objptr;
}
// 解锁
obj.mSpinlock.clear();
// sizeof(std::atomic_flag);
}
return objptr;
}unref_obj 函数用于减少对象的引用计数。与 ref_obj 类似,它先获取对象的自旋锁,然后使用 fetch_sub 原子操作将引用计数减 1。如果引用计数减为 0,说明该对象不再被引用,此时需要进一步检查是否存在弱引用。如果存在弱引用,则先对弱引用计数块加锁,将弱引用指向的对象指针设置为空,然后解锁弱引用计数块,最后释放对象本身。
四、弱引用与引用计数的关系
在上述代码中,还涉及到了弱引用的相关操作。弱引用是一种特殊的引用类型,它不会影响对象的引用计数。弱引用主要用于解决对象之间相互引用导致的循环引用问题。例如,对象 A 引用对象 B,同时对象 B 又引用对象 A,如果仅仅使用普通的引用计数,这两个对象的引用计数将永远不会变为 0,从而导致内存泄漏。而弱引用允许对象之间存在这种相互引用关系,同时又不会阻止对象在其他强引用都消失时被正确地释放。
(一)从引用对象中记录弱引用计数函数 weak_ref_form_refobj
ObjectHD::WeakRefBlk *weak_ref_form_refobj(ObjectHD *objptr)
{
ObjectHD::WeakRefBlk *blk = nullptr;
// objref==nullptr 说明本身没有对象,不应该引用
while (objptr!= nullptr)
{
ObjectHD &obj = *objptr;
// 尝试加锁
auto old = obj.mSpinlock.test_and_set();
// 已被锁定
if (old == true)
{
// 可以睡眠一下:后再循环中继续尝试
std::this_thread::sleep_for(std::chrono::microseconds(10));
continue;
}
// 已经加锁成功,进行引用操作
{
// 当前还不存在弱引用,所以该该建立弱引用,分配弱引用记录快
if (obj.mWeakRef == 0)
{
auto type = obj.mMetaInfo.mType;
obj.mMetaInfo.mWeakRef = new ObjectHD::WeakRefBlk();
obj.mMetaInfo.mWeakRef->mType = type;
obj.mMetaInfo.mWeakRef->mObject->store(objptr);
obj.mMetaInfo.mWeakRef->mWeakRef = 1;
obj.mMetaInfo.mWeakRef->mSpinlock.clear();
obj.mWeakRef = 1;
}
// 已经存在弱引用
else
{
// 先对弱引用计数块加锁
while (obj.mMetaInfo.mWeakRef->mSpinlock.test_and_set() == true)
;
obj.mMetaInfo.mWeakRef->mWeakRef++;
// 解锁
obj.mMetaInfo.mWeakRef->mSpinlock.clear();
}
blk = obj.mMetaInfo.mWeakRef;
}
// 解锁
obj.mSpinlock.clear();
}
return blk;
}这个函数用于从一个强引用对象中创建或更新弱引用计数。如果对象当前不存在弱引用,则创建一个新的 WeakRefBlk 结构体,初始化其相关成员变量,并将对象的 mWeakRef 标记设置为 1。如果已经存在弱引用,则对弱引用计数块加锁后将弱引用计数加 1。
(二)从弱引用对象中记录弱引用计数函数 weak_ref_form_weakobj
ObjectHD::WeakRefBlk *weak_ref_form_weakobj(ObjectHD::WeakRefBlk *weakptr)
{
// 注意弱引用锁的优先级低于对象引用锁
while (weakptr!= nullptr)
{
// 先加锁
auto old = weakptr->mSpinlock.test_and_set();
// 已被加锁
if (old == true)
{
// 可以睡眠一下:后再循环中继续尝试
std::this_thread::sleep_for(std::chrono::microseconds(10));
continue;
}
// 加锁成功,进而给对象加锁
if (weakptr->mObject!= nullptr)
{
auto &obj = *weakptr->mObject->load();
auto old = obj.mSpinlock.test_and_set();
// 对象已经加锁,就重新来过
if (old == true)
{
// 释放锁
weakptr->mSpinlock.clear();
continue;
}
// 加锁成功,引用计数加一
weakptr->mWeakRef++;
// 解锁
obj.mSpinlock.clear();
}
// 释放锁
weakptr->mSpinlock.clear();
}
return weakptr;
}该函数用于从一个弱引用对象中增加弱引用计数。它先获取弱引用对象的自旋锁,如果弱引用指向的对象不为空,则进一步获取对象的自旋锁,然后增加弱引用计数,最后依次释放对象锁和弱引用锁。
(三)释放弱引用函数 unref_weak_obj
void unref_weak_obj(ObjectHD::WeakRefBlk *weakptr)
{
if (weakptr == nullptr)
return;
// 注意弱引用锁的优先级低于对象引用锁
while (true)
{
// 先加锁
auto old = weakptr->mSpinlock.test_and_set();
// 已被加锁
if (old == true)
{
// 可以睡眠一下:后再循环中继续尝试
std::this_thread::sleep_for(std::chrono::microseconds(10));
continue;
}
// 加锁成功,进而给对象加锁
if (weakptr->mObject!= nullptr)
{
auto &obj = *weakptr->mObject->load();
auto old = obj.mSpinlock.test_and_set();
// 对象已经加锁,就重新来过
if (old == true)
{
// 释放锁
weakptr->mSpinlock.clear();
continue;
}
// 加锁成功,弱引用计数-1
weakptr->mWeakRef--;
// 弱引用计数为0,释放弱记录块
if (weakptr->mWeakRef == 0)
{
// 重新恢复对象的meta信息
obj.mMetaInfo.mType = weakptr->mType;
obj.mWeakRef.store(0);
// 释放弱记录块对象
delete weakptr;
return;
}
// 解锁
obj.mSpinlock.clear();
}
// 对象已经被释放
else
{ // 加锁成功,弱引用计数-1
weakptr->mWeakRef--;
// 弱引用计数为0,释放弱记录块
if (weakptr->mWeakRef == 0)
{
// 释放弱记录块对象
delete weakptr;
return;
}
}
// 弱引用记录不为0, 释放锁
weakptr->mSpinlock.clear();
}
}unref_weak_obj 函数用于减少弱引用计数。它先获取弱引用对象的自旋锁,如果弱引用指向的对象存在,则获取对象的自旋锁,然后减少弱引用计数。如果弱引用计数变为 0,则恢复对象的元数据信息,将对象的 mWeakRef 标记设置为 0,并释放弱引用记录块对象。
(四)获取对象函数 get_obj_from_weakobj
ObjectHD *get_obj_from_weakobj(ObjectHD::WeakRefBlk *weakptr)
{
ObjectHD *ret = nullptr;
// 注意弱引用锁的优先级低于对象引用锁
while (weakptr!= nullptr)
{
// 先加锁
auto old = weakptr->mSpinlock.test_and_set();
// 已被加锁
if (old == true)
{
// 可以睡眠一下:后再循环中继续尝试
std::this_thread::sleep_for(std::chrono::microseconds(10));
continue;
}
// 加锁成功,进而给对象加锁
if (weakptr->mObject!= nullptr)
{
auto &obj = *weakptr->mObject->load();
auto old = obj.mSpinlock.test_and_set();
// 对象已经加锁,就重新来过
if (old == true)
{
// 释放锁
weakptr->mSpinlock.clear();
continue;
}
// 加锁成功,引用计数加一
weakptr->mWeakRef++;
// 解锁
obj.mSpinlock.clear();
}
// 释放锁
weakptr->mSpinlock.clear();
}
return ret;
}这个函数用于从弱引用对象中获取所指向的对象。它的操作过程与增加弱引用计数类似,先获取弱引用对象的自旋锁,如果弱引用指向的对象存在,则获取对象的自旋锁并增加弱引用计数,最后返回获取到的对象指针(在示例代码中返回值始终为 nullptr,可能是代码尚未完整实现获取对象的逻辑)。
五、多线程环境下的考虑
在多线程环境中,对引用计数和弱引用计数的操作必须是线程安全的。上述代码中使用自旋锁来实现这一点。自旋锁的特点是当线程获取锁失败时,不会立即进入睡眠状态,而是在一个循环中不断尝试获取锁,这样可以减少线程上下文切换的开销。但是,如果自旋时间过长,也会浪费 CPU 资源。因此,在代码中还设置了睡眠等待的逻辑,当自旋一定时间后仍然无法获取锁时,线程会睡眠一小段时间后再次尝试。
例如在 ref_obj、unref_obj 等函数中,都先尝试获取自旋锁,如果锁已经被占用,则根据情况进行睡眠等待,然后再次尝试获取锁,以确保在多线程并发访问对象引用计数和弱引用计数时的正确性和一致性。
六、总结
引用计数是一种强大的内存管理技术,通过对对象引用数量的精确跟踪,能够有效地管理对象的生命周期,避免内存泄漏等问题。在本文所分析的代码中,不仅展示了基本的引用计数实现,还结合了弱引用机制来处理复杂的对象引用关系,并且充分考虑了多线程环境下的同步问题。深入理解引用计数及其相关的弱引用、多线程同步等知识,对于编写高效、稳定且内存安全的程序具有极为重要的意义。无论是在开发大型应用程序还是在深入研究编程语言的底层机制时,引用计数都是一个不可或缺的重要概念。希望通过本文的介绍,读者能够对引用计数有更深入的理解,并能够在实际编程中灵活运用。