主页 的子部分
1 编程日常
目录
编程日常 的子部分
1.1 网站收藏
文件格式相关
算法相关
- 加解密算法: https://www.cnblogs.com/Kingfans/category/2198205.html
- 快速位运算算法: http://graphics.stanford.edu/~seander/bithacks.html
x86/x64指令相关
- x86-64的指令编码入门: https://blog.csdn.net/JimFire/article/details/112652145
- x86_64指令编码方式: https://zhuanlan.zhihu.com/p/464774687
- X86 Opcode and Instruction Reference: http://ref.x86asm.net/geek64.html
- X86-64_Instruction_Encoding: https://wiki.osdev.org/X86-64_Instruction_Encoding
游戏引擎相关
网络相关
设计模式
他人博客
Ffmpeg
计算机图形学
- easy vulkan: easyvulkan
- learn opengl:https://learnopengl.com/
- learn opengl中文版:https://learnopengl-cn.github.io/
Linux
- C/C(++)获取可执行程序完整路径:使用
readlink函数和/proc/self/exe符号链接。 - Linux C:获取当前程序名称的三种方式
window
- 自定义窗口标题栏,实现响应贴靠窗口布局:https://learn.microsoft.com/zh-cn/windows/apps/desktop/modernize/apply-snap-layout-menu
编译原理
- dalvik字节码:https://source.android.google.cn/docs/core/runtime/dalvik-bytecode?hl=zh-cn
- 北大编译实践在线文档:https://pku-minic.github.io/online-doc/#/
- MiniDecaf 编译器结构:https://decaf-lang.github.io/minidecaf-tutorial/docs/step1/arch.html
- 反汇编利器:https://godbolt.org/
- 解析技术:https://parsing-techniques.duguying.net/
其他
1.2 Ffmpeg 学习笔记
基本概念
ffmpeg 是一个用于处理视频、音频、图片等多媒体文件的工具。
ffmpeg 的主要功能有:
- 音视频格式转换
- 音视频编码
- 音视频裁剪
- 音视频混音
- 音视频转码
- 音视频水印
- 音视频拼接
- 音视频解码
AVPacket
AVPacket 是一个结构体,用于存储一个音频或视频数据包。
一个包里面包含音频或视频数据、时间戳、数据大小等信息。
通常内部包含一个或者多个AVFrame。
AVFrame
AVFrame 是一个结构体,用于存储一个音频或视频帧的数据。
读取基本流程
- 打开文件封装实例
- 查找流信息
- 获取视频流索引
- 查找音频流索引
找到对应的流关联的解码器ID,并分配一个解码器实例,拷贝源文件参数给解码器实例。 这只是打开文件封装实例,后续的解码操作都是基于这个封装实例。
- 打开文件封装实例
AVFormatContext *in_fmt_ctx ;
int ret = avformat_open_input(&in_fmt_ctx, src_name, NULL, NULL);
if (ret < 0) {
av_log(NULL, AV_LOG_ERROR, "Can't open file %s.\n", src_name);
return -1;
}- 查找流信息
ret = avformat_find_stream_info(in_fmt_ctx, NULL);
if (ret < 0) {
av_log(NULL, AV_LOG_ERROR, "Can't find stream information.\n");
return -1;
}- 获取视频流索引
int video_stream_idx = -1;
// 找到视频流的索引
video_stream_idx = av_find_best_stream(in_fmt_ctx, AVMEDIA_TYPE_VIDEO, -1, -1, NULL, 0);
if (video_stream_idx >= 0) {
src_video = in_fmt_ctx->streams[video_stream_idx];
enum AVCodecID video_codec_id = src_video->codecpar->codec_id;
// 查找视频解码器
AVCodec *video_codec = (AVCodec*) avcodec_find_decoder(video_codec_id);
if (!video_codec) {
qCritical() << "video_codec not found" << '\n';
return -1;
}
video_decode_ctx = avcodec_alloc_context3(video_codec); // 分配解码器的实例
if (!video_decode_ctx) {
qCritical() << "video_decode_ctx is null" << '\n';
return -1;
}
// 把视频流中的编解码参数复制给解码器的实例
avcodec_parameters_to_context(video_decode_ctx, src_video->codecpar);
ret = avcodec_open2(video_decode_ctx, video_codec, NULL); // 打开解码器的实例
if (ret < 0) {
qCritical() << "Can't open video_decode_ctx" << '\n';
return -1;
}
}- 查找音频流索引
int audio_stream_idx = -1;
audio_stream_idx = av_find_best_stream(in_fmt_ctx, AVMEDIA_TYPE_AUDIO, -1, -1, NULL, 0);
if (audio_stream_idx >= 0) {
src_audio = in_fmt_ctx->streams[audio_stream_idx];
enum AVCodecID audio_codec_id = src_audio->codecpar->codec_id;
// 查找音频解码器
AVCodec *audio_codec = (AVCodec*) avcodec_find_decoder(audio_codec_id);
if (!audio_codec) {
qCritical() << "audio_codec not found" << '\n';
return -1;
}
audio_decode_ctx = avcodec_alloc_context3(audio_codec); // 分配解码器的实例
if (!audio_decode_ctx) {
qCritical() << "audio_decode_ctx is null" << '\n';
return -1;
}
// 把音频流中的编解码参数复制给解码器的实例
avcodec_parameters_to_context(audio_decode_ctx, src_audio->codecpar);
ret = avcodec_open2(audio_decode_ctx, audio_codec, NULL); // 打开解码器的实例
if (ret < 0) {
qCritical() << "Can't open audio_decode_ctx" << '\n';
return -1;
}
}目录
Ffmpeg 学习笔记 的子部分
2.1 ffmpeg 下载
简介
ffmpeg 是一个跨平台、开源的流媒体处理工具,可以用来转换、剪辑、混合、编码、解码、过滤、转换、播放、录制、分析视频、音频等。
对于初学者,下载已经搭配好的ffmpeg库即可。
学会ffmpeg 相关知识之后,可以自行学习编译ffmpeg。
注意: 编译开源库一般都比较困难,需要一定时间,请耐心等待。
windows 下载
Shift Media Project 旨在为FFmpeg及其相关依赖项提供原生Windows开发库,以支持在Visual Studio中直接更简单地创建和调试丰富媒体内容。
网址:https://shiftmediaproject.github.io
对于初学者,下载已经搭配好的ffmpeg库即可。
demo
下载完成,后可以通过如下代码测试是否成功。
注 编译器为c++ 编译。
#include<stdio.h>
extern "C" {
#include <libavutil/avutil.h>
}
int main(int argc, const char* argv[]) {
av_log(nullptr, AV_LOG_INFO, "FFmpeg version: %s\n", av_version_info());
av_log(nullptr, AV_LOG_INFO, "FFmpeg configuration: %s\n", avutil_configuration());
return 0;
}2.2 查看流信息
说明
本示例演示如何使用 FFmpeg 获取音视频文件的流信息。
示例代码
#include<stdio.h>
extern "C" {
#include <libavformat/avformat.h>
#include <libavutil/avutil.h>
}
int main(int argc, const char* argv[]) {
const char *filename = "F:\\ffmpeg-learn\\test.mp4";
if (argc > 1) {
filename = argv[1];
}
AVFormatContext *fmt_ctx = NULL;
// 打开音视频文件
int ret = avformat_open_input(&fmt_ctx, filename, NULL, NULL);
if (ret < 0) {
av_log(NULL, AV_LOG_ERROR, "Can't open file %s.\n", filename);
return -1;
}
av_log(NULL, AV_LOG_INFO, "Success open input_file %s.\n", filename);
// 查找音视频文件中的流信息
ret = avformat_find_stream_info(fmt_ctx, NULL);
if (ret < 0) {
av_log(NULL, AV_LOG_ERROR, "Can't find stream information.\n");
return -1;
}
av_log(NULL, AV_LOG_INFO, "Success find stream information.\n");
const AVInputFormat* iformat = fmt_ctx->iformat;
av_log(NULL, AV_LOG_INFO, "format name is %s.\n", iformat->name);
av_log(NULL, AV_LOG_INFO, "format long_name is %s\n", iformat->long_name);
av_dump_format(fmt_ctx,0,filename,0);
// 关闭音视频文件
avformat_close_input(&fmt_ctx);
return 0;
}2.3 拷贝音视频文件
说明
本示例演示如何使用 FFmpeg 拷贝 音视频文件。
示例代码
extern "C" {
#include <libavformat/avformat.h>
#include <libavutil/avutil.h>
}
int main(int argc, const char* argv[]) {
const char *src_name = "F:\\ffmpeg-learn\\test.mp4";
if (argc > 1) {
src_name = argv[1];
}
const char *dst_name = "F:\\ffmpeg-learn\\test_copy.mp4";
// 打开文件,获取上下文
AVFormatContext *in_ctx = nullptr;
if( 0>avformat_open_input(&in_ctx, src_name, nullptr, nullptr)){
printf("open file failed:%s\n",src_name);
return -1;
}
printf("open file success:%s\n",src_name);
//找到流
if( 0>avformat_find_stream_info(in_ctx, nullptr)){
printf("find stream info failed!\n");
return -1;
}
// 找到视频流
int video_stream_idx = av_find_best_stream(in_ctx, AVMEDIA_TYPE_VIDEO, -1,-1, nullptr, 0);
if(video_stream_idx < 0){
printf("find video stream failed!\n");
return -1;
}
// 找到音频流
int audio_stream_idx = av_find_best_stream(in_ctx, AVMEDIA_TYPE_AUDIO, -1,-1, nullptr, 0);
if(audio_stream_idx < 0){
printf("find audio stream failed!\n");
return -1;
}
AVStream* video_stream = nullptr;
AVStream* audio_stream = nullptr;
video_stream = in_ctx->streams[video_stream_idx];
audio_stream = in_ctx->streams[audio_stream_idx];
// 创建输出上下文
AVFormatContext *out_ctx = nullptr;
if(0>avformat_alloc_output_context2(&out_ctx, nullptr, nullptr, dst_name)){
printf("create output context failed!\n");
return -1;
}
//打开输出流
avio_open(&out_ctx->pb, dst_name, AVIO_FLAG_WRITE);
{
// 添加视频流
AVStream *out_video_stream = avformat_new_stream(out_ctx, nullptr);
avcodec_parameters_copy(out_video_stream->codecpar, video_stream->codecpar);
out_video_stream->codecpar->codec_tag = 0;
out_video_stream->time_base = video_stream->time_base;
// 添加音频流
AVStream *out_audio_stream = avformat_new_stream(out_ctx, nullptr);
avcodec_parameters_copy(out_audio_stream->codecpar, audio_stream->codecpar);
out_audio_stream->codecpar->codec_tag = 0;
}
// 写入头
if(0> avformat_write_header(out_ctx, nullptr)){
printf("write header failed!\n");
return -1;
}
AVPacket *pkt= av_packet_alloc();
while(av_read_frame(in_ctx, pkt) >= 0){
if(pkt->stream_index == video_stream_idx){
pkt->stream_index =0;
av_interleaved_write_frame(out_ctx, pkt);
}
else if(pkt->stream_index == audio_stream_idx){
pkt->stream_index =1;
av_interleaved_write_frame(out_ctx, pkt);
}
av_packet_unref(pkt);
}
// 写入尾
av_write_trailer(out_ctx);
printf("copy success:%s\n",dst_name);
av_packet_free(&pkt);
avio_close(out_ctx->pb);
avformat_free_context(out_ctx);
avformat_close_input(&in_ctx);
return 0;
}2 理论算法
Hello 算法 :https://www.hello-algo.com/chapter_preface/
目录
理论算法 的子部分
2.1 数据结构
目录
数据结构 的子部分
第1章
链表
链表 的子部分
1.2 单向节点链表
1.3 双向节点链表
节点模板类定义
template <typename Node>
class IListNode
{
Node *mNext;
Node *mPrev;
public:
inline IListNode()
: mNext(nullptr), mPrev(nullptr)
{
}
// 初始化节点
inline void init() { mNext = nullptr, mPrev = nullptr; }
// 获取后继节点
inline Node *getNext() { return mNext; }
// 获取前驱节点
inline Node *getPrev() { return mPrev; };
// 设置后继节点
inline void setNext(Node *next) { mNext = next; }
// 设置前驱节点
inline void setPrev(Node *prev) { mPrev = prev; };
// 设置节点
inline void setNode(Node *next, Node *prev) { mNext = next, mPrev = prev; }
};链表模板类定义
template <typename Node>
class IList
{
IListNode<Node> mRoot; // 链表根节点
uint mCount; // 节点计数
public:
// 链表初始化
inline IList()
: mCount(0)
{
mRoot.setNode((Node *)&mRoot, (Node *)&mRoot);
}
// 初始链表
inline void initList() { mCount = 0, mRoot.setNode((Node *)&mRoot, (Node *)&mRoot); }
// 获取根,只读
inline Node *getRoot() { return (Node *)&mRoot; }
// 获取节点计数
inline uint getCount() const { return mCount; }
// 获取第一个节点
inline Node *getEntry()
{
Node *ret = mRoot.getNext();
/* if (ret == &mRoot)
ret = nullptr;*/
return ret;
}
inline Node *front() { return getEntry(); }
// 获取最后一个节点
inline Node *getTail()
{
Node *ret = mRoot.getPrev();
/* if (ret == &mRoot)
ret = nullptr;*/
return ret;
}
inline Node *back() { return getTail(); }
// 从头部插入
inline void insertEntry(Node *node)
{
Node *head = mRoot.getNext();
node->setPrev((Node *)&mRoot);
node->setNext(head);
head->setPrev(node);
mRoot.setNext(node);
++mCount;
}
// 从尾部插入
inline void insertTail(Node *node)
{
Node *tail = mRoot.getPrev();
node->setPrev(tail);
node->setNext((Node *)&mRoot);
tail->setNext(node);
mRoot.setPrev(node);
++mCount;
}
// 从iter前面插入
inline void insert(Node *iter, Node *node)
{
iter->getPrev()->setNext(node);
node->setPrev(iter->getPrev());
node->setNext(iter);
iter->setPrev(node);
++mCount;
}
// 移除节点
inline Node *remove(Node *entry)
{
// 根节点并不能移除
if ((Node *)&mRoot == entry)
return nullptr;
Node *prev = entry->getPrev();
Node *next = entry->getNext();
prev->setNext(next);
next->setPrev(prev);
entry->init();
--mCount;
return entry;
}
// 移除头部节点
inline Node *removeEntry() { return remove(mRoot.getNext()); }
// 移除尾部节点
inline Node *removeTail() { return remove(mRoot.getPrev()); }
};2.2 整数对齐
// 向上大小对齐
template <typename T>
inline constexpr T alignup(T num, T base) { return (num + base - 1) & (~(base - 1)); }
// 向下大小对齐
template <typename T>
inline constexpr T aligndown(T num, T base) { return (num & ~(base - 1)); }2.3 哈希函数
目录
哈希函数 的子部分
3.1 消息摘要算法
简介
MD系列算法是信息摘要三大算法中的一种,全称:Message Digest算法,按照规范版本分为MD2、MD4、MD5三种算法,目前最常用的是MD5版本算法。
MD系列家族
消息摘要算法 的子部分
1.1 MD2 算法
原文来自:https://www.cnblogs.com/Kingfans/p/16546430.html
1 基本介绍
MD系列算法是信息摘要三大算法中的一种,全称:Message Digest算法,按照规范版本分为MD2、MD4、MD5三种算法,目前最常用的是MD5版本算法。本文介绍MD2算法的实现原理。
1989年,MD2是由著名的非对称算法RSA发明人之一–麻省理工学院教授罗纳德-里维斯特开发的;这个算法首先对信息进行数据补位,使信息的字节长度是16的倍数,再以16位的检验和作为补充信息追加到原信息的末尾。最后根据这个新产生的信息计算出一个128位的散列值,MD2算法由此诞生。
2 实现原理
有关MD2 算法详情请参见 RFC 1319 http://www.ietf.org/rfc/rfc1319.txt,RFC 1319 是MD2算法的官方文档,其实现原理共分为5步:
第1步:字节填充(Append Padding Bytes)
填充1~16个字节,确保是16字节的倍数,填充规则如下:
假设数据长度为m, 则需要填充16 - (m mod 16)个字节的数据,填充内容为16 - (m mod 16)。
第2步:添加校验和(Append Checksum)
根据下列算法计算校验和,并追加到第1步填充数据的后面。
/* Clear checksum. */
For i = 0 to 15 do:
Set C[i] to 0.
end /* of loop on i */
Set L to 0.
/* Process each 16-word block. */
For i = 0 to N/16-1 do
/* Checksum block i. */
For j = 0 to 15 do
Set c to M[i*16+j].
Set C[j] to S[c xor L].
Set L to C[j].
end /* of loop on j */
end /* of loop on i */第3步:初始化MD Buffer(Initialize MD Buffer)
最简单不过了,定义一个48字节数组X并初始化为0。
第4步:处理消息块(Process Message in 16-Byte Blocks)
这个是MD2算法最核心的部分了,对第2步组装数据进行分块依次处理。
/* Process each 16-word block. */
For i = 0 to N'/16-1 do
/* Copy block i into X. */
For j = 0 to 15 do
Set X[16+j] to M[i*16+j].
Set X[32+j] to (X[16+j] xor X[j]).
end /* of loop on j */
Set t to 0.
/* Do 18 rounds. */
For j = 0 to 17 do
/* Round j. */
For k = 0 to 47 do
Set t and X[k] to (X[k] xor S[t]).
end /* of loop on k */
Set t to (t+j) modulo 256.
end /* of loop on j */
end /* of loop on i */第5步:输出(Output)
这一步也非常简单,只需要将计算后的X前16字节进行输出就可以了
3 示例讲解
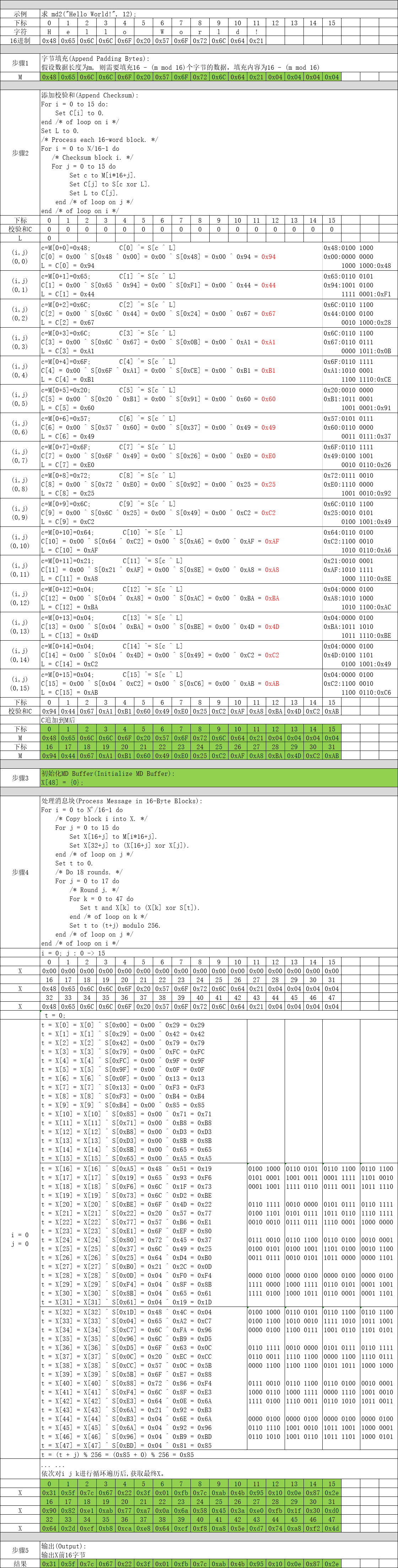
4 代码实现
#include <string.h>
#include <stdio.h>
#define HASH_BLOCK_SIZE 16
#define HASH_DIGEST_SIZE 16
#define HASH_ROUND_NUM 18
#define MD2_CHECKSUM_SIZE 16
#define ASSERT_RETURN_INT(x, d) if(!(x)) { return d; }
/*
* The S Box of MD2 are generated from Pi digits.
*/
static const unsigned char S[256] =
{
0x29, 0x2E, 0x43, 0xC9, 0xA2, 0xD8, 0x7C, 0x01, 0x3D, 0x36, 0x54, 0xA1, 0xEC, 0xF0, 0x06, 0x13,
0x62, 0xA7, 0x05, 0xF3, 0xC0, 0xC7, 0x73, 0x8C, 0x98, 0x93, 0x2B, 0xD9, 0xBC, 0x4C, 0x82, 0xCA,
0x1E, 0x9B, 0x57, 0x3C, 0xFD, 0xD4, 0xE0, 0x16, 0x67, 0x42, 0x6F, 0x18, 0x8A, 0x17, 0xE5, 0x12,
0xBE, 0x4E, 0xC4, 0xD6, 0xDA, 0x9E, 0xDE, 0x49, 0xA0, 0xFB, 0xF5, 0x8E, 0xBB, 0x2F, 0xEE, 0x7A,
0xA9, 0x68, 0x79, 0x91, 0x15, 0xB2, 0x07, 0x3F, 0x94, 0xC2, 0x10, 0x89, 0x0B, 0x22, 0x5F, 0x21,
0x80, 0x7F, 0x5D, 0x9A, 0x5A, 0x90, 0x32, 0x27, 0x35, 0x3E, 0xCC, 0xE7, 0xBF, 0xF7, 0x97, 0x03,
0xFF, 0x19, 0x30, 0xB3, 0x48, 0xA5, 0xB5, 0xD1, 0xD7, 0x5E, 0x92, 0x2A, 0xAC, 0x56, 0xAA, 0xC6,
0x4F, 0xB8, 0x38, 0xD2, 0x96, 0xA4, 0x7D, 0xB6, 0x76, 0xFC, 0x6B, 0xE2, 0x9C, 0x74, 0x04, 0xF1,
0x45, 0x9D, 0x70, 0x59, 0x64, 0x71, 0x87, 0x20, 0x86, 0x5B, 0xCF, 0x65, 0xE6, 0x2D, 0xA8, 0x02,
0x1B, 0x60, 0x25, 0xAD, 0xAE, 0xB0, 0xB9, 0xF6, 0x1C, 0x46, 0x61, 0x69, 0x34, 0x40, 0x7E, 0x0F,
0x55, 0x47, 0xA3, 0x23, 0xDD, 0x51, 0xAF, 0x3A, 0xC3, 0x5C, 0xF9, 0xCE, 0xBA, 0xC5, 0xEA, 0x26,
0x2C, 0x53, 0x0D, 0x6E, 0x85, 0x28, 0x84, 0x09, 0xD3, 0xDF, 0xCD, 0xF4, 0x41, 0x81, 0x4D, 0x52,
0x6A, 0xDC, 0x37, 0xC8, 0x6C, 0xC1, 0xAB, 0xFA, 0x24, 0xE1, 0x7B, 0x08, 0x0C, 0xBD, 0xB1, 0x4A,
0x78, 0x88, 0x95, 0x8B, 0xE3, 0x63, 0xE8, 0x6D, 0xE9, 0xCB, 0xD5, 0xFE, 0x3B, 0x00, 0x1D, 0x39,
0xF2, 0xEF, 0xB7, 0x0E, 0x66, 0x58, 0xD0, 0xE4, 0xA6, 0x77, 0x72, 0xF8, 0xEB, 0x75, 0x4B, 0x0A,
0x31, 0x44, 0x50, 0xB4, 0x8F, 0xED, 0x1F, 0x1A, 0xDB, 0x99, 0x8D, 0x33, 0x9F, 0x11, 0x83, 0x14
};
int md2(unsigned char *out, const unsigned char* in, const int inlen)
{
ASSERT_RETURN_INT(out && in && (inlen >= 0), 1);
int i = 0, j = 0, k = 0;
unsigned char L = 0, t = 0;
// step 1: 字节填充(Append Padding Bytes)
// 假设数据长度为m, 则需要填充16 - (m mod 16)个字节的数据,填充内容为16 - (m mod 16).
int iLen = (inlen / HASH_BLOCK_SIZE + 1) * HASH_BLOCK_SIZE;
unsigned char* M = malloc(iLen + MD2_CHECKSUM_SIZE);
memcpy(M, in, inlen);
for (i = inlen; i < iLen; i++)
{
M[i] = iLen - inlen;
}
// step 2: 添加校验和(Append Checksum)
unsigned char C[MD2_CHECKSUM_SIZE];
memset(C, 0, MD2_CHECKSUM_SIZE);
for (i = 0; i < iLen / HASH_BLOCK_SIZE; i++)
{
for (j = 0; j < HASH_BLOCK_SIZE; j++)
{
unsigned char c = M[i * 16 + j];
C[j] = C[j] ^ S[c ^ L];
L = C[j];
}
}
memcpy(M + iLen, C, HASH_BLOCK_SIZE);
// step 3: 初始化MD Buffer(Initialize MD Buffer):
unsigned char X[48];
memset(X, 0, 48);
// step 4: 处理消息块(Process Message in 16-Byte Blocks)
for (i = 0; i < (iLen + 16) / HASH_BLOCK_SIZE; i++)
{
/* Copy block i into X. */
for (j = 0; j < HASH_BLOCK_SIZE; j++)
{
X[16 + j] = M[i * 16 + j];
X[32 + j] = X[16 + j] ^ X[j];
}
t = 0;
/* Do 18 rounds. */
for (j = 0; j < HASH_ROUND_NUM; j++)
{
/* Round j */
for (k = 0; k < 48; k++)
{
t = X[k] = X[k] ^ S[t];
}
t = (t + j) % 256;
}
}
memcpy(out, X, HASH_DIGEST_SIZE);
free(M);
return 0;
}
int main()
{
unsigned char digest[16] = { 0 };
md2(digest, "Hello World!", strlen("Hello World!"));
return 0;
}1.2 MD4 算法
原文来自:https://www.cnblogs.com/Kingfans/p/16552308.html
一、基本介绍
MD系列算法是信息摘要三大算法中的一种,全称:Message Digest算法,按照规范版本分为MD2、MD4、MD5三种算法,目前最常用的是MD5版本算法。本文介绍MD4算法的实现原理。
1990 年,罗纳德·李维斯特教授开发出较之 MD2 算法有着更高安全性的 MD4 算法。在这个算法中,我们仍需对信息进行数据补位。不同的是,这种补位使其信息的字节长度加上 448 个字节后能成为 512 的倍数(信息字节长度 mod 512 = 448)。此外,关于 MD4 算法的处理与 MD2 算法又有很大差别。但最终仍旧是会获得一个 128 位的散列值。MD4 算法对后续消息摘要算法起到了推动作用,许多比较有名的消息摘要算法都是在 MD4 算法的基础上发展而来的,如 MD5、SHA-1、RIPE-MD 和 HAVAL 算法等。
二、实现原理
有关 MD4 算法详情请参见 RFC 1320 http://www.ietf.org/rfc/rfc1320.txt,RFC 1320 是MD4算法的官方文档,其实现原理共分为5步:
第1步:字节填充(Append Padding Bytes)
数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数。
第2步:追加长度信息(Append Length)
数据比特位的数据长度追加到最后8字节中。
第3步:初始化MD Buffer(Initialize MD Buffer)
这一步最简单了,定义ABCD四个4字节数组,分别赋初值即可。
1
2
3
4
uint32_t A = 0x67452301; // [ 0x01, 0x23, 0x45, 0x67 ]
uint32_t B = 0xEFCDAB89; // [ 0x89, 0xAB, 0xCD, 0xEF ]
uint32_t C = 0x98BADCFE; // [ 0xFE, 0xDC, 0xBA, 0x98 ]
uint32_t D = 0x10325476; // [ 0x76, 0x54, 0x32, 0x10 ] 第4步:处理消息块(Process Message in 16-Byte Blocks)
这个是MD4算法最核心的部分了,对第2步组装数据进行分块依次处理。
Process each 16-word block. */
For i = 0 to N/16-1 do
/* Copy block i into X. */
For j = 0 to 15 do
Set X[j] to M[i*16+j].
end /* of loop on j */
/* Save A as AA, B as BB, C as CC, and D as DD. */
AA = A
BB = B
CC = C
DD = D
/* Round 1. */
/* Let [abcd k s] denote the operation
a = (a + F(b,c,d) + X[k]) <<< s. */
/* Do the following 16 operations. */
[ABCD 0 3] [DABC 1 7] [CDAB 2 11] [BCDA 3 19]
[ABCD 4 3] [DABC 5 7] [CDAB 6 11] [BCDA 7 19]
[ABCD 8 3] [DABC 9 7] [CDAB 10 11] [BCDA 11 19]
[ABCD 12 3] [DABC 13 7] [CDAB 14 11] [BCDA 15 19]
/* Round 2. */
/* Let [abcd k s] denote the operation
a = (a + G(b,c,d) + X[k] + 5A827999) <<< s. */
/* Do the following 16 operations. */
[ABCD 0 3] [DABC 4 5] [CDAB 8 9] [BCDA 12 13]
[ABCD 1 3] [DABC 5 5] [CDAB 9 9] [BCDA 13 13]
[ABCD 2 3] [DABC 6 5] [CDAB 10 9] [BCDA 14 13]
[ABCD 3 3] [DABC 7 5] [CDAB 11 9] [BCDA 15 13]
/* Round 3. */
/* Let [abcd k s] denote the operation
a = (a + H(b,c,d) + X[k] + 6ED9EBA1) <<< s. */
/* Do the following 16 operations. */
[ABCD 0 3] [DABC 8 9] [CDAB 4 11] [BCDA 12 15]
[ABCD 2 3] [DABC 10 9] [CDAB 6 11] [BCDA 14 15]
[ABCD 1 3] [DABC 9 9] [CDAB 5 11] [BCDA 13 15]
[ABCD 3 3] [DABC 11 9] [CDAB 7 11] [BCDA 15 15]
/* Then perform the following additions. (That is, increment each
of the four registers by the value it had before this block
was started.) */
A = A + AA
B = B + BB
C = C + CC
D = D + DD
end /* of loop on i */第5步:输出(Output)
这一步也非常简单,只需要将计算后的A、B、C、D进行拼接输出即可。
三、示例讲解
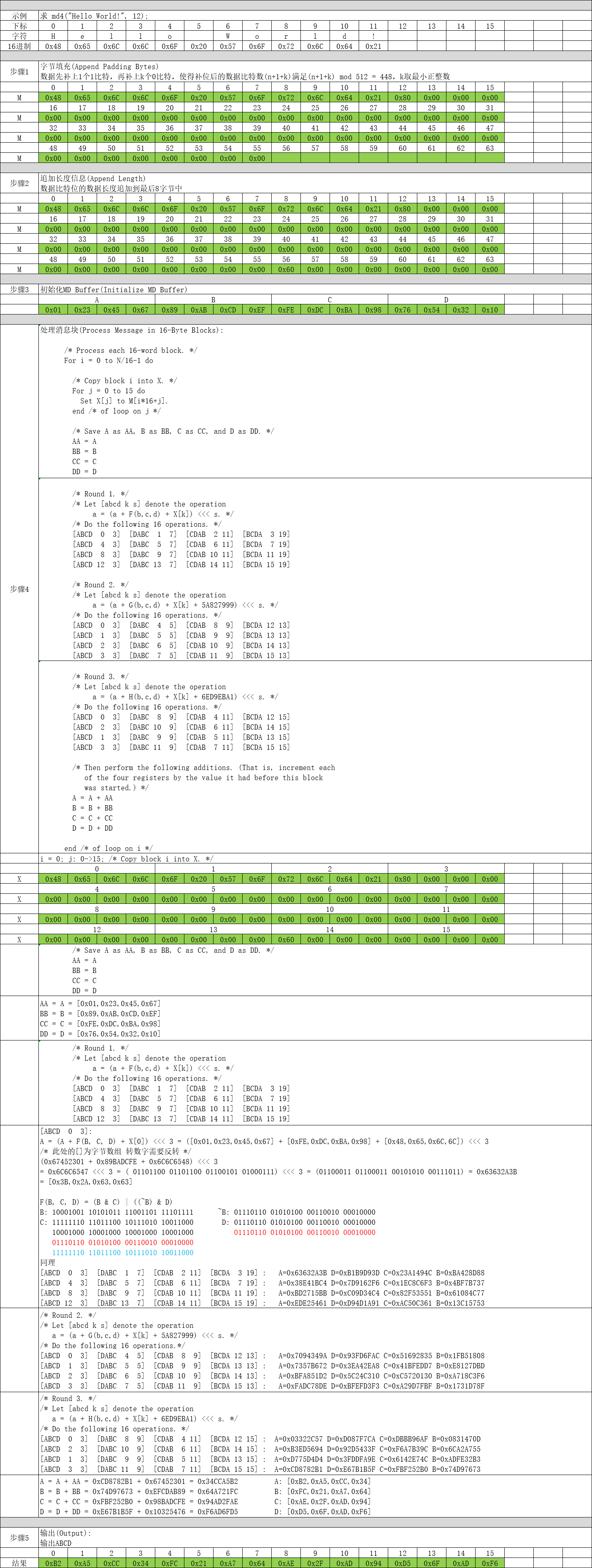
代码实现
#include <string.h>
#include <stdio.h>
#define HASH_BLOCK_SIZE 64 /* 512 bits = 64 bytes */
#define HASH_LEN_SIZE 8 /* 64 bits = 8 bytes */
#define HASH_LEN_OFFSET 56 /* 64 bytes - 8 bytes */
#define HASH_DIGEST_SIZE 16 /* 128 bits = 16 bytes */
#define HASH_ROUND_NUM 64
typedef unsigned char uint8_t;
typedef unsigned short int uint16_t;
typedef unsigned int uint32_t;
typedef unsigned long long uint64_t;
static uint32_t F(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) | ((~X) & Z);
}
static uint32_t G(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) | (X & Z) | (Y & Z);
}
static uint32_t H(uint32_t X, uint32_t Y, uint32_t Z)
{
return X ^ Y ^ Z;
}
/* 循环向左移动offset个单位 */
static uint32_t MoveLeft(uint32_t X, uint8_t offset)
{
return (X << offset) | (X >> (32 - offset));
}
static uint32_t Round1(uint32_t A, uint32_t B, uint32_t C, uint32_t D, uint32_t M, uint32_t N)
{
return MoveLeft(A + F(B, C, D) + M, N);
}
static uint32_t Round2(uint32_t A, uint32_t B, uint32_t C, uint32_t D, uint32_t M, uint32_t N)
{
return MoveLeft(A + G(B, C, D) + M + 0x5A827999, N);
}
static uint32_t Round3(uint32_t A, uint32_t B, uint32_t C, uint32_t D, uint32_t M, uint32_t N)
{
return MoveLeft(A + H(B, C, D) + M + 0x6ED9EBA1, N);
}
#define ASSERT_RETURN_INT(x, d) if(!(x)) { return d; }
int md4(unsigned char *out, const unsigned char* in, const int inlen)
{
ASSERT_RETURN_INT(out && in && (inlen > 0), 1);
int i = 0, j = 0, k = 0;
unsigned char L = 0, t = 0;
// step 1: 字节填充(Append Padding Bytes)
// 数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数
int iX = inlen / HASH_BLOCK_SIZE;
int iY = inlen % HASH_BLOCK_SIZE;
iX = (iY < HASH_LEN_OFFSET) ? iX : (iX + 1);
int iLen = (iX + 1) * HASH_BLOCK_SIZE;
unsigned char* M = malloc(iLen);
memcpy(M, in, inlen);
// 先补上1个1比特+7个0比特
M[inlen] = 0x80;
// 再补上(k-7)个0比特
for (i = inlen + 1; i < (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET); i++)
{
M[i] = 0;
}
// step 2: 追加长度信息(Append Length)
uint64_t *pLen = (uint64_t*)(M + (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET));
*pLen = inlen << 3;
// Step 3. 初始化MD Buffer(Initialize MD Buffer)
uint32_t A = 0x67452301; // [ 0x01, 0x23, 0x45, 0x67 ]
uint32_t B = 0xEFCDAB89; // [ 0x89, 0xAB, 0xCD, 0xEF ]
uint32_t C = 0x98BADCFE; // [ 0xFE, 0xDC, 0xBA, 0x98 ]
uint32_t D = 0x10325476; // [ 0x76, 0x54, 0x32, 0x10 ]
uint32_t X[HASH_BLOCK_SIZE / 4] = { 0 };
// step 4: 处理消息块(Process Message in 64-Byte Blocks)
for (i = 0; i < iLen / HASH_BLOCK_SIZE; i++)
{
/* Copy block i into X. */
for (j = 0; j < HASH_BLOCK_SIZE; j = j + 4)
{
uint32_t* temp = &M[i * HASH_BLOCK_SIZE + j];
X[j/4] = *temp;
}
/* Save A as AA, B as BB, C as CC, and D as DD. */
uint32_t AA = A;
uint32_t BB = B;
uint32_t CC = C;
uint32_t DD = D;
/* Round 1. */
/* Let [abcd k s] denote the operation
a = (a + F(b,c,d) + X[k]) <<< s. */
/* Do the following 16 operations.
[ABCD 0 3][DABC 1 7][CDAB 2 11][BCDA 3 19]
[ABCD 4 3][DABC 5 7][CDAB 6 11][BCDA 7 19]
[ABCD 8 3][DABC 9 7][CDAB 10 11][BCDA 11 19]
[ABCD 12 3][DABC 13 7][CDAB 14 11][BCDA 15 19]
*/
A = Round1(A, B, C, D, X[0], 3); D = Round1(D, A, B, C, X[1], 7); C = Round1(C, D, A, B, X[2], 11); B = Round1(B, C, D, A, X[3], 19);
A = Round1(A, B, C, D, X[4], 3); D = Round1(D, A, B, C, X[5], 7); C = Round1(C, D, A, B, X[6], 11); B = Round1(B, C, D, A, X[7], 19);
A = Round1(A, B, C, D, X[8], 3); D = Round1(D, A, B, C, X[9], 7); C = Round1(C, D, A, B, X[10], 11); B = Round1(B, C, D, A, X[11], 19);
A = Round1(A, B, C, D, X[12], 3); D = Round1(D, A, B, C, X[13], 7); C = Round1(C, D, A, B, X[14], 11); B = Round1(B, C, D, A, X[15], 19);
/* Round 2. */
/* Let [abcd k s] denote the operation
a = (a + G(b,c,d) + X[k] + 5A827999) <<< s. */
/* Do the following 16 operations.
[ABCD 0 3][DABC 4 5][CDAB 8 9][BCDA 12 13]
[ABCD 1 3][DABC 5 5][CDAB 9 9][BCDA 13 13]
[ABCD 2 3][DABC 6 5][CDAB 10 9][BCDA 14 13]
[ABCD 3 3][DABC 7 5][CDAB 11 9][BCDA 15 13]
*/
A = Round2(A, B, C, D, X[0], 3); D = Round2(D, A, B, C, X[4], 5); C = Round2(C, D, A, B, X[8], 9); B = Round2(B, C, D, A, X[12], 13);
A = Round2(A, B, C, D, X[1], 3); D = Round2(D, A, B, C, X[5], 5); C = Round2(C, D, A, B, X[9], 9); B = Round2(B, C, D, A, X[13], 13);
A = Round2(A, B, C, D, X[2], 3); D = Round2(D, A, B, C, X[6], 5); C = Round2(C, D, A, B, X[10], 9); B = Round2(B, C, D, A, X[14], 13);
A = Round2(A, B, C, D, X[3], 3); D = Round2(D, A, B, C, X[7], 5); C = Round2(C, D, A, B, X[11], 9); B = Round2(B, C, D, A, X[15], 13);
/* Round 3. */
/* Let [abcd k s] denote the operation
a = (a + H(b,c,d) + X[k] + 6ED9EBA1) <<< s. */
/* Do the following 16 operations.
[ABCD 0 3][DABC 8 9][CDAB 4 11][BCDA 12 15]
[ABCD 2 3][DABC 10 9][CDAB 6 11][BCDA 14 15]
[ABCD 1 3][DABC 9 9][CDAB 5 11][BCDA 13 15]
[ABCD 3 3][DABC 11 9][CDAB 7 11][BCDA 15 15]
*/
A = Round3(A, B, C, D, X[0], 3); D = Round3(D, A, B, C, X[8], 9); C = Round3(C, D, A, B, X[4], 11); B = Round3(B, C, D, A, X[12], 15);
A = Round3(A, B, C, D, X[2], 3); D = Round3(D, A, B, C, X[10], 9); C = Round3(C, D, A, B, X[6], 11); B = Round3(B, C, D, A, X[14], 15);
A = Round3(A, B, C, D, X[1], 3); D = Round3(D, A, B, C, X[9], 9); C = Round3(C, D, A, B, X[5], 11); B = Round3(B, C, D, A, X[13], 15);
A = Round3(A, B, C, D, X[3], 3); D = Round3(D, A, B, C, X[11], 9); C = Round3(C, D, A, B, X[7], 11); B = Round3(B, C, D, A, X[15], 15);
/* Then perform the following additions. (That is, increment each
of the four registers by the value it had before this block
was started.) */
A = A + AA;
B = B + BB;
C = C + CC;
D = D + DD;
}
// step 5: 输出ABCD
memcpy(out + 0, &A, 4);
memcpy(out + 4, &B, 4);
memcpy(out + 8, &C, 4);
memcpy(out + 12, &D, 4);
free(M);
return 0;
}
int main()
{
unsigned char digest[16] = { 0 };
md4(digest, "Hello World!", strlen("Hello World!"));
return 0;
}1.3 MD5 算法
原文来自:https://www.cnblogs.com/Kingfans/p/16554047.html
一、基本介绍
MD系列算法是信息摘要三大算法中的一种,全称:Message Digest算法,按照规范版本分为MD2、MD4、MD5三种算法,目前最常用的是MD5版本算法。本文介绍MD5算法的实现原理。
1991年,继 MD4 算法后,罗纳德·李维斯特教授开发了 MD5 算法,将 MD 算法推向成熟。MD5 算法经 MD2、MD3 和 MD4 算法发展而来,算法复杂程度和安全强度大大提高。但不管是 MD2、MD4 还是 MD5 算法,其算法的最终结果均是产生一个 128 位的消息摘要,这也是 MD 系列算法的特点。MD5 算法执行效率略次于 MD4 算法,但在安全性方面,MD5 算法更胜一筹。随着计算机技术的发展和计算水平的不断提高,MD5 算法暴露出来的漏洞也越来越多。1996 年后被证实存在弱点,可以被加以破解,对于需要高度安全性的数据,专家一般建议改用其他算法,如 SHA-2。2004 年,证实 MD5 算法无法防止碰撞(collision),因此不适用于安全性认证,如 SSL 公开密钥认证或是数字签名等用途。
二、实现原理
有关 MD5 算法详情请参见 RFC 1321 http://www.ietf.org/rfc/rfc1321.txt,RFC 1321 是MD5算法的官方文档,其实现原理共分为5步:
第1步:字节填充(Append Padding Bytes)
数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数。
第2步:追加长度信息(Append Length)
数据比特位的数据长度追加到最后8字节中。
第3步:初始化MD Buffer(Initialize MD Buffer)
这一步最简单了,定义ABCD四个4字节数组,分别赋初值即可。
uint32_t A = 0x67452301; // [ 0x01, 0x23, 0x45, 0x67 ]
uint32_t B = 0xEFCDAB89; // [ 0x89, 0xAB, 0xCD, 0xEF ]
uint32_t C = 0x98BADCFE; // [ 0xFE, 0xDC, 0xBA, 0x98 ]
uint32_t D = 0x10325476; // [ 0x76, 0x54, 0x32, 0x10 ]以上操作与md4完全一致。
第4步:处理消息块(Process Message in 16-Byte Blocks)
这个是MD5算法最核心的部分了,对第2步组装数据进行分块依次处理。
/* Process each 16-word block. */
For i = 0 to N/16-1 do
/* Copy block i into X. */
For j = 0 to 15 do
Set X[j] to M[i*16+j].
end /* of loop on j */
/* Save A as AA, B as BB, C as CC, and D as DD. */
AA = A
BB = B
CC = C
DD = D
/* Round 1. */
/* Let [abcd k s i] denote the operation
a = b + ((a + F(b,c,d) + X[k] + T[i]) <<< s). */
/* Do the following 16 operations. */
[ABCD 0 7 1] [DABC 1 12 2] [CDAB 2 17 3] [BCDA 3 22 4]
[ABCD 4 7 5] [DABC 5 12 6] [CDAB 6 17 7] [BCDA 7 22 8]
[ABCD 8 7 9] [DABC 9 12 10] [CDAB 10 17 11] [BCDA 11 22 12]
[ABCD 12 7 13] [DABC 13 12 14] [CDAB 14 17 15] [BCDA 15 22 16]
/* Round 2. */
/* Let [abcd k s i] denote the operation
a = b + ((a + G(b,c,d) + X[k] + T[i]) <<< s). */
/* Do the following 16 operations. */
[ABCD 1 5 17] [DABC 6 9 18] [CDAB 11 14 19] [BCDA 0 20 20]
[ABCD 5 5 21] [DABC 10 9 22] [CDAB 15 14 23] [BCDA 4 20 24]
[ABCD 9 5 25] [DABC 14 9 26] [CDAB 3 14 27] [BCDA 8 20 28]
[ABCD 13 5 29] [DABC 2 9 30] [CDAB 7 14 31] [BCDA 12 20 32]
/* Round 3. */
/* Let [abcd k s t] denote the operation
a = b + ((a + H(b,c,d) + X[k] + T[i]) <<< s). */
/* Do the following 16 operations. */
[ABCD 5 4 33] [DABC 8 11 34] [CDAB 11 16 35] [BCDA 14 23 36]
[ABCD 1 4 37] [DABC 4 11 38] [CDAB 7 16 39] [BCDA 10 23 40]
[ABCD 13 4 41] [DABC 0 11 42] [CDAB 3 16 43] [BCDA 6 23 44]
[ABCD 9 4 45] [DABC 12 11 46] [CDAB 15 16 47] [BCDA 2 23 48]
/* Round 4. */
/* Let [abcd k s t] denote the operation
a = b + ((a + I(b,c,d) + X[k] + T[i]) <<< s). */
/* Do the following 16 operations. */
[ABCD 0 6 49] [DABC 7 10 50] [CDAB 14 15 51] [BCDA 5 21 52]
[ABCD 12 6 53] [DABC 3 10 54] [CDAB 10 15 55] [BCDA 1 21 56]
[ABCD 8 6 57] [DABC 15 10 58] [CDAB 6 15 59] [BCDA 13 21 60]
[ABCD 4 6 61] [DABC 11 10 62] [CDAB 2 15 63] [BCDA 9 21 64]
/* Then perform the following additions. (That is increment each
of the four registers by the value it had before this block
was started.) */
A = A + AA
B = B + BB
C = C + CC
D = D + DD
end /* of loop on i */第5步:输出(Output)
这一步也非常简单,只需要将计算后的A、B、C、D进行拼接输出即可。
三、示例讲解
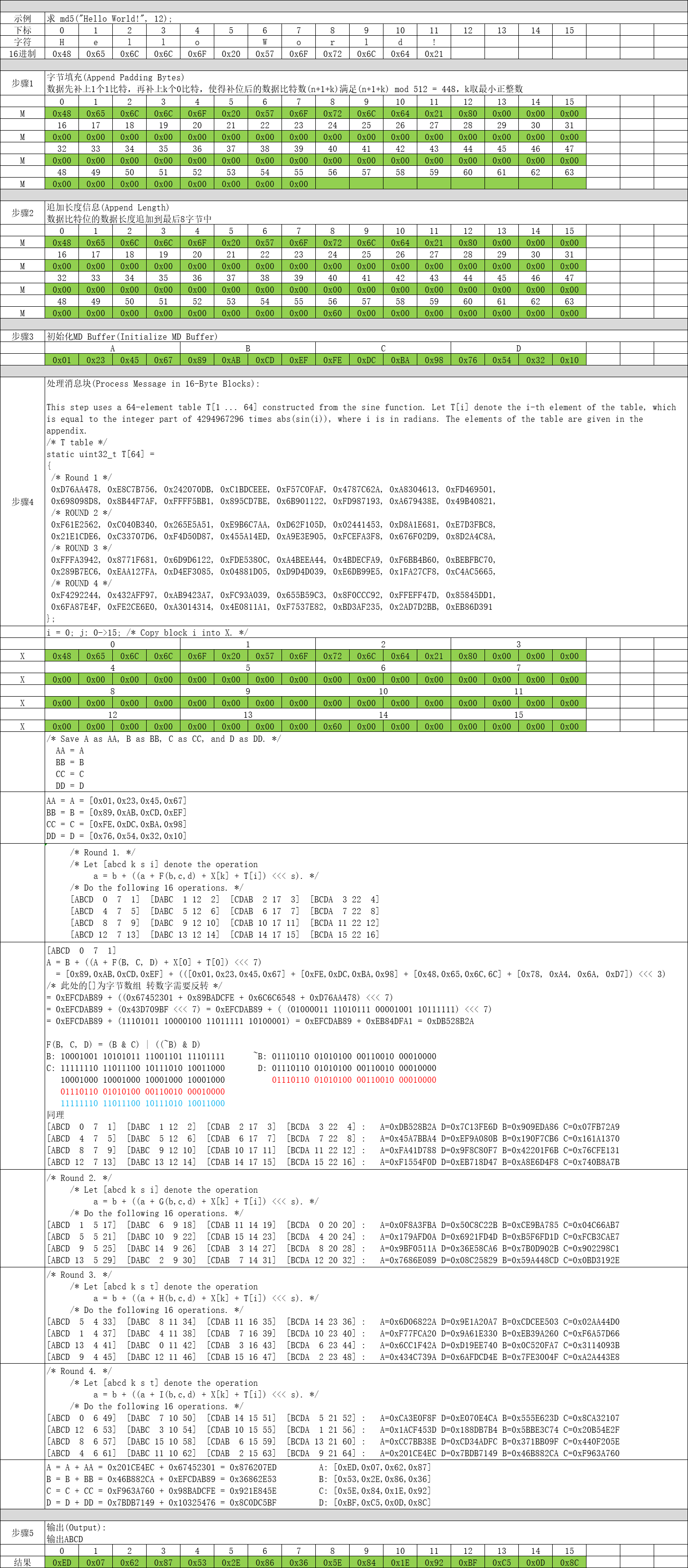
四、代码实现
以下为C/C++代码实现:
#include <string.h>
#include <stdio.h>
#define HASH_BLOCK_SIZE 64 /* 512 bits = 64 bytes */
#define HASH_LEN_SIZE 8 /* 64 bits = 8 bytes */
#define HASH_LEN_OFFSET 56 /* 64 bytes - 8 bytes */
#define HASH_DIGEST_SIZE 16 /* 128 bits = 16 bytes */
typedef unsigned char uint8_t;
typedef unsigned short int uint16_t;
typedef unsigned int uint32_t;
typedef unsigned long long uint64_t;
/* T table */
static uint32_t T[64] =
{
/* Round 1 */
0xD76AA478, 0xE8C7B756, 0x242070DB, 0xC1BDCEEE, 0xF57C0FAF, 0x4787C62A, 0xA8304613, 0xFD469501,
0x698098D8, 0x8B44F7AF, 0xFFFF5BB1, 0x895CD7BE, 0x6B901122, 0xFD987193, 0xA679438E, 0x49B40821,
/* ROUND 2 */
0xF61E2562, 0xC040B340, 0x265E5A51, 0xE9B6C7AA, 0xD62F105D, 0x02441453, 0xD8A1E681, 0xE7D3FBC8,
0x21E1CDE6, 0xC33707D6, 0xF4D50D87, 0x455A14ED, 0xA9E3E905, 0xFCEFA3F8, 0x676F02D9, 0x8D2A4C8A,
/* ROUND 3 */
0xFFFA3942, 0x8771F681, 0x6D9D6122, 0xFDE5380C, 0xA4BEEA44, 0x4BDECFA9, 0xF6BB4B60, 0xBEBFBC70,
0x289B7EC6, 0xEAA127FA, 0xD4EF3085, 0x04881D05, 0xD9D4D039, 0xE6DB99E5, 0x1FA27CF8, 0xC4AC5665,
/* ROUND 4 */
0xF4292244, 0x432AFF97, 0xAB9423A7, 0xFC93A039, 0x655B59C3, 0x8F0CCC92, 0xFFEFF47D, 0x85845DD1,
0x6FA87E4F, 0xFE2CE6E0, 0xA3014314, 0x4E0811A1, 0xF7537E82, 0xBD3AF235, 0x2AD7D2BB, 0xEB86D391
};
static uint32_t F(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) | ((~X) & Z);
}
static uint32_t G(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Z) | (Y & (~Z));
}
static uint32_t H(uint32_t X, uint32_t Y, uint32_t Z)
{
return X ^ Y ^ Z;
}
static uint32_t I(uint32_t X, uint32_t Y, uint32_t Z)
{
return Y ^ ( X | (~Z));
}
/* 循环向左移动offset个比特位 */
static uint32_t MoveLeft(uint32_t X, uint8_t offset)
{
uint32_t res = (X << offset) | (X >> (32 - offset));
return res;
}
static uint32_t Round1(uint32_t A, uint32_t B, uint32_t C, uint32_t D, uint32_t M, uint32_t N, uint32_t T)
{
return B + MoveLeft(A + F(B, C, D) + M + T, N);
}
static uint32_t Round2(uint32_t A, uint32_t B, uint32_t C, uint32_t D, uint32_t M, uint32_t N, uint32_t T)
{
return B + MoveLeft(A + G(B, C, D) + M + T, N);
}
static uint32_t Round3(uint32_t A, uint32_t B, uint32_t C, uint32_t D, uint32_t M, uint32_t N, uint32_t T)
{
return B + MoveLeft(A + H(B, C, D) + M + T, N);
}
static uint32_t Round4(uint32_t A, uint32_t B, uint32_t C, uint32_t D, uint32_t M, uint32_t N, uint32_t T)
{
return B + MoveLeft(A + I(B, C, D) + M + T, N);
}
#define ASSERT_RETURN_INT(x, d) if(!(x)) { return d; }
int md5(unsigned char *out, const unsigned char* in, const int inlen)
{
ASSERT_RETURN_INT(out && in && (inlen >= 0), 1);
int i = 0, j = 0;
// step 1: 字节填充(Append Padding Bytes)
// 数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数
int iX = inlen / HASH_BLOCK_SIZE;
int iY = inlen % HASH_BLOCK_SIZE;
iX = (iY < HASH_LEN_OFFSET) ? iX : (iX + 1);
int iLen = (iX + 1) * HASH_BLOCK_SIZE;
unsigned char* M = malloc(iLen);
memcpy(M, in, inlen);
// 先补上1个1比特+7个0比特
M[inlen] = 0x80;
// 再补上(k-7)个0比特
for (i = inlen + 1; i < (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET); i++)
{
M[i] = 0;
}
// step 2: 追加长度信息(Append Length)
uint64_t *pLen = (uint64_t*)(M + (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET));
*pLen = inlen << 3;
// Step 3. 初始化MD Buffer(Initialize MD Buffer)
uint32_t A = 0x67452301; // 0x01, 0x23, 0x45, 0x67
uint32_t B = 0xEFCDAB89; // 0x89, 0xAB, 0xCD, 0xEF
uint32_t C = 0x98BADCFE; // 0xFE, 0xDC, 0xBA, 0x98
uint32_t D = 0x10325476; // 0x76, 0x54, 0x32, 0x10
uint32_t X[HASH_BLOCK_SIZE / 4] = { 0 };
// step 4: 处理消息块(Process Message in 64-Byte Blocks)
for (i = 0; i < iLen / HASH_BLOCK_SIZE; i++)
{
/* Copy block i into X. */
for (j = 0; j < HASH_BLOCK_SIZE; j = j + 4)
{
uint32_t* temp = &M[i * HASH_BLOCK_SIZE + j];
X[j / 4] = *temp;
}
/* Save A as AA, B as BB, C as CC, and D as DD. */
uint32_t AA = A;
uint32_t BB = B;
uint32_t CC = C;
uint32_t DD = D;
/* Round 1. */
/* Let [abcd k s i] denote the operation
a = b + ((a + F(b,c,d) + X[k] + T[i]) <<< s). */
/* Do the following 16 operations.
[ABCD 0 7 1][DABC 1 12 2][CDAB 2 17 3][BCDA 3 22 4]
[ABCD 4 7 5][DABC 5 12 6][CDAB 6 17 7][BCDA 7 22 8]
[ABCD 8 7 9][DABC 9 12 10][CDAB 10 17 11][BCDA 11 22 12]
[ABCD 12 7 13][DABC 13 12 14][CDAB 14 17 15][BCDA 15 22 16]
此处T[i]有问题 应该是i-1 索引下标从0开始
*/
A = Round1(A, B, C, D, X[0], 7, T[0]); D = Round1(D, A, B, C, X[1], 12, T[1]); C = Round1(C, D, A, B, X[2], 17, T[2]); B = Round1(B, C, D, A, X[3], 22, T[3]);
A = Round1(A, B, C, D, X[4], 7, T[4]); D = Round1(D, A, B, C, X[5], 12, T[5]); C = Round1(C, D, A, B, X[6], 17, T[6]); B = Round1(B, C, D, A, X[7], 22, T[7]);
A = Round1(A, B, C, D, X[8], 7, T[8]); D = Round1(D, A, B, C, X[9], 12, T[9]); C = Round1(C, D, A, B, X[10], 17, T[10]); B = Round1(B, C, D, A, X[11], 22, T[11]);
A = Round1(A, B, C, D, X[12], 7, T[12]); D = Round1(D, A, B, C, X[13], 12, T[13]); C = Round1(C, D, A, B, X[14], 17, T[14]); B = Round1(B, C, D, A, X[15], 22, T[15]);
/* Round 2. */
/* Let [abcd k s i] denote the operation
a = b + ((a + G(b,c,d) + X[k] + T[i]) <<< s). */
/* Do the following 16 operations.
[ABCD 1 5 17][DABC 6 9 18][CDAB 11 14 19][BCDA 0 20 20]
[ABCD 5 5 21][DABC 10 9 22][CDAB 15 14 23][BCDA 4 20 24]
[ABCD 9 5 25][DABC 14 9 26][CDAB 3 14 27][BCDA 8 20 28]
[ABCD 13 5 29][DABC 2 9 30][CDAB 7 14 31][BCDA 12 20 32]
*/
A = Round2(A, B, C, D, X[1], 5, T[16]); D = Round2(D, A, B, C, X[6], 9, T[17]); C = Round2(C, D, A, B, X[11], 14, T[18]); B = Round2(B, C, D, A, X[0], 20, T[19]);
A = Round2(A, B, C, D, X[5], 5, T[20]); D = Round2(D, A, B, C, X[10], 9, T[21]); C = Round2(C, D, A, B, X[15], 14, T[22]); B = Round2(B, C, D, A, X[4], 20, T[23]);
A = Round2(A, B, C, D, X[9], 5, T[24]); D = Round2(D, A, B, C, X[14], 9, T[25]); C = Round2(C, D, A, B, X[3], 14, T[26]); B = Round2(B, C, D, A, X[8], 20, T[27]);
A = Round2(A, B, C, D, X[13], 5, T[28]); D = Round2(D, A, B, C, X[2], 9, T[29]); C = Round2(C, D, A, B, X[7], 14, T[30]); B = Round2(B, C, D, A, X[12], 20, T[31]);
/* Round 3. */
/* Let [abcd k s t] denote the operation
a = b + ((a + H(b,c,d) + X[k] + T[i]) <<< s). */
/* Do the following 16 operations.
[ABCD 5 4 33][DABC 8 11 34][CDAB 11 16 35][BCDA 14 23 36]
[ABCD 1 4 37][DABC 4 11 38][CDAB 7 16 39][BCDA 10 23 40]
[ABCD 13 4 41][DABC 0 11 42][CDAB 3 16 43][BCDA 6 23 44]
[ABCD 9 4 45][DABC 12 11 46][CDAB 15 16 47][BCDA 2 23 48]
*/
A = Round3(A, B, C, D, X[5], 4, T[32]); D = Round3(D, A, B, C, X[8], 11, T[33]); C = Round3(C, D, A, B, X[11], 16, T[34]); B = Round3(B, C, D, A, X[14], 23, T[35]);
A = Round3(A, B, C, D, X[1], 4, T[36]); D = Round3(D, A, B, C, X[4], 11, T[37]); C = Round3(C, D, A, B, X[7], 16, T[38]); B = Round3(B, C, D, A, X[10], 23, T[39]);
A = Round3(A, B, C, D, X[13], 4, T[40]); D = Round3(D, A, B, C, X[0], 11, T[41]); C = Round3(C, D, A, B, X[3], 16, T[42]); B = Round3(B, C, D, A, X[6], 23, T[43]);
A = Round3(A, B, C, D, X[9], 4, T[44]); D = Round3(D, A, B, C, X[12], 11, T[45]); C = Round3(C, D, A, B, X[15], 16, T[46]); B = Round3(B, C, D, A, X[2], 23, T[47]);
/* Round 4. */
/* Let [abcd k s t] denote the operation
a = b + ((a + I(b,c,d) + X[k] + T[i]) <<< s). */
/* Do the following 16 operations.
[ABCD 0 6 49][DABC 7 10 50][CDAB 14 15 51][BCDA 5 21 52]
[ABCD 12 6 53][DABC 3 10 54][CDAB 10 15 55][BCDA 1 21 56]
[ABCD 8 6 57][DABC 15 10 58][CDAB 6 15 59][BCDA 13 21 60]
[ABCD 4 6 61][DABC 11 10 62][CDAB 2 15 63][BCDA 9 21 64]
*/
A = Round4(A, B, C, D, X[0], 6, T[48]); D = Round4(D, A, B, C, X[7], 10, T[49]); C = Round4(C, D, A, B, X[14], 15, T[50]); B = Round4(B, C, D, A, X[5], 21, T[51]);
A = Round4(A, B, C, D, X[12], 6, T[52]); D = Round4(D, A, B, C, X[3], 10, T[53]); C = Round4(C, D, A, B, X[10], 15, T[54]); B = Round4(B, C, D, A, X[1], 21, T[55]);
A = Round4(A, B, C, D, X[8], 6, T[56]); D = Round4(D, A, B, C, X[15], 10, T[57]); C = Round4(C, D, A, B, X[6], 15, T[58]); B = Round4(B, C, D, A, X[13], 21, T[59]);
A = Round4(A, B, C, D, X[4], 6, T[60]); D = Round4(D, A, B, C, X[11], 10, T[61]); C = Round4(C, D, A, B, X[2], 15, T[62]); B = Round4(B, C, D, A, X[9], 21, T[63]);
/* Then perform the following additions. (That is, increment each
of the four registers by the value it had before this block
was started.) */
A = A + AA;
B = B + BB;
C = C + CC;
D = D + DD;
}
// step 5: 输出ABCD
memcpy(out + 0, &A, 4);
memcpy(out + 4, &B, 4);
memcpy(out + 8, &C, 4);
memcpy(out + 12, &D, 4);
free(M);
return 0;
}
int main()
{
unsigned char digest[16] = { 0 };
md5(digest, "Hello World!", strlen("Hello World!"));
return 0;
}3.2 签名算法
原文来自:https://www.cnblogs.com/Kingfans/p/16546386.html
简介
SHA (Security Hash Algorithm) 是美国的 NIST 和 NSA 设计的一种标准的 Hash 算法,SHA 用于数字签名的标准算法的 DSS 中,也是安全性很高的一种 Hash 算法。
SHA系列家族
签名算法 的子部分
2.1 SHA1 算法
原文来自:https://www.cnblogs.com/Kingfans/p/16561821.html
一、基本介绍
SHA (Security Hash Algorithm) 是美国的 NIST 和 NSA 设计的一种标准的 Hash 算法,SHA 用于数字签名的标准算法的 DSS 中,也是安全性很高的一种 Hash 算法。
SHA-1 是第一代 SHA 算法标准,后来的 SHA-224、SHA-256、SHA-384 和 SHA-512 被统称为 SHA-2。
二、实现原理
有关 SHA1 算法详情请参见 RFC 3174 http://www.ietf.org/rfc/rfc3174.txt。
RFC 3174 是SHA1算法的官方文档,(建议了解SHA1算法前,先了解下MD4 md4算法实现原理深剖 )其实现原理共分为5步:
第1步:字节填充(Append Padding Bytes)
数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数。
第2步:追加长度信息(Append Length)
数据比特位的数据长度追加到最后8字节中。【注意字节顺序与MD4不同 大小端之分】
第3步:初始化MD Buffer(Initialize MD Buffer)
这一步最简单了,定义ABCD四个4字节数组,分别赋初值即可。【注意相对于MD4 添加了H4】
uint32_t H0 = 0x67452301; // 0x01, 0x23, 0x45, 0x67
uint32_t H1 = 0xEFCDAB89; // 0x89, 0xAB, 0xCD, 0xEF
uint32_t H2 = 0x98BADCFE; // 0xFE, 0xDC, 0xBA, 0x98
uint32_t H3 = 0x10325476; // 0x76, 0x54, 0x32, 0x10
uint32_t H4 = 0xC3D2E1F0; // 0xF0, 0xE1, 0xD2, 0xC3
第4步:处理消息块(Process Message in 16-Byte Blocks)
这个是SHA1算法最核心的部分了,对第2步组装数据进行分块依次处理。
/* Process each 16-word block. */
For i = 0 to N/16-1 do
/* Copy block i into X. */
For j = 0 to 15 do
Set X[j] to M[i*16+j].
end /* of loop on j */
a. Divide M(i) into 16 words W(0), W(1), ... , W(15), where W(0) is the left-most word.
b. For t = 16 to 79 let
W(t) = S^1(W(t-3) XOR W(t-8) XOR W(t-14) XOR W(t-16)).
c. Let A = H0, B = H1, C = H2, D = H3, E = H4.
d. For t = 0 to 79 do
TEMP = S^5(A) + f(t;B,C,D) + E + W(t) + K(t);
E = D; D = C; C = S^30(B); B = A; A = TEMP;
e. Let H0 = H0 + A, H1 = H1 + B, H2 = H2 + C, H3 = H3 + D, H4 = H4 + E.
end /* of loop on i */第5步:输出(Output)
这一步也非常简单,只需要将计算后的H0、H1、H2、H3、H4进行拼接输出即可。
三、示例讲解
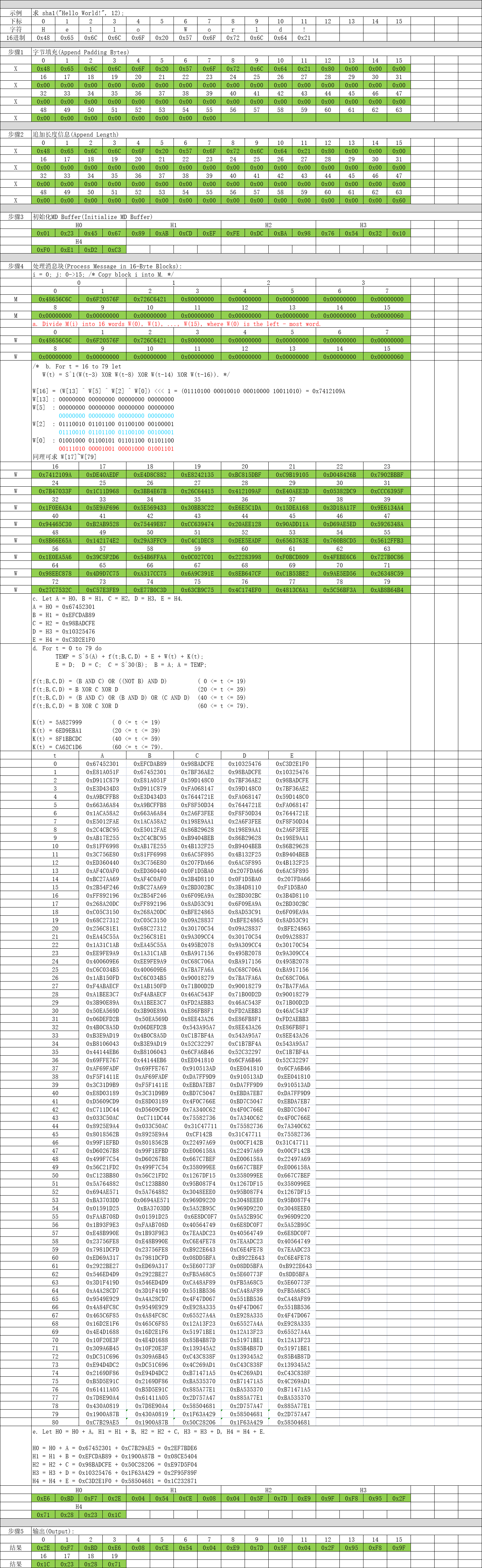
四、代码实现 以下为C/C++代码实现:
#include <string.h>
#include <stdio.h>
#define HASH_BLOCK_SIZE 64 /* 512 bits = 64 bytes */
#define HASH_LEN_SIZE 8 /* 64 bits = 8 bytes */
#define HASH_LEN_OFFSET 56 /* 64 bytes - 8 bytes */
#define HASH_DIGEST_SIZE 16 /* 128 bits = 16 bytes */
#define HASH_ROUND_NUM 80
typedef unsigned char uint8_t;
typedef unsigned short int uint16_t;
typedef unsigned int uint32_t;
typedef unsigned long long uint64_t;
/* Swap bytes in 32 bit value. 0x01234567 -> 0x67452301 */
#define __bswap_32(x) \
((((x) & 0xff000000) >> 24) \
| (((x) & 0x00ff0000) >> 8) \
| (((x) & 0x0000ff00) << 8) \
| (((x) & 0x000000ff) << 24))
/* SHA1 Constants */
static uint32_t K[4] =
{
0x5A827999, /* [0, 19] */
0x6ED9EBA1, /* [20, 39] */
0x8F1BBCDC, /* [40, 59] */
0xCA62C1D6 /* [60, 79] */
};
/* f(X, Y, Z) */
/* [0, 19] */
static uint32_t Ch(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) ^ ((~X) & Z);
}
/* [20, 39] */ /* [60, 79] */
static uint32_t Parity(uint32_t X, uint32_t Y, uint32_t Z)
{
return X ^ Y ^ Z;
}
/* [40, 59] */
static uint32_t Maj(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) ^ (X & Z) ^ (Y & Z);
}
/* 循环向左移动offset个比特位 */
static uint32_t MoveLeft(uint32_t X, uint8_t offset)
{
uint32_t res = (X << offset) | (X >> (32 - offset));
return res;
}
#define ASSERT_RETURN_INT(x, d) if(!(x)) { return d; }
int sha1(unsigned char *out, const unsigned char* in, const int inlen)
{
ASSERT_RETURN_INT(out && in && (inlen >= 0), 1);
int i = 0, j = 0, t = 0;
// step 1: 字节填充(Append Padding Bytes)
// 数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数
int iX = inlen / HASH_BLOCK_SIZE;
int iY = inlen % HASH_BLOCK_SIZE;
iX = (iY < HASH_LEN_OFFSET) ? iX : (iX + 1);
int iLen = (iX + 1) * HASH_BLOCK_SIZE;
unsigned char* X = malloc(iLen);
memcpy(X, in, inlen);
// 先补上1个1比特+7个0比特
X[inlen] = 0x80;
// 再补上(k-7)个0比特
for (i = inlen + 1; i < (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET); i++)
{
X[i] = 0;
}
// step 2: 追加长度信息(Append Length)
uint8_t *pLen = (uint64_t*)(X + (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET));
uint64_t iTempLen = inlen << 3;
uint8_t *pTempLen = &iTempLen;
pLen[0] = pTempLen[7]; pLen[1] = pTempLen[6]; pLen[2] = pTempLen[5]; pLen[3] = pTempLen[4];
pLen[4] = pTempLen[3]; pLen[5] = pTempLen[2]; pLen[6] = pTempLen[1]; pLen[7] = pTempLen[0];
// Step 3. 初始化MD Buffer(Initialize MD Buffer)
uint32_t H0 = 0x67452301; // 0x01, 0x23, 0x45, 0x67
uint32_t H1 = 0xEFCDAB89; // 0x89, 0xAB, 0xCD, 0xEF
uint32_t H2 = 0x98BADCFE; // 0xFE, 0xDC, 0xBA, 0x98
uint32_t H3 = 0x10325476; // 0x76, 0x54, 0x32, 0x10
uint32_t H4 = 0xC3D2E1F0; // 0xF0, 0xE1, 0xD2, 0xC3
uint32_t M[HASH_BLOCK_SIZE / 4] = { 0 };
uint32_t W[HASH_ROUND_NUM] = { 0 };
// step 4: 处理消息块(Process Message in 64-Byte Blocks)
for (i = 0; i < iLen / HASH_BLOCK_SIZE; i++)
{
/* Copy block i into X. */
for (j = 0; j < HASH_BLOCK_SIZE; j = j + 4)
{
uint64_t k = i * HASH_BLOCK_SIZE + j;
M[j / 4] = (X[k] << 24) | (X[k + 1] << 16) | (X[k + 2] << 8) | X[k + 3];
}
/* a. Divide M(i) into 16 words W(0), W(1), ..., W(15), where W(0) is the left - most word. */
for (t = 0; t <= 15; t++)
{
W[t] = M[t];
}
/* b. For t = 16 to 79 let
W(t) = S^1(W(t-3) XOR W(t-8) XOR W(t-14) XOR W(t-16)). */
for (t = 16; t <= 79; t++)
{
W[t] = MoveLeft(W[t - 3] ^ W[t - 8] ^ W[t - 14] ^ W[t - 16], 1);
}
/* c. Let A = H0, B = H1, C = H2, D = H3, E = H4. */
uint32_t A = H0;
uint32_t B = H1;
uint32_t C = H2;
uint32_t D = H3;
uint32_t E = H4;
/* d. For t = 0 to 79 do
TEMP = S^5(A) + f(t;B,C,D) + E + W(t) + K(t);
E = D; D = C; C = S^30(B); B = A; A = TEMP; */
for (t = 0; t <= 19; t++)
{
uint32_t temp = MoveLeft(A, 5) + Ch(B, C, D) + E + W[t] + K[0];
E = D;
D = C;
C = MoveLeft(B, 30);
B = A;
A = temp;
}
for (t = 20; t <= 39; t++)
{
uint32_t temp = MoveLeft(A, 5) + Parity(B, C, D) + E + W[t] + K[1];
E = D;
D = C;
C = MoveLeft(B, 30);
B = A;
A = temp;
}
for (t = 40; t <= 59; t++)
{
uint32_t temp = MoveLeft(A, 5) + Maj(B, C, D) + E + W[t] + K[2];
E = D;
D = C;
C = MoveLeft(B, 30);
B = A;
A = temp;
}
for (t = 60; t <= 79; t++)
{
uint32_t temp = MoveLeft(A, 5) + Parity(B, C, D) + E + W[t] + K[3];
E = D;
D = C;
C = MoveLeft(B, 30);
B = A;
A = temp;
}
/* e. Let H0 = H0 + A, H1 = H1 + B, H2 = H2 + C, H3 = H3 + D, H4 = H4 + E. */
H0 = H0 + A;
H1 = H1 + B;
H2 = H2 + C;
H3 = H3 + D;
H4 = H4 + E;
}
// step 5: 输出ABCD
uint32_t* pOut = (uint8_t*)out;
pOut[0] = __bswap_32(H0);
pOut[1] = __bswap_32(H1);
pOut[2] = __bswap_32(H2);
pOut[3] = __bswap_32(H3);
pOut[4] = __bswap_32(H4);
free(X);
return 0;
}
int main()
{
unsigned char digest[20] = { 0 };
sha1(digest, "Hello World!", strlen("Hello World!"));
return 0;
}2.2 SHA2-224 算法
原文来自:https://www.cnblogs.com/Kingfans/p/16572411.html
一、基本介绍
SHA (Security Hash Algorithm) 是美国的 NIST 和 NSA 设计的一种标准的 Hash 算法,SHA 用于数字签名的标准算法的 DSS 中,也是安全性很高的一种 Hash 算法。
SHA-1 是第一代 SHA 算法标准,后来的 SHA-224、SHA-256、SHA-384 和 SHA-512 被统称为 SHA-2。本文介绍SHA2-224算法的实现原理。
二、实现原理
有关 SHA2-224 算法详情请参见 NIST.FIPS.180-4 。

NIST.FIPS.180-4 是SHA2-224算法的官方文档,(建议了解SHA2-224算法前,先了解下SHA2-256 sha2-256算法实现原理深剖 )其实现原理共分为5步:
第1步:字节填充(Append Padding Bytes)
数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数。
第2步:追加长度信息(Append Length)
数据比特位的数据长度追加到最后8字节中。
第3步:初始化MD Buffer(Initialize MD Buffer)
这一步最简单了,定义ABCD四个4字节数组,分别赋初值即可。
uint32_t H0 = 0xC1059ED8;
uint32_t H1 = 0x367CD507;
uint32_t H2 = 0x3070DD17;
uint32_t H3 = 0xF70E5939;
uint32_t H4 = 0xFFC00B31;
uint32_t H5 = 0x68581511;
uint32_t H6 = 0x64F98FA7;
uint32_t H7 = 0xBEFA4FA4;第4步:处理消息块(Process Message in 16-Byte Blocks)
这个是SHA2-224算法最核心的部分了,对第2步组装数据进行分块依次处理。

第5步:输出(Output)
这一步也非常简单,只需要将计算后的H0、H1、H2、H3、H4、H5、H6进行拼接输出即可。
三、示例讲解
由于SHA2–224与SHA2-256算法完全一致,只是hash value初始赋值和输出结果不同。
具体示例讲解看参考SHA2-256示例讲解,此处不再重复。
四、代码实现
以下为C/C++代码实现:
#include <string.h>
#include <stdio.h>
#define HASH_BLOCK_SIZE 64 /* 512 bits = 64 bytes */
#define HASH_LEN_SIZE 8 /* 64 bits = 8 bytes */
#define HASH_LEN_OFFSET 56 /* 64 bytes - 8 bytes */
#define HASH_DIGEST_SIZE 16 /* 128 bits = 16 bytes */
#define HASH_ROUND_NUM 64
typedef unsigned char uint8_t;
typedef unsigned short int uint16_t;
typedef unsigned int uint32_t;
typedef unsigned long long uint64_t;
/* SHA256 Constants */
static const uint32_t K[HASH_ROUND_NUM] = {
0x428A2F98, 0x71374491, 0xB5C0FBCF, 0xE9B5DBA5,
0x3956C25B, 0x59F111F1, 0x923F82A4, 0xAB1C5ED5,
0xD807AA98, 0x12835B01, 0x243185BE, 0x550C7DC3,
0x72BE5D74, 0x80DEB1FE, 0x9BDC06A7, 0xC19BF174,
0xE49B69C1, 0xEFBE4786, 0x0FC19DC6, 0x240CA1CC,
0x2DE92C6F, 0x4A7484AA, 0x5CB0A9DC, 0x76F988DA,
0x983E5152, 0xA831C66D, 0xB00327C8, 0xBF597FC7,
0xC6E00BF3, 0xD5A79147, 0x06CA6351, 0x14292967,
0x27B70A85, 0x2E1B2138, 0x4D2C6DFC, 0x53380D13,
0x650A7354, 0x766A0ABB, 0x81C2C92E, 0x92722C85,
0xA2BFE8A1, 0xA81A664B, 0xC24B8B70, 0xC76C51A3,
0xD192E819, 0xD6990624, 0xF40E3585, 0x106AA070,
0x19A4C116, 0x1E376C08, 0x2748774C, 0x34B0BCB5,
0x391C0CB3, 0x4ED8AA4A, 0x5B9CCA4F, 0x682E6FF3,
0x748F82EE, 0x78A5636F, 0x84C87814, 0x8CC70208,
0x90BEFFFA, 0xA4506CEB, 0xBEF9A3F7, 0xC67178F2
};
/* Swap bytes in 32 bit value. 0x01234567 -> 0x67452301 */
#define __bswap_32(x) \
((((x) & 0xff000000) >> 24) \
| (((x) & 0x00ff0000) >> 8) \
| (((x) & 0x0000ff00) << 8) \
| (((x) & 0x000000ff) << 24))
static uint32_t Ch(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) ^ ((~X) & Z);
}
static uint32_t Maj(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) ^ (X & Z) ^ (Y & Z);
}
/* 循环向右移动offset个比特位 */
static uint32_t ROTR(uint32_t X, uint8_t offset)
{
uint32_t res = (X >> offset) | (X << (32 - offset));
return res;
}
/* 向右移动offset个比特位 */
static uint32_t SHR(uint32_t X, uint8_t offset)
{
uint32_t res = X >> offset;
return res;
}
/* SIGMA0 */
static uint32_t SIGMA0(uint32_t X)
{
return ROTR(X, 2) ^ ROTR(X, 13) ^ ROTR(X, 22);
}
/* SIGMA1 */
static uint32_t SIGMA1(uint32_t X)
{
return ROTR(X, 6) ^ ROTR(X, 11) ^ ROTR(X, 25);
}
/* sigma0, different from SIGMA0 */
static uint32_t sigma0(uint32_t X)
{
uint32_t res = ROTR(X, 7) ^ ROTR(X, 18) ^ SHR(X, 3);
return ROTR(X, 7) ^ ROTR(X, 18) ^ SHR(X, 3);
}
/* sigma1, different from SIGMA1 */
static uint32_t sigma1(uint32_t X)
{
return ROTR(X, 17) ^ ROTR(X, 19) ^ SHR(X, 10);
}
#define ASSERT_RETURN_INT(x, d) if(!(x)) { return d; }
int sha2_224(unsigned char *out, const unsigned char* in, const int inlen)
{
ASSERT_RETURN_INT(out && in && (inlen >= 0), 1);
int i = 0, j = 0, t = 0;
// step 1: 字节填充(Append Padding Bytes)
// 数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数
int iX = inlen / HASH_BLOCK_SIZE;
int iY = inlen % HASH_BLOCK_SIZE;
iX = (iY < HASH_LEN_OFFSET) ? iX : (iX + 1);
int iLen = (iX + 1) * HASH_BLOCK_SIZE;
unsigned char* X = malloc(iLen);
memcpy(X, in, inlen);
// 先补上1个1比特+7个0比特
X[inlen] = 0x80;
// 再补上(k-7)个0比特
for (i = inlen + 1; i < (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET); i++)
{
X[i] = 0;
}
// step 2: 追加长度信息(Append Length)
uint8_t *pLen = (uint64_t*)(X + (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET));
uint64_t iTempLen = inlen << 3;
uint8_t *pTempLen = &iTempLen;
pLen[0] = pTempLen[7]; pLen[1] = pTempLen[6]; pLen[2] = pTempLen[5]; pLen[3] = pTempLen[4];
pLen[4] = pTempLen[3]; pLen[5] = pTempLen[2]; pLen[6] = pTempLen[1]; pLen[7] = pTempLen[0];
// Step 3. 初始化MD Buffer(Initialize MD Buffer)
uint32_t H0 = 0xC1059ED8;
uint32_t H1 = 0x367CD507;
uint32_t H2 = 0x3070DD17;
uint32_t H3 = 0xF70E5939;
uint32_t H4 = 0xFFC00B31;
uint32_t H5 = 0x68581511;
uint32_t H6 = 0x64F98FA7;
uint32_t H7 = 0xBEFA4FA4;
uint32_t M[HASH_BLOCK_SIZE / 4] = { 0 };
uint32_t W[HASH_ROUND_NUM] = { 0 };
// step 4: 处理消息块(Process Message in 64-Byte Blocks)
for (i = 0; i < iLen / HASH_BLOCK_SIZE; i++)
{
/* Copy block i into M. */
for (j = 0; j < HASH_BLOCK_SIZE; j = j + 4)
{
uint64_t k = i * HASH_BLOCK_SIZE + j;
M[j / 4] = (X[k] << 24) | (X[k + 1] << 16) | (X[k + 2] << 8) | X[k + 3];
}
/* W[t]=M[t]; t:[0,15] */
for (t = 0; t <= 15; t++)
{
W[t] = M[t];
}
/* W[t] = sigma1(W[t - 2]) + W[t - 7] + sigma0(W[t - 15]) + W[t - 16]; t:[16,63] */
for (t = 16; t < HASH_ROUND_NUM; t++)
{
W[t] = sigma1(W[t - 2]) + W[t - 7] + sigma0(W[t - 15]) + W[t - 16];
}
uint32_t A = H0;
uint32_t B = H1;
uint32_t C = H2;
uint32_t D = H3;
uint32_t E = H4;
uint32_t F = H5;
uint32_t G = H6;
uint32_t H = H7;
for (t = 0; t < HASH_ROUND_NUM; t++)
{
uint32_t T1 = H + SIGMA1(E) + Ch(E, F, G) + K[t] + W[t];
uint32_t T2 = SIGMA0(A) + Maj(A, B, C);
H = G;
G = F;
F = E;
E = D + T1;
D = C;
C = B;
B = A;
A = T1 + T2;
}
H0 = H0 + A;
H1 = H1 + B;
H2 = H2 + C;
H3 = H3 + D;
H4 = H4 + E;
H5 = H5 + F;
H6 = H6 + G;
H7 = H7 + H;
}
// step 5: 输出
uint32_t* pOut = (uint8_t*)out;
pOut[0] = __bswap_32(H0);
pOut[1] = __bswap_32(H1);
pOut[2] = __bswap_32(H2);
pOut[3] = __bswap_32(H3);
pOut[4] = __bswap_32(H4);
pOut[5] = __bswap_32(H5);
pOut[6] = __bswap_32(H6);
free(X);
return 0;
}
int main()
{
unsigned char digest[28] = { 0 };
sha2_224(digest, "Hello World!", strlen("Hello World!"));
return 0;
}2.3 SHA2-256 算法
原文来自:https://www.cnblogs.com/Kingfans/p/16571435.html
一、基本介绍
SHA (Security Hash Algorithm) 是美国的 NIST 和 NSA 设计的一种标准的 Hash 算法,SHA 用于数字签名的标准算法的 DSS 中,也是安全性很高的一种 Hash 算法。
SHA-1 是第一代 SHA 算法标准,后来的 SHA-224、SHA-256、SHA-384 和 SHA-512 被统称为 SHA-2。本文介绍SHA2-256算法的实现原理。
二、实现原理
有关 SHA2-256 算法详情请参见 NIST.FIPS.180-4 。

NIST.FIPS.180-4 是SHA2-256算法的官方文档,(建议了解SHA2-256算法前,先了解下SHA1 sha1算法实现原理深剖 )其实现原理共分为5步:
第1步:字节填充(Append Padding Bytes)
数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数。
第2步:追加长度信息(Append Length)
数据比特位的数据长度追加到最后8字节中。【以上与sha1完全一致】
第3步:初始化MD Buffer(Initialize MD Buffer)
这一步最简单了,定义ABCD四个4字节数组,分别赋初值即可。
uint32_t H0 = 0x6A09E667;
uint32_t H1 = 0xBB67AE85;
uint32_t H2 = 0x3C6EF372;
uint32_t H3 = 0xA54FF53A;
uint32_t H4 = 0x510E527F;
uint32_t H5 = 0x9B05688C;
uint32_t H6 = 0x1F83D9AB;
uint32_t H7 = 0x5BE0CD19;第4步:处理消息块(Process Message in 16-Byte Blocks)
这个是SHA2-256算法最核心的部分了,对第2步组装数据进行分块依次处理。

第5步:输出(Output)
这一步也非常简单,只需要将计算后的H0、H1、H2、H3、H4、H5、H6、H7进行拼接输出即可。
三、示例讲解
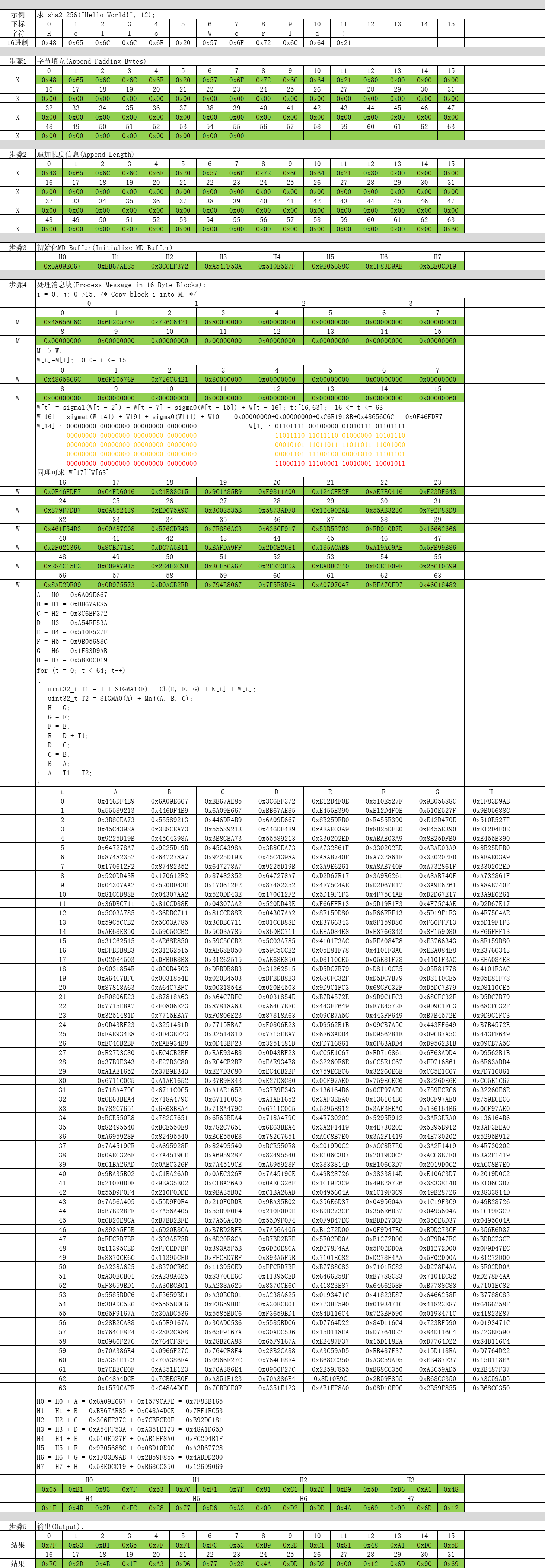
四、代码实现
以下为C/C++代码实现:
#include <string.h>
#include <stdio.h>
#define HASH_BLOCK_SIZE 64 /* 512 bits = 64 bytes */
#define HASH_LEN_SIZE 8 /* 64 bits = 8 bytes */
#define HASH_LEN_OFFSET 56 /* 64 bytes - 8 bytes */
#define HASH_DIGEST_SIZE 16 /* 128 bits = 16 bytes */
#define HASH_ROUND_NUM 64
typedef unsigned char uint8_t;
typedef unsigned short int uint16_t;
typedef unsigned int uint32_t;
typedef unsigned long long uint64_t;
/* SHA256 Constants */
static const uint32_t K[HASH_ROUND_NUM] = {
0x428A2F98, 0x71374491, 0xB5C0FBCF, 0xE9B5DBA5,
0x3956C25B, 0x59F111F1, 0x923F82A4, 0xAB1C5ED5,
0xD807AA98, 0x12835B01, 0x243185BE, 0x550C7DC3,
0x72BE5D74, 0x80DEB1FE, 0x9BDC06A7, 0xC19BF174,
0xE49B69C1, 0xEFBE4786, 0x0FC19DC6, 0x240CA1CC,
0x2DE92C6F, 0x4A7484AA, 0x5CB0A9DC, 0x76F988DA,
0x983E5152, 0xA831C66D, 0xB00327C8, 0xBF597FC7,
0xC6E00BF3, 0xD5A79147, 0x06CA6351, 0x14292967,
0x27B70A85, 0x2E1B2138, 0x4D2C6DFC, 0x53380D13,
0x650A7354, 0x766A0ABB, 0x81C2C92E, 0x92722C85,
0xA2BFE8A1, 0xA81A664B, 0xC24B8B70, 0xC76C51A3,
0xD192E819, 0xD6990624, 0xF40E3585, 0x106AA070,
0x19A4C116, 0x1E376C08, 0x2748774C, 0x34B0BCB5,
0x391C0CB3, 0x4ED8AA4A, 0x5B9CCA4F, 0x682E6FF3,
0x748F82EE, 0x78A5636F, 0x84C87814, 0x8CC70208,
0x90BEFFFA, 0xA4506CEB, 0xBEF9A3F7, 0xC67178F2
};
/* Swap bytes in 32 bit value. 0x01234567 -> 0x67452301 */
#define __bswap_32(x) \
((((x) & 0xff000000) >> 24) \
| (((x) & 0x00ff0000) >> 8) \
| (((x) & 0x0000ff00) << 8) \
| (((x) & 0x000000ff) << 24))
static uint32_t Ch(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) ^ ((~X) & Z);
}
static uint32_t Maj(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) ^ (X & Z) ^ (Y & Z);
}
/* 循环向右移动offset个比特位 */
static uint32_t ROTR(uint32_t X, uint8_t offset)
{
uint32_t res = (X >> offset) | (X << (32 - offset));
return res;
}
/* 向右移动offset个比特位 */
static uint32_t SHR(uint32_t X, uint8_t offset)
{
uint32_t res = X >> offset;
return res;
}
/* SIGMA0 */
static uint32_t SIGMA0(uint32_t X)
{
return ROTR(X, 2) ^ ROTR(X, 13) ^ ROTR(X, 22);
}
/* SIGMA1 */
static uint32_t SIGMA1(uint32_t X)
{
return ROTR(X, 6) ^ ROTR(X, 11) ^ ROTR(X, 25);
}
/* sigma0, different from SIGMA0 */
static uint32_t sigma0(uint32_t X)
{
uint32_t res = ROTR(X, 7) ^ ROTR(X, 18) ^ SHR(X, 3);
return ROTR(X, 7) ^ ROTR(X, 18) ^ SHR(X, 3);
}
/* sigma1, different from SIGMA1 */
static uint32_t sigma1(uint32_t X)
{
return ROTR(X, 17) ^ ROTR(X, 19) ^ SHR(X, 10);
}
#define ASSERT_RETURN_INT(x, d) if(!(x)) { return d; }
int sha2_256(unsigned char *out, const unsigned char* in, const int inlen)
{
ASSERT_RETURN_INT(out && in && (inlen >= 0), 1);
int i = 0, j = 0, t = 0;
// step 1: 字节填充(Append Padding Bytes)
// 数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数
int iX = inlen / HASH_BLOCK_SIZE;
int iY = inlen % HASH_BLOCK_SIZE;
iX = (iY < HASH_LEN_OFFSET) ? iX : (iX + 1);
int iLen = (iX + 1) * HASH_BLOCK_SIZE;
unsigned char* X = malloc(iLen);
memcpy(X, in, inlen);
// 先补上1个1比特+7个0比特
X[inlen] = 0x80;
// 再补上(k-7)个0比特
for (i = inlen + 1; i < (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET); i++)
{
X[i] = 0;
}
// step 2: 追加长度信息(Append Length)
uint8_t *pLen = (uint64_t*)(X + (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET));
uint64_t iTempLen = inlen << 3;
uint8_t *pTempLen = &iTempLen;
pLen[0] = pTempLen[7]; pLen[1] = pTempLen[6]; pLen[2] = pTempLen[5]; pLen[3] = pTempLen[4];
pLen[4] = pTempLen[3]; pLen[5] = pTempLen[2]; pLen[6] = pTempLen[1]; pLen[7] = pTempLen[0];
// Step 3. 初始化MD Buffer(Initialize MD Buffer)
uint32_t H0 = 0x6A09E667;
uint32_t H1 = 0xBB67AE85;
uint32_t H2 = 0x3C6EF372;
uint32_t H3 = 0xA54FF53A;
uint32_t H4 = 0x510E527F;
uint32_t H5 = 0x9B05688C;
uint32_t H6 = 0x1F83D9AB;
uint32_t H7 = 0x5BE0CD19;
uint32_t M[HASH_BLOCK_SIZE / 4] = { 0 };
uint32_t W[HASH_ROUND_NUM] = { 0 };
// step 4: 处理消息块(Process Message in 64-Byte Blocks)
for (i = 0; i < iLen / HASH_BLOCK_SIZE; i++)
{
/* Copy block i into M. */
for (j = 0; j < HASH_BLOCK_SIZE; j = j + 4)
{
uint64_t k = i * HASH_BLOCK_SIZE + j;
M[j / 4] = (X[k] << 24) | (X[k + 1] << 16) | (X[k + 2] << 8) | X[k + 3];
}
/* W[t]=M[t]; t:[0,15] */
for (t = 0; t <= 15; t++)
{
W[t] = M[t];
}
/* W[t] = sigma1(W[t - 2]) + W[t - 7] + sigma0(W[t - 15]) + W[t - 16]; t:[16,63] */
for (t = 16; t < HASH_ROUND_NUM; t++)
{
W[t] = sigma1(W[t - 2]) + W[t - 7] + sigma0(W[t - 15]) + W[t - 16];
}
uint32_t A = H0;
uint32_t B = H1;
uint32_t C = H2;
uint32_t D = H3;
uint32_t E = H4;
uint32_t F = H5;
uint32_t G = H6;
uint32_t H = H7;
for (t = 0; t < HASH_ROUND_NUM; t++)
{
uint32_t T1 = H + SIGMA1(E) + Ch(E, F, G) + K[t] + W[t];
uint32_t T2 = SIGMA0(A) + Maj(A, B, C);
H = G;
G = F;
F = E;
E = D + T1;
D = C;
C = B;
B = A;
A = T1 + T2;
//printf("t=%02d:\t 0x%02X\t\t 0x%02X\t\t 0x%02X\t\t 0x%02X\t\t \n", t, E, F, G, H);
}
H0 = H0 + A;
H1 = H1 + B;
H2 = H2 + C;
H3 = H3 + D;
H4 = H4 + E;
H5 = H5 + F;
H6 = H6 + G;
H7 = H7 + H;
}
// step 5: 输出
uint32_t* pOut = (uint8_t*)out;
pOut[0] = __bswap_32(H0);
pOut[1] = __bswap_32(H1);
pOut[2] = __bswap_32(H2);
pOut[3] = __bswap_32(H3);
pOut[4] = __bswap_32(H4);
pOut[5] = __bswap_32(H5);
pOut[6] = __bswap_32(H6);
pOut[7] = __bswap_32(H7);
free(X);
return 0;
}
int main()
{
unsigned char digest[32] = { 0 };
sha2_256(digest, "Hello World!", strlen("Hello World!"));
return 0;
}2.4 SHA2-384 算法
原文来自
2.5 SHA2-512 算法
原文来自
3.3 CRC 哈希函数
简介
CRC的全称为 Cyclic Redundancy Check,中文名称为循环冗余校验。它是一类重要的线性分组码,编码和解码方法简单,检错和纠错能力强,在通信领域广泛地用于实现差错控制。
实际上,除数据通信外,CRC在其它很多领域也是大有用武之地的。例如我们读软盘上的文件,以及解压一个ZIP文件时,偶尔会碰到“Bad CRC”错误,由此它在数据存储方面的应用可略见一斑。
CRC 系列算法
2.4 快速位算法
位运算符
- & 位与: 0 & 0 = 0 ; 0 & 1 = 0 ; 1 & 0 = 0 ;1 & 1 = 1 ; 同为 1 时, 结果为 1。
- | 位或: 0 | 0 = 0 ; 0 | 1 = 1 ; 1 | 0 = 1 ;1 | 1 = 1 ; 存在 1 时, 结果为 1。
- ^ 位异或: 0 & 0 = 0 ; 0 & 1 = 1 ; 1 & 0 = 1 ;1 & 1 = 0 ; 值相异时, 结果为 1。
- ~ 位反: ~ 0 = 1 ; ~ 1 = 0 ;
- « 左移:
- >> 逻辑右移:
- >» 算术右移:
位运算特性
与(&)运算
一个数n与0进行与运算,值为0,n & 0 = 0。
一个数n与-1进行与运算,值为n,n & -1 = n。
一个数n与自己进行与运算,值为n,n & n = n。
或(|)运算
一个数n与0进行或运算,值为n,n | 0 = n。
一个数n与-1进行或运算,值为-1,n | -1 = -1。
非(~)运算
对二进制的每一位都按位取反。
对于数n,n + (~n) = -1。
异或(^)运算
运算的二进位结果,相异为1,相同为0。
一个数n与0异或,值为n,n ^ 0 = n。
一个数n与-1异或,值为~n,n ^ -1 = ~n。
一个数n与自己异或,值为0,n ^ n = 0。
左移(«)和右移(»)运算
向左进行移位操作,高位丢弃,低位补 0
向右进行移位操作,对无符号数,高位补 0,对于有符号数,高位补符号位
应用
快速位算法 的子部分
4.1 快速平均值
符号定义
- a :待运算的值
- b :待运算的值
- r :运算结果
计算
r = (a + b) >> 1
总结
>> 1 ,相当于 除 2。
4.2 位域值提取
位域定义
C语言中的位域定义:
struct Bits{
uint32_t b2:2;
uint32_t b4:4;
};提取位域定义的值算法如下:
符号定义:
- w :定义的位宽,如 b2 的位宽为 2 bit;
- p :位域字段的位偏移,如 b2 的位偏移为 0,b4 的位偏移为 2;
- v :位域字段所在的整体数据值,如 b2 就在 uint32_t 的数据上;
- r :计算的结果;
第1步:计算位域掩码
mask = (1 << w) - 1
第2步:逻辑右移
tv = v >> p
第3步:截取域至
v = tv & mask
总结
r = (v >> p) & ( (1 << w) - 1)
如果v是有符号数,就需要进行符号扩展。
符号扩展
第1步:计算符号掩码
smask = 1 << (w-1)
第2步:计算符号位值
signed = r & smask
第3步:符号扩展
signed != 0 ? ( r = r | (-1 « w) ) : r
总结
( (1 « (w-1)) & r) != 0 ? ( r = r | (-1 « w) ) : r
4.3 INT_MAX和INT_MIN
假设
假设您有一个 32 位系统:
- INT_MAX是 01111111111111111111111111111111 ;
- INT_MIN是 10000000000000000000000000000000 ;
0 和 1 分别位于最高有效位位置,分别表示符号位。
计算INT_MAX和INT_MIN 在 C/C++ 中: 数字 0 表示为 000…000(32个)。
原理
我们计算 0 的 NOT 得到一个有 32 个 1 的数字。这个数字不等于INT_MAX因为符号位是1,即负数。 现在,这个数字的右移将产生011…111 这是INT_MAX。 将INT_MAX 按位取反 就得到INT_MIN。
代码
unsigned int max = 0;
max = ~max;
max = max >> 1;
int min = ~max;
4.4 应用 n + (~n) = -1
原理
设整数 n 类型为 int_8,值为 3,则 3 + (~3) = 0000 0011 + 1111 1100 = 1111 1111 = -1,所以引出非运算的基础公式 n + (~n) = -1,也可以将 n ^ -1 = ~n 带入。
位运算实现n+1与n-1
对n + (~n) = -1进行等式变换可得:
int n;
~n = -(n + 1);
n + 1 = -~n;
n - 1 = ~-n; // 假设n = -n,可推出此等式
取相反数
一个数的相反数等于其按位取反后再加1,对上等式变换推出:
int n;
-n = ~n + 1;取绝对值
这一块内容也用到了n ^ 0 = n 和 n ^ -1 = ~n:
- 若 n 为非负数,则 n » 31 = 0,所以 abs = n ^ 0 - 0 = n。
- 若 n 为负数,则 n » 31 = -1,所以 abs = n ^ (-1) + 1 = ~n + 1 = -1 - n + 1 = -n。
int abs, n;
abs = (n ^ (n >> 31)) - (n >> 31)4.5 应用 n ^ n = 0 和 n ^ 0 = n
交换两个数的值
不需要第三个临时变量,交换两个数的值
int a, b;
a ^= b; // a = a ^ b;
b ^= a; // b = b ^ a = b ^ a ^ b = (b ^ b) ^ a = 0 ^ a = a
a ^= b; // a = a ^ b = a ^ a ^ b = 0 ^ b = b
代替特定的条件赋值
如果 x = a,则 a ^ b ^ x = 0 ^ b;如果 x = b,则 a ^ b ^ x = 0 ^ a;
所以下列代码可等价于:x = a ^ b ^ x。
int a, b, x;
if(x == a)
x = b;
else if(x == b)
x = a;
// 上面代码等价于
x = a ^ b ^ x4.6 应用 x&(x-1)
原理
x&(x-1)可以消除数字x二进制表示的最后一个1,如:
int x = 0xf6;
printf("%x\n", x); //0b11110110
printf("%x\n", x&(x-1)); //0b11110100
判断一个正数是不是2的次幂
如果一个正数是2的次幂,则这个数的二进制表示中只含有一个1。
int x;
if(x&(x-1)){
//x至少含有两个1,所以不是2的次幂
}
计算一个数的二进制含有多少个1
x中的最后一个1可以通过操作x = x&(x-1)循环消去,当最后x值为0时,便可以求出二进制中1的个数。
int x, total;
while(x > 0){
x = x&(x-1);
total++;
}4.7 应用 2的次方
整数对2的乘/除法
整数 n 向右移一位,相当于将 n 除以 2;数 n 向左移一位,相当于将 n 乘以 2。
int n = 2;
n >> 1; // 1
n << 1; // 4
n 对“2的次方”取余
m 是2的次方,则其二进制数只有一个1,如 4 => 0100,8 => 1000。m-1 之后,原本 m 二进制的1变成0,原本1后面的0全变成1,如 4-1 = 3 => 0011,8-1 = 7 => 0111。
2 ^ 0 = 1
2 ^ 1 = 2
2 ^ 2 = 4
2^ 3 = 8
2 ^ 4 = 16
2 ^ 5 = 32
…
可以看出 2^(q + 1) 永远都是 2^q 的整数倍,而 2^q 比 2^(q - 1)+2^(q - 2) … + 2^0 的和还要大 1。
假设 m = 2^q ,q 为正整数。n 的二进制数中,第[ n 的最高位, q ]位的和是 m 的整数倍,而第[ q-1, 0 ]位的和是 n/m 的余数,也就是说将n的二进制数的第[ q-1, 0 ]位截取,即可得到 n/m 的余数。
m = 2^q , m − 1 = 2^(q - 1)+2^(q - 2) … + 2^0 => 00011…1([ q-1, 0 ]位全为1),所以 n & (m - 1) 的值为 n/m 的余数。
int mod, n, m; // m是2的次方,如4,8等
mod = n & (m - 1);将 n 以“2的次方”倍数最小补全
有 n 和 m 两数,m 为2的次方,找到大于等于 n 且正好是 m 整数倍的最小数。
假设 m = 2^q ,则 m 的倍数的二进制数中,第 q 位为1,其余位全为 0;(m - 1) 的二进制数中[ q-1, 0 ]位全为 1,其余位全为 0。
所以有两种情况:
- 如果n的二进制数中[ q-1, 0 ]位全为 0,则 n 就是 m 整数倍的最小数;
- 如果n的二进制数中[ q-1, 0 ]位不全为 0,在第 q 位上加 1,所得结果就是 m 整数倍的最小数。
现给 n 加上一个[ q-1, 0 ]位全为 1,其余位全为 0 的数( m-1 就是这个数),并将所得结果的[ q-1, 0 ]位全部置为 0(结果与 ~(m - 1) 相与即可),便可满足这两种情况。
int min, n, m;
min = (n + m - 1) & ~(m - 1);4.8 取两数的最 大/小 值
原理
- 如果 a >= b,则 a - b >= 0 且
(a - b) < 0,所以 ((a - b) » 31) = 0 且 ((a - b) » 31) = -1。 - 如果 a < b,则 a - b < 0 且
(a - b) >= 0,所以 ((a - b) » 31) = -1 且 ((a - b) » 31) = 0。
实现
int max(int a, int b){
return (b & ((a - b) >> 31)) | (a & (~(a - b) >> 31));
}
int min(int a, int b){
return (a & ((a - b) >> 31)) | (b & (~(a - b) >> 31));
}4.9 循环移位
循环左移
以32位整数为例,循环左移的过程可以分为3步:
- 将 x 左端的 n 位先移动到 y 的低 n 位中,x » (32-n);
- 将 x 左移 n 位,其右面低位补 0,x«n;
- 进行按位或运算(x » (32 - n) | (x « n));
循环右移
以32位整数为例,循环右移的过程可以分为3步:
- 将 x 的左端的低 n 位先移动到 y 的高 n 位中 x « (32 - n)
- 将 x 右移 n 位,其左面高 n 位补 0,x » n;
- 进行按位或操作(x « (32 - n) | (x » n));
总结
假如将一个无符号的数据 val ,长度为 N bit,需要循环移动 n bit。可以利用下面的公式:
循环左移:(val >> (N - n) | (val << n))
循环右移:(val << (N - n) | (val >> n))
- 注:n ->[0,N-1],所以 在运算之前,将 n 映射到该范围: n = n & ( N - 1 )
实现
//循环左移
unsigned int ROL(unsigned int val,unsigned int n){
n&=31;
return (val >> (32 - n) | (val << n));
}
//循环右移
unsigned int ROL(unsigned int val,unsigned int n){
n&=31;
return (val << (32 - n) | (val >> n));
}3 自主项目
本章节将列出自我实现的一些实践项目。
目录
自主项目 的子部分
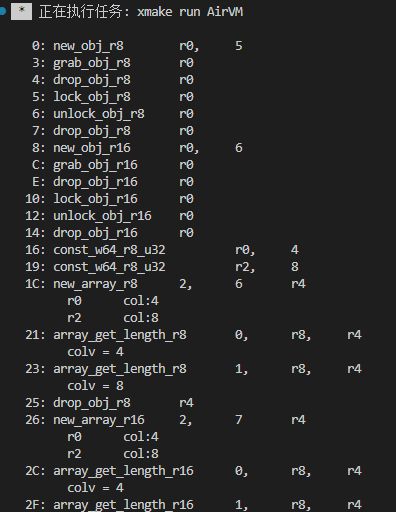
3.1 虚拟机设计与实现
项目地址:https://github.com/irscript/AirVM
- 基于纯寄存器的虚拟机。
- 支持本地函数调用。
- 参照安卓 dalvik 设计。
运行截图:
3.2 编译器设计与实现
项目地址:https://gitee.com/irscript/airlang
- c 系语法。
- 前端基本实现。
- 中端优化未实现。
- 汇编代码生成未实现。
- 可作为参考示例。
语法树打印
dump: parser.air
package Test{
main(
arg string[] final
) int32
{
i int32 =
0
;
j int32 =
1
;
f flt32 =
0
;
f2 flt32 =
0
;
ires int32 =
i
+
j
;
fres flt32 =
f2
+
f
;
i16 int16 =
0
;
u16 uint16 =
0
;
i32 int32 =
i16
+
u16
;
i32
++
;
return
0
;
}
}类型分析
dump: parser.air
package Test{
@static
@public
main(
arg string[] final
) int32
{
i int32 =
0 :T= int32
;
j int32 =
1 :T= int32
;
f flt32 =
0.000000 :T= flt32
;
f2 flt32 =
0.000000 :T= flt32
;
ires int32 =
i :T= int32
+
j :T= int32
:T= int32
;
fres flt32 =
f2 :T= flt32
+
f :T= flt32
:T= flt32
;
i16 int16 =
0 :T= int16
;
u16 uint16 =
0 :T= uint16
;
i32 int32 =
cast<
int32
>(
i16 :T= int16
)
+
cast<
int32
>(
u16 :T= uint16
)
:T= int32
;
i32 :T= int32
++
:T= int32
;
return
0 :T= int32
;
}
}IR 转换
Test.main(string[] final)int32
{
def-arg arg : string[] final
%$entry:
{
def-var i : int32
assign<i32> 0 => i
def-var j : int32
assign<i32> 1 => j
def-var f : flt32
assign<f32> 0.000000 => f
def-var f2 : flt32
assign<f32> 0.000000 => f2
def-var ires : int32
def-var %0 : int32
add<i32> i, j => %0
assign<i32> %0 => ires
def-var fres : flt32
def-var %1 : flt32
add<f32> f2, f => %1
assign<f32> %1 => fres
def-var i16 : int16
assign<i16> 0 => i16
def-var u16 : uint16
assign<u16> 0 => u16
def-var i32 : int32
def-var %2 : int32
extend<i16=>i32> i16 => %2
def-var %3 : int32
extend<u16=>i32> u16 => %3
def-var %4 : int32
add<i32> %2, %3 => %4
assign<i32> %4 => i32
def-var %5 : int32
assign<i32> i32 => %5
inc<i32> i32 => i32
return<i32> 0
}
%$end:
}待续
3.3 GUI设计与实现
基于opengl的的GUI库设计和实现。 项目地址:https://gitee.com/irscript/gui
- 支持中文输入。
- 主题可配置。
- 当前仅是个demo。
- 支持utf8编码。
运行截图:
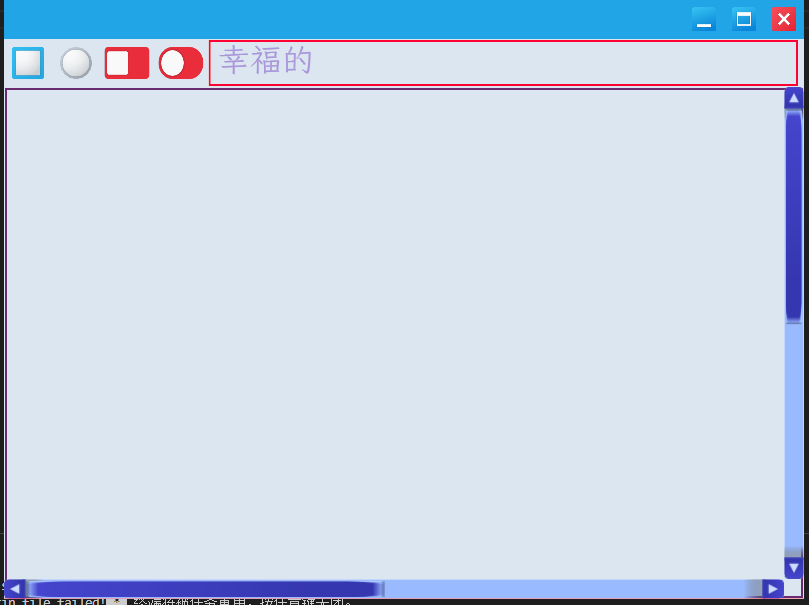
3.4 工具设计与实现
时常需要一些小工具,来完成一些功能,故特此开发一些工具。
项目地址:https://gitee.com/irscript/ToolSet
- 详情查看代码!
国际化翻译
多语言映射编译工具
把符合定义规范的文件编译成 C语言代码和自定义二进制文件
输入命令行格式: i18n -i infile infile2 -o outfile [-c] [-t]
-i :指示后面是输入文件
-o :指示后面是输出文件
-c :指示编译格式,无 -c 时,表示编译成二进制格式,否则编译成C语言代码
-t :指示强制分配枚举值,同时生成的C语言代码中只有枚举字符串的值
-v :只是文件的版本号
输入文件格式
枚举名称,枚举值,字符串
menu_edit, 1 , "编辑"
menu_copy, 2 , "复制"
注:
#字符开始的一行会被跳过
文本编码最好为 UTF-8 编码
枚举值为0或者为空时,表示自动分配枚举值
输出文件格式
代码文件
枚举声明文件
enum{ menu_edit=1, menu_copy=2,};
静态数组文件
cstring gTslArr[]={"编辑","复制"}
kuint32 gTslEnum[]={menu_edit,menu_copy,};
二进制文件格式
-------------------------------------------------------------------
| 文件头 | 单元偏移数组 |EMS翻译单元 | EMS翻译单元 | ... |
-------------------------------------------------------------------
注:填充整数时采用字节序列为 小端 的顺序
文件头:
魔数:4 byte 为 i18n 字母的值
哈希值:4 byte crc32 文件内容的哈希值
翻译版本:4 byte 无符号,表示翻译文件版本号
EMS总数:4 byte 无符号,表示翻译单元的总数
枚举值是否连续: 4 byte 无符号,表示枚举值是否连续
翻译数据大小:4 byte 无符号,表示翻译数据的总大小
EMS翻译单元格式
枚举值:4 byte 无符号
字符串长度:2 byte 无符号,包括 null 字符
字符串数据:0xFFFF 长的字符串数据,编码和文本编码一致(建议文本采用UTF-8编码),两字节对齐自解压
window平台下的自解压原理案例,可用于实现自定义安装包。
文件转2进制
将文件转成C语言代码。
4 工具手册
工具手册 的子部分
4.1 主题简码
主题简码 的子部分
1.1 徽章(badge)
徽章(badge)简码用于在文本中显示小标记,颜色、标题和图标,可调整。
用法
{{% badge %}}重要{{% /badge %}}
{{% badge style="primary" title="版本" %}}6.6.6{{% /badge %}}
{{% badge style="red" icon="angle-double-up" %}}船长{{% /badge %}}
{{% badge style="info" %}}新增{{% /badge %}}
{{% badge color="fuchsia" icon="fab fa-hackerrank" %}}超棒!{{% /badge %}}参数
| 名称 | 注释 |
|---|---|
| style | 徽章使用的样式方案。 - 严重程度: info, note, tip, warning- 印记颜色: primary, secondary, accent- 颜色: blue, green, grey, orange, red- 特殊颜色: default, transparent, code |
| color | 要使用的 CSS 颜色值。如果未设置,则选择的颜色取决于样式。任何给定的值都将覆盖默认值。 - 对于严重性样式:严重性匹配的漂亮颜色 - 对于所有其他样式:相应的颜色 |
| title | 屏幕提醒标题的任意文本。根据样式的不同,可能会有一个默认标题。任何给定的值都将覆盖默认值。 - 对于严重性样式:严重性匹配的标题 - 对于所有其他样式:<空> 如果您不希望严重性样式的标题,则必须将此参数设置为 " "(一个充满空格的非空字符串)。 |
| icon | Font Awesome icon name 设置在标题的左侧。根据样式的不同,可能会有一个默认图标。任何给定的值都将覆盖默认值。 - 对于严重性样式:严重性匹配的漂亮图标 - 对于所有其他样式:<空> 如果您不想为严重性样式使用图标,则必须将此参数设置为 " "(填充空格的非空字符串) |
| <txt> | 任意文本,可以为 <空> |
案例
样式
严重性样式
{{% badge style="info" %}}New{{% /badge %}}
{{% badge style="note" %}}Change{{% /badge %}}
{{% badge style="tip" %}}Optional{{% /badge %}}
{{% badge style="warning" %}}Breaking{{% /badge %}}印记样式
{{% badge style="primary" icon="bullhorn" title="Announcement" %}}命令{{% /badge %}}
{{% badge style="secondary" icon="bullhorn" title="Announcement" %}}选项{{% /badge %}}
{{% badge style="accent" icon="bullhorn" title="Announcement" %}}专辑{{% /badge %}}颜色样式
{{% badge style="blue" icon="palette" title="Color" %}}蓝色{{% /badge %}}
{{% badge style="green" icon="palette" title="Color" %}}绿色{{% /badge %}}
{{% badge style="grey" icon="palette" title="Color" %}}灰色{{% /badge %}}
{{% badge style="orange" icon="palette" title="Color" %}}橘色{{% /badge %}}
{{% badge style="red" icon="palette" title="Color" %}}红色{{% /badge %}}特殊颜色
{{% badge style="default" icon="palette" title="Color" %}}默认色{{% /badge %}}
{{% badge style="transparent" icon="palette" title="Color" %}}透明色{{% /badge %}}变体
没有图标和标题
{{% badge %}}6.6.6{{% /badge %}}
{{% badge style="info" icon=" " title=" " %}}Awesome{{% /badge %}}
{{% badge style="red" %}}Captain{{% /badge %}}没有图标
{{% badge title="Version" %}}6.6.6{{% /badge %}}
{{% badge style="info" icon=" " %}}Awesome{{% /badge %}}
{{% badge style="red" title="Rank" %}}Captain{{% /badge %}}没有标题
{{% badge icon="star" %}}6.6.6{{% /badge %}}
{{% badge style="info" title=" " %}}Awesome{{% /badge %}}
{{% badge style="red" icon="angle-double-up" %}}Captain{{% /badge %}}有标题和图标
{{% badge icon="star" title="Version" %}}6.6.6{{% /badge %}}
{{% badge style="info" %}}Awesome{{% /badge %}}
{{% badge style="red" icon="angle-double-up" title="Rank" %}}Captain{{% /badge %}}1.2 按钮(button)
按钮(button)简码显示一个可点击的按钮,颜色、标题和图标可调整。
用法
{{% button href="https://gohugo.io/" %}}Get Hugo{{% /button %}}
{{% button href="https://gohugo.io/" style="warning" icon="dragon" %}}Get Hugo{{% /button %}}单击该按钮后,它将为给定的 URL 打开另一个浏览器选项卡。
参数
| 名称 | 默认 | 描述 |
|---|---|---|
| href | 链接地址 | |
| style | transparent | 徽章使用的样式方案。 - 严重程度: info, note, tip, warning- 印记颜色: primary, secondary, accent- 颜色: blue, green, grey, orange, red- 特殊颜色: default, transparent, code |
| color | 要使用的 CSS 颜色值。如果未设置,则选择的颜色取决于样式。任何给定的值都将覆盖默认值。 - 对于严重性样式:严重性匹配的漂亮颜色 - 对于所有其他样式:相应的颜色 | |
| icon | Font Awesome icon name 设置在标题的左侧。根据样式的不同,可能会有一个默认图标。任何给定的值都将覆盖默认值。 - 对于严重性样式:严重性匹配的漂亮图标 - 对于所有其他样式:<空> 如果您不想为严重性样式使用图标,则必须将此参数设置为 " "(填充空格的非空字符串) | |
| iconposition | left | 设置图标的位置。 - left :图标在标题的左侧。- right:图标在标题的右侧。 |
| target | 如果 href 是 URL,则为目标框架/窗口。否则,不使用该参数。这的行为类似于普通链接。如果未给出该参数,则默认为: - 设置 externalLinkTarget 或_blank如果未设置,则适用于任何以http://或https://- 所有其他链接没有特定值 | |
| type | 如果 href 是 JavaScript,则按钮类型。否则,不使用该参数。如果未给出该参数,则默认为button | |
| <txt> | 按钮标题的任意文本。根据样式的不同,可能会有一个默认标题。任何给定值都将覆盖默认值。 - 对于严重性样式:严重性 - 对于所有其他样式的匹配标题:<空> 如果不希望严重性样式的标题,则必须将此参数设置为 " "(充满空格的非空字符串) |
案例
样式
严重性
{{% button href="https://gohugo.io/" style="info" %}}Get Hugo{{% /button %}}
{{% button href="https://gohugo.io/" style="note" %}}Get Hugo{{% /button %}}
{{% button href="https://gohugo.io/" style="tip" %}}Get Hugo{{% /button %}}
{{% button href="https://gohugo.io/" style="warning" %}}Get Hugo{{% /button %}}Get Hugo Get Hugo Get Hugo Get Hugo
印记颜色
{{% button href="https://gohugo.io/" style="primary" %}}Get Hugo{{% /button %}}
{{% button href="https://gohugo.io/" style="secondary" %}}Get Hugo{{% /button %}}
{{% button href="https://gohugo.io/" style="accent" %}}Get Hugo{{% /button %}}颜色
{{% button href="https://gohugo.io/" style="blue" %}}Get Hugo{{% /button %}}
{{% button href="https://gohugo.io/" style="green" %}}Get Hugo{{% /button %}}
{{% button href="https://gohugo.io/" style="grey" %}}Get Hugo{{% /button %}}
{{% button href="https://gohugo.io/" style="orange" %}}Get Hugo{{% /button %}}
{{% button href="https://gohugo.io/" style="red" %}}Get Hugo{{% /button %}}特殊颜色
{{% button href="https://gohugo.io/" style="default" %}}Get Hugo{{% /button %}}
{{% button href="https://gohugo.io/" style="transparent" %}}Get Hugo{{% /button %}}图标
无
{{% button href="https://gohugo.io/" icon=" " %}}{{% /button %}}有
{{% button href="https://gohugo.io/" icon="download" %}}{{% /button %}}左侧
{{% button href="https://gohugo.io/" icon="download" %}}Get Hugo{{% /button %}}右侧
{{% button href="https://gohugo.io/" icon="download" iconposition="right" %}}Get Hugo{{% /button %}}重载严重性样式
{{% button href="https://gohugo.io/" icon="dragon" style="warning" %}}Get Hugo{{% /button %}}目标
{{% button href="https://gohugo.io/" target="_self" %}}Get Hugo in same window{{% /button %}}
{{% button href="https://gohugo.io/" %}}Get Hugo in new Window/Frame (default){{% /button %}}其他
具有用户定义的颜色、字体、图标和 Markdown 标题
{{% button href="https://gohugo.io/" color="fuchsia" icon="fab fa-hackerrank" %}}Get **Hugo**{{% /button %}}具有所有默认值的严重性样式
{{% button href="https://gohugo.io/" style="tip" %}}{{% /button %}}按钮到内部页面
{{% button href="/index.html" %}}Home{{% /button %}}Button with JavaScript Action
如果您的 JavaScript 操作之后没有更改焦点,请确保调用this.blur() 最后取消选择按钮。
{{% button style="primary" icon="bullhorn" href="javascript:alert('你好,世界!');this.blur();" %}}你好,世界!{{% /button %}}form元素中的按钮
要在 Markdown 中使用原生 HTML 元素,请将其添加到 hugo.toml
[markup.goldmark.renderer]
unsafe = true<form action="../../search.html" method="get">
<input name="search-by-detail" class="search-by" type="search">
{{% button type="submit" style="secondary" icon="search" %}}搜索{{% /button %}}
</form>1.3 子页(children)
子页(children)简码列出了当前页面的子页面及其后代页面。
用法
{{% children sort="weight" %}}参数
| 名称 | 默认 | 描述 |
|---|---|---|
| containerstyle | ul | Choose the style used to group all children. It could be any HTML tag name. |
| style | li | Choose the style used to display each descendant. It could be any HTML tag name. |
| showhidden | false | When true, child pages hidden from the menu will be displayed as well. |
| description | false | When true shows a short text under each page in the list. When no description or summary exists for the page, the first 70 words of the content is taken - read more info about summaries on gohugo.io. |
| depth | 1 | The depth of descendants to display. For example, if the value is 2, the shortcode will display two levels of child pages. To get all descendants, set this value to a high number eg. 999. |
| sort | auto | The sort criteria of the displayed list. - auto defaults to ordersectionsby of the pages frontmatteror to ordersectionsby of the site configurationor to weight- weight- title- linktitle- modifieddate- expirydate- publishdate- date- length- default adhering to Hugo’s default sort criteria |
案例
默认
{{% children %}}带描述
{{% children description="true" %}}无限深度和隐藏页面
{{% children depth="999" showhidden="true" %}}容器和元素的标题样式
{{% children containerstyle="div" style="h2" depth="3" description="true" %}}Div: 组和元素样式
{{% children containerstyle="div" style="div" depth="3" %}}子页(children) 的子部分
3.1 子页 1
这是子页案例!
子页 1 的子部分
1.1 子页 1-1
这是子页案例!
3.2 子页 2
这是子页案例!
1.4 扩展(expand)
expand简码显示可展开/可折叠的文本部分
注释
这只能在现代浏览器中完美运行。虽然 Internet Explorer 11 在显示它时存在问题,但该功能仍然有效。
用法
{{% expand title="Expand me..." %}}Thank you!{{% /expand %}}{{% expand "Expand me..." %}}Thank you!{{% /expand %}}参数
| Name | Position | Default | Notes |
|---|---|---|---|
| title | 1 | "Expand me..." | Arbitrary text to appear next to the expand/collapse icon. |
| open | 2 | false | When true the content text will be initially shown as expanded. |
| <content> | <empty> | Arbitrary text to be displayed on expand. |
案例
默认
{{% expand %}}Yes, you did it!{{% /expand %}}最初扩展
{{% expand title="Expand me..." open="true" %}}No need to press you!{{% /expand %}}任意文本
{{% expand title="Show me almost **endless** possibilities" %}}
You can add standard markdown syntax:
- multiple paragraphs
- bullet point lists
- _emphasized_, **bold** and even **_bold emphasized_** text
- [links](https://example.com)
- etc.
```plaintext
...and even source code
```
> the possibilities are endless (almost - including other shortcodes may or may not work)
{{% /expand %}}1.5 高亮(highlight)
highlight 使用语法高亮显示来呈现您的代码。
1print("Hello World!")用法
这个简码与 Hugo 的 highlight 简码但提供了一些扩展。
它的调用方式与 Hugo 自己的短代码相同,提供位置参数或简单地使用 codefences。
您也可以自由地从自己的部分调用此短代码。在这种情况下,它类似于雨果的highlight功能语法,如果使用兼容性语法将此简码称为部分。
虽然示例使用带有命名参数的短代码,但建议改用 codefences。这是因为越来越多的其他软件支持共同防御(例如。GitHub),因此您的 Markdown 变得更加可移植。
```py { lineNos="true" wrap="true" title="python" }
print("Hello World!")
```{{< highlight lineNos="true" type="py" wrap="true" title="python" >}}
print("Hello World!")
{{< /highlight >}}{{< highlight py "lineNos=true,wrap=true,title=python" >}}
print("Hello World!")
{{< /highlight >}}参数
| 名称 | 位置 | 默认 | Note注释s |
|---|---|---|---|
| type | 1 | <空> | 要突出显示的代码语言。从支持的语言之一中进行选择。不区分大小写。 |
| title | <空> | 扩展。 代码的任意标题。如果出现以下情况,则会像单个选项卡一样显示代码hl_inline=false(这是 Hugos 的默认设置)。 | |
| wrap | 扩展。 当内容可以换行时,否则它将是可滚动的。 默认值true,可以在 hugo.toml并通过 frontmatter 覆盖。见下文。 | ||
| options | 2 | <空> | 此表中零个或多个 Hugo 支持的选项 以及扩展参数的可选逗号分隔列表。 |
| <option> | <空> | Hugo 支持的任何选项. | |
| <content> | <空> | 需要语法高亮的代码. |
配置
Hugo 支持选项 的默认值可以通过 goldmark 设置hugo.toml
扩展选项的默认值可以通过hugo.toml或被每个单独页面的 frontmatter 覆盖。
全局配置文件
您可以在颜色变体样式表文件中配置用于代码块的颜色样式。
推荐设置
[markup]
[markup.highlight]
lineNumbersInTable = false
noClasses = false可选设置
[params]
highlightWrap = true页面 Frontmatter
highlightWrap = true案例
带起始偏移量的行号
如上所述,如果代码换行,布局中的行号将发生变化,因此最好使用table inline.为了让您更轻松,请将lineNumbersInTable = false在你的hugo.toml并添加lineNos = true调用简码而不是特定值时,或者table inline.
{{< highlight lineNos="true" lineNoStart="666" type="py" >}}
# the hardest part is to start writing code; here's a kickstart; just copy and paste this; it's free; the next lines will cost you serious credits
print("Hello")
print(" ")
print("World")
print("!")
{{< /highlight >}}666# the hardest part is to start writing code; here's a kickstart; just copy and paste this; it's free; the next lines will cost you serious credits
667print("Hello")
668print(" ")
669print("World")
670print("!")有标题的Codefence
```py { title="python" }
# a bit shorter
print("Hello World!")
```
# a bit shorter
print("Hello World!")带装饰
{{< highlight type="py" wrap="true" hl_lines="2" >}}
# Quicksort Python One-liner
lambda L: [] if L==[] else qsort([x for x in L[1:] if x< L[0]]) + L[0:1] + qsort([x for x in L[1:] if x>=L[0]])
# Some more stuff
{{< /highlight >}}# Quicksort Python One-liner
lambda L: [] if L==[] else qsort([x for x in L[1:] if x< L[0]]) + L[0:1] + qsort([x for x in L[1:] if x>=L[0]])
# Some more stuff无装饰
{{< highlight type="py" wrap="false" hl_lines="2" >}}
# Quicksort Python One-liner
lambda L: [] if L==[] else qsort([x for x in L[1:] if x< L[0]]) + L[0:1] + qsort([x for x in L[1:] if x>=L[0]])
# Some more stuff
{{< /highlight >}}# Quicksort Python One-liner
lambda L: [] if L==[] else qsort([x for x in L[1:] if x< L[0]]) + L[0:1] + qsort([x for x in L[1:] if x>=L[0]])
# Some more stuff1.6 图标(icon)
icon简码使用 Font Awesome 库显示图标。
Usage
{{% icon icon="exclamation-triangle" %}}
{{% icon icon="angle-double-up" %}}
{{% icon icon="skull-crossbones" %}}{{% icon exclamation-triangle %}}
{{% icon angle-double-up %}}
{{% icon skull-crossbones %}}参数
| 名称 | 位置 | 默认 | 注释 |
|---|---|---|---|
| icon | 1 | 要显示的Font Awesome icon name 。它将以其相应上下文的文本颜色显示。 |
查找图标
浏览 Font Awesome Gallery 中的可用图标。请注意,免费过滤器已启用,因为默认情况下只有免费图标可用。
进入特定图标的 Font Awesome 页面(例如心形heart页面)后,复制图标名称并粘贴到 Markdown 内容中。
自定义图标
Font Awesome提供了许多修改图标的方法
- 更改颜色(默认情况下,图标将继承父颜色)
- 增大或减小尺寸
- 旋转
- 与其他图标结合使用
查看有关使用 CSS 的 Web 字体 的完整文档,了解更多信息。
案例
标准用法
Built with {{% icon heart %}} by Relearn and HugoBuilt with by Relearn and Hugo
高级 HTML 用法
虽然简码简化了标准图标的使用,但 Font Awesome 库的图标自定义和其他高级功能要求您直接使用 HTML。将 <i> HTML 粘贴到标记中,Font Awesome 将加载相关图标。
Built with <i class="fas fa-heart"></i> by Relearn and Hugo由 Relearn 和 Hugo 构建。
要在 Markdown 中使用这些原生 HTML 元素,请将其添加到hugo.toml:
[markup.goldmark.renderer]
unsafe = true1.7 包含文件(include)
include简码在当前页面中包含项目中的其他文件。
用法
{{% include file="include_me.md" %}}{{% include "include_me.md" %}}包含的文件甚至可以包含 Markdown,并且在生成目录时会被考虑在内。
参数
| 名称 | 位置 | 默认 | 注释 |
|---|---|---|---|
| file | 1 | <empty> | 要包含的文件的路径。路径分辨率遵循Hugo的内置readFile功能 |
| hidefirstheading | 2 | false | true:当包含的文件包含标题时,第一个标题将被隐藏。例如,这派上用场。如果包含其他独立的 Markdown 文件。 |
案例
任意内容
{{% include "4_tools/1_theme/include_me.md" %}}文件包含案例
1.8 数学公式(math)
math简码使用 MathJax 库生成漂亮的格式化数学和化学公式。
注释
这仅适用于现代浏览器。
用法
虽然示例使用带有命名参数的短代码,但建议改用 codefences。这是因为越来越多的其他软件支持数学协同防御(例如。GitHub),因此您的 Markdown 变得更加可移植。
```math { align="center" }
$$\left( \sum_{k=1}^n a_k b_k \right)^2 \leq \left( \sum_{k=1}^n a_k^2 \right) \left( \sum_{k=1}^n b_k^2 \right)$$
```{{< math align="center" >}}
$$\left( \sum_{k=1}^n a_k b_k \right)^2 \leq \left( \sum_{k=1}^n a_k^2 \right) \left( \sum_{k=1}^n b_k^2 \right)$$
{{< /math >}}参数
| 名称 | 默认 | 注释 |
|---|---|---|
| align | center | 允许值 left, center or right. |
| <content> | <empty> | 公式内容. |
配置
MathJax 配置了默认设置。您可以通过 JSON 对象自定义 MathJax 对所有文件的默认设置hugo.toml或通过您的页面 frontmatter 覆盖每个页面的这些设置。
你的 JSON 对象hugo.toml/ frontmatter 被转发到 MathJax 的配置对象中。
有关所有允许的设置,请参阅 MathJax 文档。
全局配置文件
[params]
mathJaxInitialize = "{ \"chtml\": { \"displayAlign\": \"left\" } }"页面 Frontmatter
mathJaxInitialize = "{ \"chtml\": { \"displayAlign\": \"left\" } }"案例
内联数学公式
如果果使用单个`$`作为公式周围的分隔符,则会生成内联数学: {{< math >}}$\sqrt{3}${{< /math >}}如果果使用单个$作为公式周围的分隔符,则会生成内联数学:
$\sqrt{3}$
右对齐的块级数学
如果将公式分隔为两个连续的`$$`公式,则会生成一个新块。
{{< math align="right" >}}
$$\left( \sum_{k=1}^n a_k b_k \right)^2 \leq \left( \sum_{k=1}^n a_k^2 \right) \left( \sum_{k=1}^n b_k^2 \right)$$
{{< /math >}}如果将公式分隔为两个连续的$$公式,则会生成一个新块。
Codefence
```math
$$\left( \sum_{k=1}^n a_k b_k \right)^2 \leq \left( \sum_{k=1}^n a_k^2 \right) \left( \sum_{k=1}^n b_k^2 \right)$$
```化学式
{{< math >}}
$$\ce{Hg^2+ ->[I-] HgI2 ->[I-] [Hg^{II}I4]^2-}$$
{{< /math >}}1.9 流图(mermaid)
The mermaid shortcode generates diagrams and flowcharts from text, in a similar manner as Markdown using the Mermaid library.
graph LR;
If --> Then
Then --> Else
注释
这仅适用于现代浏览器。
用法
While the examples are using shortcodes with named parameter it is recommended to use codefences instead. This is because more and more other software supports Mermaid codefences (eg. GitHub) and so your markdown becomes more portable.
You are free to also call this shortcode from your own partials.
```mermaid { align="center" zoom="true" }
graph LR;
If --> Then
Then --> Else
```{{< mermaid align="center" zoom="true" >}}
graph LR;
If --> Then
Then --> Else
{{< /mermaid >}}The generated graphs can be be panned by dragging them and zoomed by using the mousewheel. On mobile devices you can use finger gestures.
参数
| 名称 | 默认 | 注释 |
|---|---|---|
| align | center | Allowed values are left, center or right. |
| zoom | see notes | Whether the graph is pan- and zoomable. If not set the value is determined by the mermaidZoom setting of the site or the pages frontmatter or false if not set at all.- false: no pan or zoom- true: pan and zoom active |
| <content> | <empty> | Your Mermaid graph. |
配置
Mermaid is configured with default settings. You can customize Mermaid’s default settings for all of your files thru a JSON object in your hugo.toml, override these settings per page thru your pages frontmatter or override these setting per diagramm thru diagram directives.
The JSON object of your hugo.toml / frontmatter is forwarded into Mermaid’s mermaid.initialize() function.
See Mermaid documentation for all allowed settings.
The theme setting can also be set by your used color variant. This will be the sitewide default and can - again - be overridden by your settings in hugo.toml, frontmatter or diagram directives.
全局配置文件
[params]
mermaidInitialize = "{ \"theme\": \"dark\" }"
mermaidZoom = true页面 Frontmatter
mermaidInitialize = "{ \"theme\": \"dark\" }"
mermaidZoom = true案例
带 YAML 样式标题的 流程图
{{< mermaid >}}
---
title: Example Diagram
---
graph LR;
A[Hard edge] -->|Link text| B(Round edge)
B --> C{<strong>Decision</strong>}
C -->|One| D[Result one]
C -->|Two| E[Result two]
{{< /mermaid >}}
---
title: Example Diagram
---
graph LR;
A[Hard edge] -->|Link text| B(Round edge)
B --> C{<strong>Decision</strong>}
C -->|One| D[Result one]
C -->|Two| E[Result two]
带配置指令的序列图
{{< mermaid >}}
%%{init:{"fontFamily":"monospace", "sequence":{"showSequenceNumbers":true}}}%%
sequenceDiagram
Alice->>John: Hello John, how are you?
loop Healthcheck
John->>John: Fight against hypochondria
end
Note right of John: Rational thoughts!
John-->>Alice: Great!
John->>Bob: How about you?
Bob-->>John: Jolly good!
{{< /mermaid >}}
%%{init:{"fontFamily":"monospace", "sequence":{"showSequenceNumbers":true}}}%%
sequenceDiagram
Alice->>John: Hello John, how are you?
loop Healthcheck
John->>John: Fight against hypochondria
end
Note right of John: Rational thoughts!
John-->>Alice: Great!
John->>Bob: How about you?
Bob-->>John: Jolly good!
具有Codefence语法的类图
```mermaid
classDiagram
Animal <|-- Duck
Animal <|-- Fish
Animal <|-- Zebra
Animal : +int age
Animal : +String gender
Animal: +isMammal()
Animal: +mate()
class Duck{
+String beakColor
+swim()
+quack()
}
class Fish{
-int sizeInFeet
-canEat()
}
class Zebra{
+bool is_wild
+run()
}
```classDiagram
Animal <|-- Duck
Animal <|-- Fish
Animal <|-- Zebra
Animal : +int age
Animal : +String gender
Animal: +isMammal()
Animal: +mate()
class Duck{
+String beakColor
+swim()
+quack()
}
class Fish{
-int sizeInFeet
-canEat()
}
class Zebra{
+bool is_wild
+run()
}向右对齐的状态图
{{< mermaid align="right" >}}
stateDiagram-v2
open: Open Door
closed: Closed Door
locked: Locked Door
open --> closed: Close
closed --> locked: Lock
locked --> closed: Unlock
closed --> open: Open
{{< /mermaid >}}stateDiagram-v2 open: Open Door closed: Closed Door locked: Locked Door open --> closed: Close closed --> locked: Lock locked --> closed: Unlock closed --> open: Open
非默认主题的实体关系模型
{{< mermaid >}}
%%{init:{"theme":"forest"}}%%
erDiagram
CUSTOMER }|..|{ DELIVERY-ADDRESS : has
CUSTOMER ||--o{ ORDER : places
CUSTOMER ||--o{ INVOICE : "liable for"
DELIVERY-ADDRESS ||--o{ ORDER : receives
INVOICE ||--|{ ORDER : covers
ORDER ||--|{ ORDER-ITEM : includes
PRODUCT-CATEGORY ||--|{ PRODUCT : contains
PRODUCT ||--o{ ORDER-ITEM : "ordered in"
{{< /mermaid >}}
%%{init:{"theme":"forest"}}%%
erDiagram
CUSTOMER }|..|{ DELIVERY-ADDRESS : has
CUSTOMER ||--o{ ORDER : places
CUSTOMER ||--o{ INVOICE : "liable for"
DELIVERY-ADDRESS ||--o{ ORDER : receives
INVOICE ||--|{ ORDER : covers
ORDER ||--|{ ORDER-ITEM : includes
PRODUCT-CATEGORY ||--|{ PRODUCT : contains
PRODUCT ||--o{ ORDER-ITEM : "ordered in"
用户旅程
{{< mermaid >}}
journey
title My working day
section Go to work
Make tea: 5: Me
Go upstairs: 3: Me
Do work: 1: Me, Cat
section Go home
Go downstairs: 5: Me
Sit down: 3: Me
{{< /mermaid >}}
journey
title My working day
section Go to work
Make tea: 5: Me
Go upstairs: 3: Me
Do work: 1: Me, Cat
section Go home
Go downstairs: 5: Me
Sit down: 3: Me
甘特图
{{< mermaid >}}
gantt
dateFormat YYYY-MM-DD
title Adding GANTT diagram functionality to Mermaid
section A section
Completed task :done, des1, 2014-01-06,2014-01-08
Active task :active, des2, 2014-01-09, 3d
Future task : des3, after des2, 5d
Future task2 : des4, after des3, 5d
section Critical tasks
Completed task in the critical line :crit, done, 2014-01-06,24h
Implement parser and jison :crit, done, after des1, 2d
Create tests for parser :crit, active, 3d
Future task in critical line :crit, 5d
Create tests for renderer :2d
Add to Mermaid :1d
{{< /mermaid >}}
gantt
dateFormat YYYY-MM-DD
title Adding GANTT diagram functionality to Mermaid
section A section
Completed task :done, des1, 2014-01-06,2014-01-08
Active task :active, des2, 2014-01-09, 3d
Future task : des3, after des2, 5d
Future task2 : des4, after des3, 5d
section Critical tasks
Completed task in the critical line :crit, done, 2014-01-06,24h
Implement parser and jison :crit, done, after des1, 2d
Create tests for parser :crit, active, 3d
Future task in critical line :crit, 5d
Create tests for renderer :2d
Add to Mermaid :1d
不带缩放的饼图
{{< mermaid zoom="false" >}}
pie title Pets adopted by volunteers
"Dogs" : 386
"Cats" : 85
"Rats" : 15
{{< /mermaid >}}
pie title Pets adopted by volunteers
"Dogs" : 386
"Cats" : 85
"Rats" : 15
象限图
{{< mermaid >}}
pie title Pets adopted by volunteers
title Reach and engagement of campaigns
x-axis Low Reach --> High Reach
y-axis Low Engagement --> High Engagement
quadrant-1 We should expand
quadrant-2 Need to promote
quadrant-3 Re-evaluate
quadrant-4 May be improved
Campaign A: [0.3, 0.6]
Campaign B: [0.45, 0.23]
Campaign C: [0.57, 0.69]
Campaign D: [0.78, 0.34]
Campaign E: [0.40, 0.34]
Campaign F: [0.35, 0.78]
{{< /mermaid >}}
quadrantChart
title Reach and engagement of campaigns
x-axis Low Reach --> High Reach
y-axis Low Engagement --> High Engagement
quadrant-1 We should expand
quadrant-2 Need to promote
quadrant-3 Re-evaluate
quadrant-4 May be improved
Campaign A: [0.3, 0.6]
Campaign B: [0.45, 0.23]
Campaign C: [0.57, 0.69]
Campaign D: [0.78, 0.34]
Campaign E: [0.40, 0.34]
Campaign F: [0.35, 0.78]
需求图
{{< mermaid >}}
requirementDiagram
requirement test_req {
id: 1
text: the test text.
risk: high
verifymethod: test
}
element test_entity {
type: simulation
}
test_entity - satisfies -> test_req
{{< /mermaid >}}
requirementDiagram
requirement test_req {
id: 1
text: the test text.
risk: high
verifymethod: test
}
element test_entity {
type: simulation
}
test_entity - satisfies -> test_req
Git 图
{{< mermaid >}}
gitGraph
commit
commit
branch develop
checkout develop
commit
commit
checkout main
merge develop
commit
commit
{{< /mermaid >}}
gitGraph
commit
commit
branch develop
checkout develop
commit
commit
checkout main
merge develop
commit
commit
C4 图
{{< mermaid >}}
C4Context
title System Context diagram for Internet Banking System
Enterprise_Boundary(b0, "BankBoundary0") {
Person(customerA, "Banking Customer A", "A customer of the bank, with personal bank accounts.")
Person(customerB, "Banking Customer B")
Person_Ext(customerC, "Banking Customer C", "desc")
Person(customerD, "Banking Customer D", "A customer of the bank, <br/> with personal bank accounts.")
System(SystemAA, "Internet Banking System", "Allows customers to view information about their bank accounts, and make payments.")
Enterprise_Boundary(b1, "BankBoundary") {
SystemDb_Ext(SystemE, "Mainframe Banking System", "Stores all of the core banking information about customers, accounts, transactions, etc.")
System_Boundary(b2, "BankBoundary2") {
System(SystemA, "Banking System A")
System(SystemB, "Banking System B", "A system of the bank, with personal bank accounts. next line.")
}
System_Ext(SystemC, "E-mail system", "The internal Microsoft Exchange e-mail system.")
SystemDb(SystemD, "Banking System D Database", "A system of the bank, with personal bank accounts.")
Boundary(b3, "BankBoundary3", "boundary") {
SystemQueue(SystemF, "Banking System F Queue", "A system of the bank.")
SystemQueue_Ext(SystemG, "Banking System G Queue", "A system of the bank, with personal bank accounts.")
}
}
}
BiRel(customerA, SystemAA, "Uses")
BiRel(SystemAA, SystemE, "Uses")
Rel(SystemAA, SystemC, "Sends e-mails", "SMTP")
Rel(SystemC, customerA, "Sends e-mails to")
UpdateElementStyle(customerA, $fontColor="red", $bgColor="grey", $borderColor="red")
UpdateRelStyle(customerA, SystemAA, $textColor="blue", $lineColor="blue", $offsetX="5")
UpdateRelStyle(SystemAA, SystemE, $textColor="blue", $lineColor="blue", $offsetY="-10")
UpdateRelStyle(SystemAA, SystemC, $textColor="blue", $lineColor="blue", $offsetY="-40", $offsetX="-50")
UpdateRelStyle(SystemC, customerA, $textColor="red", $lineColor="red", $offsetX="-50", $offsetY="20")
UpdateLayoutConfig($c4ShapeInRow="3", $c4BoundaryInRow="1")
{{< /mermaid >}}
C4Context
title System Context diagram for Internet Banking System
Enterprise_Boundary(b0, "BankBoundary0") {
Person(customerA, "Banking Customer A", "A customer of the bank, with personal bank accounts.")
Person(customerB, "Banking Customer B")
Person_Ext(customerC, "Banking Customer C", "desc")
Person(customerD, "Banking Customer D", "A customer of the bank, <br/> with personal bank accounts.")
System(SystemAA, "Internet Banking System", "Allows customers to view information about their bank accounts, and make payments.")
Enterprise_Boundary(b1, "BankBoundary") {
SystemDb_Ext(SystemE, "Mainframe Banking System", "Stores all of the core banking information about customers, accounts, transactions, etc.")
System_Boundary(b2, "BankBoundary2") {
System(SystemA, "Banking System A")
System(SystemB, "Banking System B", "A system of the bank, with personal bank accounts. next line.")
}
System_Ext(SystemC, "E-mail system", "The internal Microsoft Exchange e-mail system.")
SystemDb(SystemD, "Banking System D Database", "A system of the bank, with personal bank accounts.")
Boundary(b3, "BankBoundary3", "boundary") {
SystemQueue(SystemF, "Banking System F Queue", "A system of the bank.")
SystemQueue_Ext(SystemG, "Banking System G Queue", "A system of the bank, with personal bank accounts.")
}
}
}
BiRel(customerA, SystemAA, "Uses")
BiRel(SystemAA, SystemE, "Uses")
Rel(SystemAA, SystemC, "Sends e-mails", "SMTP")
Rel(SystemC, customerA, "Sends e-mails to")
UpdateElementStyle(customerA, $fontColor="red", $bgColor="grey", $borderColor="red")
UpdateRelStyle(customerA, SystemAA, $textColor="blue", $lineColor="blue", $offsetX="5")
UpdateRelStyle(SystemAA, SystemE, $textColor="blue", $lineColor="blue", $offsetY="-10")
UpdateRelStyle(SystemAA, SystemC, $textColor="blue", $lineColor="blue", $offsetY="-40", $offsetX="-50")
UpdateRelStyle(SystemC, customerA, $textColor="red", $lineColor="red", $offsetX="-50", $offsetY="20")
UpdateLayoutConfig($c4ShapeInRow="3", $c4BoundaryInRow="1")
思维导图
{{< mermaid >}}
mindmap
root((mindmap))
Origins
Long history
::icon(fa fa-book)
Popularisation
British popular psychology author Tony Buzan
Research
On effectiveness<br/>and features
On Automatic creation
Uses
Creative techniques
Strategic planning
Argument mapping
Tools
Pen and paper
Mermaid
{{< /mermaid >}}
mindmap
root((mindmap))
Origins
Long history
::icon(fa fa-book)
Popularisation
British popular psychology author Tony Buzan
Research
On effectiveness<br/>and features
On Automatic creation
Uses
Creative techniques
Strategic planning
Argument mapping
Tools
Pen and paper
Mermaid
时间线
{{< mermaid >}}
timeline
title History of Social Media Platform
2002 : LinkedIn
2004 : Facebook
: Google
2005 : Youtube
2006 : Twitter
{{< /mermaid >}}
timeline
title History of Social Media Platform
2002 : LinkedIn
2004 : Facebook
: Google
2005 : Youtube
2006 : Twitter
桑基
{{< mermaid >}}
sankey-beta
%% source,target,value
Electricity grid,Over generation / exports,104.453
Electricity grid,Heating and cooling - homes,113.726
Electricity grid,H2 conversion,27.14
{{< /mermaid >}}sankey-beta %% source,target,value Electricity grid,Over generation / exports,104.453 Electricity grid,Heating and cooling - homes,113.726 Electricity grid,H2 conversion,27.14
XYChart
{{< mermaid >}}
xychart-beta
title "Sales Revenue"
x-axis [jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec]
y-axis "Revenue (in $)" 4000 --> 11000
bar [5000, 6000, 7500, 8200, 9500, 10500, 11000, 10200, 9200, 8500, 7000, 6000]
line [5000, 6000, 7500, 8200, 9500, 10500, 11000, 10200, 9200, 8500, 7000, 6000]
{{< /mermaid >}}
xychart-beta
title "Sales Revenue"
x-axis [jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec]
y-axis "Revenue (in $)" 4000 --> 11000
bar [5000, 6000, 7500, 8200, 9500, 10500, 11000, 10200, 9200, 8500, 7000, 6000]
line [5000, 6000, 7500, 8200, 9500, 10500, 11000, 10200, 9200, 8500, 7000, 6000]
块图
{{< mermaid >}}
block-beta
columns 1
db(("DB"))
blockArrowId6<[" "]>(down)
block:ID
A
B["A wide one in the middle"]
C
end
space
D
ID --> D
C --> D
style B fill:#969,stroke:#333,stroke-width:4px
{{< /mermaid >}}
block-beta
columns 1
db(("DB"))
blockArrowId6<[" "]>(down)
block:ID
A
B["A wide one in the middle"]
C
end
space
D
ID --> D
C --> D
style B fill:#969,stroke:#333,stroke-width:4px
1.10 注解(Notice)
notice 简码显示各种类型的免责声明,并带有可调节的颜色、标题和图标,以帮助您构建页面。
There may be pirates
这一切都与盒子有关。
用法
{{% notice style="primary" title="There may be pirates" icon="skull-crossbones" %}}
It is all about the boxes.
{{% /notice %}}{{% notice primary "There may be pirates" "skull-crossbones" %}}
It is all about the boxes.
{{% /notice %}}参数
| 名称 | 位置 | 默认 | 注释 |
|---|---|---|---|
| style | 1 | default | 框使用的样式方案。 - 严重程度: info, note, tip, warning- 印记颜色: primary, secondary, accent- 颜色: blue, green, grey, orange, red- 特殊颜色: default, transparent, code |
| color | see notes | 要使用的 CSS 颜色值。如果未设置,则选择的颜色取决于样式。任何给定的值都将覆盖默认值。 - 对于严重性样式:严重性匹配的漂亮颜色 - 对于所有其他样式:相应的颜色 | |
| title | 2 | see notes | 框的标题的任意文本。根据样式的不同,可能会有一个默认标题。任何给定的值都将覆盖默认值。 - 对于严重性样式:严重性匹配的标题 - 对于所有其他样式:<空> 如果您不希望严重性样式的标题,则必须将此参数设置为 " "(一个充满空格的非空字符串)。 |
| icon | 3 | see notes | Font Awesome icon name 设置在标题的左侧。根据样式的不同,可能会有一个默认图标。任何给定的值都将覆盖默认值。 - 对于严重性样式:严重性匹配的漂亮图标 - 对于所有其他样式:<空> 如果您不想为严重性样式使用图标,则必须将此参数设置为 " "(填充空格的非空字符串) |
| <content> | <empty> | 要在框中显示的任意文本。 |
案例
按严重性
带有标记的信息
{{% notice style="info" %}}
An **information** disclaimer
You can add standard markdown syntax:
- multiple paragraphs
- bullet point lists
- _emphasized_, **bold** and even ***bold emphasized*** text
- [links](https://example.com)
- etc.
```plaintext
...and even source code
```
> the possibilities are endless (almost - including other shortcodes may or may not work)
{{% /notice %}} 信息
An information disclaimer
You can add standard markdown syntax:
- multiple paragraphs
- bullet point lists
- emphasized, bold and even bold emphasized text
- links
- etc.
...and even source codethe possibilities are endless (almost - including other shortcodes may or may not work)
Note
{{% notice style="note" %}}
A **notice** disclaimer
{{% /notice %}} 注释
A notice disclaimer
Tip
{{% notice style="tip" %}}
A **tip** disclaimer
{{% /notice %}} 提示
A tip disclaimer
Warning
{{% notice style="warning" %}}
A **warning** disclaimer
{{% /notice %}} 警告
A warning disclaimer
带有非默认标题和图标的 Warning
{{% notice style="warning" title="Here are dragons" icon="dragon" %}}
A **warning** disclaimer
{{% /notice %}} Here are dragons
A warning disclaimer
没有标题和图标的 Warning
{{% notice style="warning" title=" " icon=" " %}}
A **warning** disclaimer
{{% /notice %}}A warning disclaimer
按品牌颜色
仅具有标题 Primary
{{% notice style="primary" title="Primary" %}}
A **primary** disclaimer
{{% /notice %}}Primary
A primary disclaimer
仅具有图标的 Secondary
{{% notice style="secondary" icon="stopwatch" %}}
A **secondary** disclaimer
{{% /notice %}}A secondary disclaimer
Accent
{{% notice style="accent" %}}
An **accent** disclaimer
{{% /notice %}}An accent disclaimer
按颜色
没有标题和图标的 Blue
{{% notice style="blue" %}}
A **blue** disclaimer
{{% /notice %}}A blue disclaimer
仅带标题的 Green
{{% notice style="green" title="Green" %}}
A **green** disclaimer
{{% /notice %}}Green
A green disclaimer
仅带图标的 Grey
{{% notice style="grey" icon="bug" %}}
A **grey** disclaimer
{{% /notice %}}A grey disclaimer
带有标题和图标的 Orange
{{% notice style="orange" title="Orange" icon="bug" %}}
A **orange** disclaimer
{{% /notice %}} Orange
A orange disclaimer
没有标题和图标的 Red
{{% notice style="red" %}}
A **red** disclaimer
{{% /notice %}}A red disclaimer
按特殊颜色
使用位置参数的默认值
{{% notice default "Pay Attention to this Note!" "skull-crossbones" %}}
Some serious information.
{{% /notice %}} Pay Attention to this Note!
Some serious information.
透明的标题和图标
{{% notice style="transparent" title="Pay Attention to this Note!" icon="skull-crossbones" %}}
Some serious information.
{{% /notice %}} Pay Attention to this Note!
Some serious information.
具有用户定义的颜色、Font Awesome 字体的品牌图标和 Markdown 标题
{{% notice color="fuchsia" title="**Hugo**" icon="fab fa-hackerrank" %}}
Victor? Is it you?
{{% /notice %}} Hugo
Victor? Is it you?
1.11 站点参数
siteparam 简码打印站点参数的值。
用法
{{% siteparam name="editURL" %}}{{% siteparam "editURL" %}}参数
| Name | Position | Default | Notes |
|---|---|---|---|
| name | 1 | <empty> | 要显示的站点参数的名称。 |
案例
editURL from hugo.toml
`editURL` value: {{% siteparam name="editURL" %}}editURL value: https://github.com/irscript/irscript.github.io/blob/main/content/${FilePath}
具有 Markdown 和 HTML 格式的嵌套参数
要使用 formatted 参数,请将其添加到 hugo.toml:
[markup.goldmark.renderer]
unsafe = true现在,包含 Markdown 的值将正确设置格式。
[params]
[params.siteparam.test]
text = "A **nested** parameter <b>with</b> formatting"Formatted parameter: {{% siteparam name="siteparam.test.text" %}}Formatted parameter:
1.12 标签页
tab简码来显示单个选项卡。
如果要使用显式语言标记代码示例,这将特别有用。
如果要将多个选项卡组合在一起,可以将选项卡包装到选项卡简码中。
printf("Hello World!");用户
{{% tab title="c" %}}
```c
printf("Hello World!");
```
{{% /tab %}}参数
| 名称 | 默认 | 注释 |
|---|---|---|
| style | see notes | 用于选项卡的样式方案。如果未设置样式,而是在选项卡内显示单个代码块,则其默认样式将适应块的样式。否则codedefault被使用。 - 按严重性: info,note,tip,warning- 按品牌颜色: primary,secondary,accent- 按颜色: blue,green,grey,orange,- 按特殊颜色: red,default,transparent,code |
| color | see notes | 要使用的 CSS 颜色值。如果未设置,则选择的颜色取决于样式。任何给定的值都将覆盖默认值。 - 对于严重性样式:严重性匹配的漂亮颜色 - 对于所有其他样式:相应的颜色 |
| title | see notes | 标题的任意文本。根据样式的不同,可能会有一个默认标题。任何给定的值都将覆盖默认值。 - 对于严重性样式:严重性匹配的标题 - 对于所有其他样式:<空> 如果您不希望严重性样式的标题,则必须将此参数设置为 " "(一个充满空格的非空字符串)。 |
| icon | see notes | Font Awesome icon name 设置在标题的左侧。根据样式的不同,可能会有一个默认图标。任何给定的值都将覆盖默认值。 - 对于严重性样式:严重性匹配的漂亮图标 - 对于所有其他样式:<空> 如果您不想为严重性样式使用图标,则必须将此参数设置为 " "(填充空格的非空字符串) |
| <content> | <empty> | 任意文本,可以为 <空> |
案例
具有折叠边距的单个代码块
{{% tab title="Code" %}}
```python
printf("Hello World!");
```
{{% /tab %}}
printf("Hello World!");混合 Markdown 内容
{{% tab title="_**Mixed**_" %}}
选项卡不仅可以包含代码,还可以包含任意文本。在这种情况下,文本和代码将获得边距。
```python
printf("Hello World!");
```
{{% /tab %}}
选项卡不仅可以包含代码,还可以包含任意文本。在这种情况下,文本和代码将获得边距。
printf("Hello World!");理解style 和 color 行为
该style参数会影响参数color的应用方式
{{< tabs >}}
{{% tab title="just colored style" style="blue" %}}
The `style` parameter is set to a color style.
This will set the background to a lighter version of the chosen style color as configured in your theme variant.
{{% /tab %}}
{{% tab title="just color" color="blue" %}}
Only the `color` parameter is set.
This will set the background to a lighter version of the chosen CSS color value.
{{% /tab %}}
{{% tab title="default style and color" style="default" color="blue" %}}
The `style` parameter affects how the `color` parameter is applied.
The `default` style will set the background to your `--MAIN-BG-color` as configured for your theme variant resembling the default style but with different color.
{{% /tab %}}
{{% tab title="just severity style" style="info" %}}
The `style` parameter is set to a severity style.
This will set the background to a lighter version of the chosen style color as configured in your theme variant and also affects the chosen icon.
{{% /tab %}}
{{% tab title="severity style and color" style="info" color="blue" %}}
The `style` parameter affects how the `color` parameter is applied.
This will set the background to a lighter version of the chosen CSS color value and also affects the chosen icon.
{{% /tab %}}
{{< /tabs >}}
The style parameter is set to a color style.
This will set the background to a lighter version of the chosen style color as configured in your theme variant.
Only the color parameter is set.
This will set the background to a lighter version of the chosen CSS color value.
The style parameter affects how the color parameter is applied.
The default style will set the background to your --MAIN-BG-color as configured for your theme variant resembling the default style but with different color.
The style parameter is set to a severity style.
This will set the background to a lighter version of the chosen style color as configured in your theme variant and also affects the chosen icon.
The style parameter affects how the color parameter is applied.
This will set the background to a lighter version of the chosen CSS color value and also affects the chosen icon.
1.13 多标签页
tabs 简码在无限数量的选项卡中显示任意内容。
例如,这派上用场。用于提供多种语言的代码片段。
如果您只想要一个选项卡,则可以改为将选项卡称为独立选项卡简码。
hello.
print("Hello World!")echo "Hello World!"printf("Hello World!");用法
有关嵌套选项卡参数的说明,请参阅tab选项卡简码。
{{< tabs title="hello." >}}
{{% tab title="py" %}}
```python
print("Hello World!")
```
{{% /tab %}}
{{% tab title="sh" %}}
```bash
echo "Hello World!"
```
{{% /tab %}}
{{% tab title="c" %}}
```c
printf"Hello World!");
```
{{% /tab %}}
{{< /tabs >}}{{ partial "shortcodes/tabs.html" (dict
"page" .
"title" "hello."
"content" (slice
(dict
"title" "py"
"content" ("```python\nprint(\"Hello World!\")\n```" | .RenderString)
)
(dict
"title" "sh"
"content" ("```bash\necho \"Hello World!\"\n```" | .RenderString)
)
(dict
"title" "c"
"content" ("```c\nprintf(\"Hello World!\");\n```" | .RenderString)
)
)
)}}参数
| 名称 | 默认 | 注释 |
|---|---|---|
| groupid | <random> | 选项卡视图所属的组的任意名称。 具有相同 groupid 的选项卡视图会同步其所选选项卡。选项卡选择会根据groupid用于选项卡视图。如果在选项卡组中找不到所选选项卡,则改为选择第一个选项卡。 这种同步适用于整个网站! |
| style | <empty> | 为每个包含的选项卡设置默认值。可以被每个选项卡覆盖。有关可能的值,请参阅选项卡简码。 |
| color | <empty> | 为每个包含的选项卡设置默认值。可以被每个选项卡覆盖。有关可能的值,请参阅选项卡简码。 |
| title | <empty> | 写在选项卡视图前面的任意标题。 |
| icon | <empty> | Font Awesome icon name设置在标题的左侧 |
| <content> | <empty> | 使用子简码定义的任意数量的tab选项卡 |
案例
groupid 的行为
查看在选择不同选项卡时选项卡视图会发生什么情况。
按下 A 组的选项卡可同步切换 A 组的所有选项卡视图(如果选项卡可用),则 B 组的选项卡保持不变。
{{< tabs groupid="a" >}}
{{% tab title="json" %}}
{{< highlight json "linenos=true" >}}
{ "Hello": "World" }
{{< /highlight >}}
{{% /tab %}}
{{% tab title="_**XML**_ stuff" %}}
```xml
<Hello>World</Hello>
```
{{% /tab %}}
{{% tab title="text" %}}
Hello World
{{% /tab %}}
{{< /tabs >}}{{< tabs groupid="a" >}}
{{% tab title="json" %}}
{{< highlight json "linenos=true" >}}
{ "Hello": "World" }
{{< /highlight >}}
{{% /tab %}}
{{% tab title="XML stuff" %}}
```xml
<Hello>World</Hello>
```
{{% /tab %}}
{{< /tabs >}}{{< tabs groupid="b" >}}
{{% tab title="json" %}}
{{< highlight json "linenos=true" >}}
{ "Hello": "World" }
{{< /highlight >}}
{{% /tab %}}
{{% tab title="XML stuff" %}}
```xml
<Hello>World</Hello>
```
{{% /tab %}}
{{< /tabs >}}A 组,选项卡视图 1
1{ "Hello": "World" }<Hello>World</Hello>Hello World
A 组,选项卡视图 2
1{ "Hello": "World" }<Hello>World</Hello>B组
1{ "Hello": "World" }<Hello>World</Hello>嵌套选项卡视图和颜色
如果要嵌套选项卡视图,则需要使用{{< tab >}}而不是{{% tab %}}。请注意,在这种情况下,无法将 markdown 放在父选项卡中。
您还可以为所有选项卡设置样式和颜色参数,并在选项卡级别覆盖它们。有关可能的值,请参阅tab选项卡简码。
{{< tabs groupid="main" style="primary" title="Rationale" icon="thumbtack" >}}
{{< tab title="Text" >}}
Simple text is possible here...
{{< tabs groupid="tabs-example-language" >}}
{{% tab title="python" %}}
Python is **super** easy.
- most of the time.
- if you don't want to output unicode
{{% /tab %}}
{{% tab title="bash" %}}
Bash is for **hackers**.
{{% /tab %}}
{{< /tabs >}}
{{< /tab >}}
{{< tab title="Code" style="default" color="darkorchid" >}}
...but no markdown
{{< tabs groupid="tabs-example-language" >}}
{{% tab title="python" %}}
```python
print("Hello World!")
```
{{% /tab %}}
{{% tab title="bash" %}}
```bash
echo "Hello World!"
```
{{% /tab %}}
{{< /tabs >}}
{{< /tab >}}
{{< /tabs >}} Rationale
Simple text is possible here...
Python is super easy.
- most of the time.
- if you don’t want to output unicode
Bash is for hackers.
...but no markdown
print("Hello World!")echo "Hello World!"4.2 git 文档
Git 是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。
Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。
Git 与常用的版本控制工具 CVS, Subversion 等不同,它采用了分布式版本库的方式,不必服务器端软件支持。
Git 与 SVN 区别
Git 不仅仅是个版本控制系统,它也是个内容管理系统(CMS),工作管理系统等。
如果你是一个具有使用 SVN 背景的人,你需要做一定的思想转换,来适应 Git 提供的一些概念和特征。
Git 与 SVN 区别点:
Git 是分布式的,SVN 不是:这是 Git 和其它非分布式的版本控制系统,例如 SVN,CVS 等,最核心的区别。
Git 把内容按元数据方式存储,而 SVN 是按文件:所有的资源控制系统都是把文件的元信息隐藏在一个类似 .svn、.cvs 等的文件夹里。
Git 分支和 SVN 的分支不同:分支在 SVN 中一点都不特别,其实它就是版本库中的另外一个目录。
Git 没有一个全局的版本号,而 SVN 有:目前为止这是跟 SVN 相比 Git 缺少的最大的一个特征。
Git 的内容完整性要优于 SVN:Git 的内容存储使用的是 SHA-1 哈希算法。这能确保代码内容的完整性,确保在遇到磁盘故障和网络问题时降低对版本库的破坏。
教程网址
中文教程:Git 教程 英文教程:Git Tutorial 菜鸟教程:Git 教程
4.3 MD 语法
Markdown是一种轻量级标记语言,排版语法简洁,让人们更多地关注内容本身而非排版。
它使用易读易写的纯文本格式编写文档,可与HTML混编,可导出 HTML、PDF 以及本身的 .md 格式的文件。因简洁、高效、易读、易写,Markdown被大量使用,如Github、Wikipedia、简书等。
可通过中文官网学习相关的Markdown语法。
5 教程系列
目录
教程系列 的子部分
5.1 编译原理
目录
引言
编译原理是将文本字符流,通过一系列的分析、转换,最后生成确定的指令文件的数据分析转换技术。
编译器是利用编译原理,将一种程序(源程序)翻译成另一种程序(目标程序)的计算机程序。业界也将编译器分为三个部分:前端、中端、后端。
编译器所做的工作流程如下图所示。

编译原理 的子部分
第1章
词法分析
1 序
词法分析就是将代码字符流,按照一定的规则进行分析,获取符合词法规则的字符串,并进行信息标注,为语法分析提供单词(Token)流。
2 目录
词法分析 的子部分
1.1 Token 定义
1 词法规则
词法分析按照规定的规则,可以从字符流中获取数据。
规则定义为以下几类:
- 标识符:由字母、数字、下划线( _ )构成,但是不得由数字为起始;其中存在特殊的字符串为关键字。
- 普通数字字面量:由数字和’.‘组成,其中分为整数、浮点数;
- 2进制数字字面量:由 ‘0B’起始,多个 ‘0’或'1’构成。
- 16进制数字字面量:由 ‘0X’起始,多个 十六进制字符 构成。
- 字符字面量:由 ‘‘‘起始和结尾,中间为可打印的字符。
2 Token 分类
3 位置信息
3 Token 定义
1.2 Lexer 实现
待续
1.3 工程文件解析
待续
第2章
语法分析
1 序
语法分析就是将词法分析提供单词(Token)流,按照语法规则构建抽象语法分析树,为语义分析提供数据骨架。
2 目录
语法分析 的子部分
2.1 类型系统设计与实现
待续
2.2 抽象语法树设计与实现
待续
2.3 代码文件文件管理
待续
2.4 顶层语法解析实现
待续
2.5 解析表达式
待续
2.6 解析声明
待续
2.7 解析声明续
待续
第3章
语义分析
1 序
语义分析就是分析语法树中所有的符号是否存在声明,从语义层次进一步规范程序所表达的含义。
- 分析符号的含义和类型。
- 分析变量的位置偏移。
- 分析表达式的类型,并进行类型匹配。
2 目录
第4章
中间优化
第5章
目标生成
第6章
中间代码
第7章
指令集
1 序
指令集可分为两大类,真实硬件指令集和虚拟机指令集。
真实硬件指令集又分为两类:
- CISC (复杂指令集):CISC 以 X86 系列为代表,指令系统较为复杂,硬件实现也比较复杂。
- RISC (精简指令集):RISC 的指令系统较为精简,目的是降低硬件实现的复杂度,以 RISC-V 、ARM为代表。
虚拟机指令集可分为三种:
- 基于栈的指令集:纯栈操作,所有的运算都基于栈,其中以 Java 字节码指令集为代表。
- 基于寄存器的指令集:纯寄存器操作,所有的运算基于寄存器,其中以安卓的 Dalvik 字节码指令集为代表。
- 基于栈和寄存器的指令集:混合式操作,类似于 RISC 指令集,但是又与真实硬件系统有差异。
虚拟机的指令与设计的字节码保存文件存在较强相关性,所以要真正理解虚拟机指令,还需要理解字节码文件的存储格式。
2 目录
指令集 的子部分
7.1 基于栈的指令集
基于栈的指令集参考Java的指令集。
7.2 基于寄存器的指令集
Dalvik 字节码指令集的字节码指令集不支持无符号整数运算,因此参照 Dalvik 设计了以下指令集。
基于纯寄存器的指令集,指令系统存在下列的要求:
- 每条指令按照 16 bit 对齐。
- 寄存器的索引位宽有 4 bit、8 bit、16 bit。
- 最多支持 65536 个寄存器。
- 每个寄存器 32 bit。
- 64 bit寄存器由相邻的两个 32 bit 寄存器组合而成。
- 指令操作码位宽为 8 bit。
- 指令中可有子操作码,具体位宽看具体的指令格式。
- 32 bit 寄存器内可以存储 32 bit的整数、浮点数。
- 64 bit 寄存器内可以存储 64 bit的整数、浮点数。
- 位宽小于 32 位的值,需要进行扩展(零扩展、符号扩展)到 32 bit。
- 助记符中的 I 表示寄存器索引,后面的数字表示索引位宽
指令格式
总体格式:
操作码 + [ 操作子码 ] + ( 操作数 )*
- 操作子码可选。
- 操作数可以有多个。
寄存器位宽索引支持的寄存器数量:
| 位宽 | 寄存器数量 | 索引范围 |
|---|---|---|
| 4 bit | 16 | [ 0, 15 ] |
| 8 bit | 256 | [ 0, 255 ] |
| 16 bit | 65536 | [ 0, 65535 ] |
空指令
文本格式: nop
| 助记符 | 操作码 | 对齐 | 注解 |
|---|---|---|---|
| 格式 | 8 bit | 8bit | 指令宽度:16 bit |
| nop | 0 | 空操作,用于对齐 |
常量赋值指令
文本格式: op des, imm
| 助记符 | 操作码 | 目的寄存器 | 立即数 | 注解 |
|---|---|---|---|---|
| 8 bit | 4 bit | 4 bit | 4 bit 立即数,指令宽度:16 bit | |
| const-w32-I4-i4 | des | imm | imm 为有符号整数,有符号扩展至 32 bit。 | |
| const-w64-I4-i4 | des | imm | imm 为有符号整数,有符号扩展至 32 bit。 | |
| const-w32-I4-u4 | des | imm | imm 为无符号整数,无符号扩展至 32 bit。 | |
| const-w64-I4-u4 | des | imm | imm 为无符号整数,无符号扩展至 32 bit。 | |
| 8 bit | 8 bit | 16 bit | 16 bit 立即数,指令宽度:32 bit | |
| const-w32-I8-i16 | des | imm | imm 为有符号整数,有符号扩展至 32 bit。 | |
| const-w64-I8-i16 | des | imm | imm 为有符号整数,有符号扩展至 64 bit。 | |
| const-w32-I8-u16 | des | imm | imm 为无符号整数,无符号扩展至 32 bit。 | |
| const-w64-I8-u16 | des | imm | imm 为无符号整数,无符号扩展至 64 bit。 | |
| const-w32-I8-L16 | des | imm | imm 为无符号整数。imm 存放在寄存器的低 16 bit,不改变高 16 bit。 | |
| const-w32-I8-H16 | des | imm | imm 为无符号整数。imm 存放在寄存器的高 16 bit,不改变低 16 bit。 | |
| 8 bit | 8 bit | 32 bit | 32 bit 立即数,指令宽度:48 bit | |
| const-w32-I8 | des | imm | 原样拷贝,支持32 bit 整数和浮点。 | |
| const-w64-I8-i32 | des | imm | imm 为有符号整数,有符号扩展至 64 bit。 | |
| const-w64-I8-u32 | des | imm | imm 为无符号整数,无符号扩展至 64 bit。 | |
| 8 bit | 8 bit | 64 bit | 64 bit 立即数,指令宽度:80 bit | |
| const-w64-I8 | des | imm | 原样拷贝,支持64 bit整数和浮点。 |
文本格式:op.sub des,imm
| 助记符 | 操作码 | 操作子码 | 目的寄存器 | 立即数 | 注解 |
|---|---|---|---|---|---|
| 8 bit | 8 bit | 8 bit | 8 bit | 指令宽度:32 bit | |
| const-w32-I8 | subop | des | imm | imm 为无符号整数 |
操作子码定义
| 助记符 | 操作子码 | 注解 |
|---|---|---|
| B0 | imm存放在寄存器的第 1 个字节,不改变其他字节。 | |
| B1 | imm存放在寄存器的第 2 个字节,不改变其他字节。 | |
| B2 | imm存放在寄存器的第 3 个字节,不改变其他字节。 | |
| B3 | imm存放在寄存器的第 4 个字节,不改变其他字节。 |
寄存器赋值指令
文本格式:op des,src
文本格式:op des,src
| 助记符 | 操作码 | 目的寄存器 | 源寄存器 | 注解 |
|---|---|---|---|---|
| 8 bit | 4 bit | 4 bit | 指令宽度:16 bit | |
| move-w32-I4 | des | src | 32 位寄存器值传递 | |
| move-w64-I4 | des | src | 64 位寄存器值传递 | |
| 8 bit | 8 bit | 16 bit | 指令宽度:32 bit | |
| move-w32-I8I16 | des | src | 32 位寄存器值传递 | |
| move-w64-I8I16 | des | src | 64 位寄存器值传递 |
文本格式:op.sub des,src
| 助记符 | 操作码 | 操作子码 | 目的寄存器 | 源寄存器 | 注解 |
|---|---|---|---|---|---|
| 8 bit | 8 bit | 8 bit | 8 bit | 指令宽度:32 bit | |
| mov-I8 | sub | des | src | ||
| 8 bit | 8 bit | 16 bit | 16 bit | 指令宽度:48 bit | |
| mov-I16 | sub | des | src |
操作子码定义
助记符含义:
目标位宽-源数据获取转换位宽
- i:符号扩展。
- u:零扩展。
- 只有目标位宽时,表示源位宽直接拷贝传递。
目标类型-源类型
- 表示从源类型转换到目标类型
| 助记符 | 操作子码 | 注解 |
|---|---|---|
| w32-B0-i8 | 0 | 获取寄存器的第 1 个字节,进行符号扩展到 32 位 |
| w32-B0-u8 | 1 | 获取寄存器的第 1 个字节,进行零扩展到 32 位 |
| w32-B1-i8 | 2 | 获取寄存器的第 2 个字节,进行符号扩展到 32 位 |
| w32-B1-u8 | 3 | 获取寄存器的第 2 个字节,进行零扩展到 32 位 |
| w32-B2-i8 | 4 | 获取寄存器的第 3 个字节,进行符号扩展到 32 位 |
| w32-B2-u8 | 5 | 获取寄存器的第 3 个字节,进行零扩展到 32 位 |
| w32-B3-i8 | 6 | 获取寄存器的第 4 个字节,进行符号扩展到 32 位 |
| w32-B3-u8 | 7 | 获取寄存器的第 4 个字节,进行零扩展到 32 位 |
| w32-L16-i16 | 8 | 获取寄存器的低 16 位,进行符号扩展到 32 位 |
| w32-L16-u16 | 9 | 获取寄存器的低 16 位,进行零扩展到 32 位 |
| w32-H16-i16 | 10 | 获取寄存器的高 16 位,进行符号扩展到 32 位 |
| w32-H16-u16 | 11 | 获取寄存器的高 16 位,进行零扩展到 32 位 |
| w32 | 12 | 32 位原值拷贝传递 |
| w64-B0-i8 | 13 | 获取寄存器的第 1 个字节,进行符号扩展到 64 位 |
| w64-B0-u8 | 14 | 获取寄存器的第 1 个字节,进行零扩展到 64 位 |
| w64-B1-i8 | 15 | 获取寄存器的第 2 个字节,进行符号扩展到 64 位 |
| w64-B1-u8 | 16 | 获取寄存器的第 2 个字节,进行零扩展到 64 位 |
| w64-B2-i8 | 17 | 获取寄存器的第 3 个字节,进行符号扩展到 64 位 |
| w64-B2-u8 | 18 | 获取寄存器的第 3 个字节,进行零扩展到 64 位 |
| w64-B3-i8 | 19 | 获取寄存器的第 4 个字节,进行符号扩展到 64 位 |
| w64-B3-u8 | 20 | 获取寄存器的第 4 个字节,进行零扩展到 64 位 |
| w64-L16-i16 | 21 | 获取寄存器的低 16 位,进行符号扩展到 32 位 |
| w64-L16-u16 | 22 | 获取寄存器的低 16 位,进行零扩展到 32 位 |
| w64-H16-i16 | 23 | 获取寄存器的高 16 位,进行符号扩展到 32 位 |
| w64-H16-u16 | 24 | 获取寄存器的高 16 位,进行零扩展到 32 位 |
| w64-i32 | 25 | 获取寄存器的 32 位,进行符号扩展到 64 位 |
| w64-u32 | 26 | 获取寄存器的 32 位,进行零扩展到 64 位 |
| w64 | 27 | 64 位原值拷贝传递 |
| i32-f32 | 28 | 32 位有符号整数转 32 位浮点数 |
| i32-f64 | 29 | 32 位有符号整数转 64 位浮点数 |
| u32-f32 | 30 | 32 位无符号整数转 32 位浮点数 |
| u32-f64 | 31 | 32 位无符号整数转 64 位浮点数 |
| i64-f32 | 32 | 64 位有符号整数转 32 位浮点数 |
| i64-f64 | 33 | 64 位有符号整数转 32 位浮点数 |
| u64-f32 | 34 | 64 位无符号整数转 32 位浮点数 |
| u64-f64 | 35 | 64 位无符号整数转 64 位浮点数 |
| f32-i32 | 36 | 32 位浮点数转 32 位有符号 |
| f32-i64 | 37 | 32 位浮点数转 64 位有符号 |
| f32-u32 | 38 | 32 位浮点数转 32 位无符号 |
| f32-u64 | 39 | 32 位浮点数转 64 位无符号 |
| f32-f64 | 49 | 32 位浮点数转 64 位浮点数 |
| f64-i32 | 41 | 64 位浮点数转 32 位有符号 |
| f64-i64 | 42 | 64 位浮点数转 64 位有符号 |
| f64-u32 | 43 | 64 位浮点数转 32 位无符号 |
| f64-u64 | 44 | 64 位浮点数转 64 位无符号 |
| f64-f32 | 45 | 64 位浮点数转 32 位浮点数 |
数学运算指令
- 有二地址、三地址分类。
- 每类的主操作码不一致。
三地址操作
三地址文本格式: op.sub des,src,src2
| 助记符 | 操作码 | 操作子码 | 目的寄存器 | 源寄存器 | 源操作数 | 注解 |
|---|---|---|---|---|---|---|
| 8 bit | 8 bit | 8 bit | 4 bit | 4 bit | 指令宽度:32 bit | |
| math-I4 | sub | des | src | src2 | ||
| 8 bit | 8 bit | 16 bit | 8 bit | 8 bit | 指令宽度:48 bit | |
| math-I16I8 | sub | des | src | src2 | ||
| 8 bit | 8 bit | 16 bit | 16 bit | 16 bit | 指令宽度:64 bit | |
| math-I16 | sub | des | src | src2 |
子码定义
| 助记符 | 操作子码 | 注解 |
|---|---|---|
| add-int32 | 0 | 32 位有符号 加 + |
| sub-int32 | 1 | 32 位有符号 减 - |
| mul-int32 | 2 | 32 位有符号 乘 * |
| div-int32 | 3 | 32 位有符号 除 / |
| mod-int32 | 4 | 32 位有符号 模 % |
| add-uint32 | 5 | 32 位无符号 加 + |
| sub-uint32 | 6 | 32 位无符号 减 - |
| mul-uint32 | 7 | 32 位无符号 乘 * |
| div-uint32 | 8 | 32 位无符号 除 / |
| mod-uint32 | 9 | 32 位无符号 模 % |
| add-int64 | 10 | 64 位有符号 加 + |
| sub-int64 | 11 | 64 位有符号 减 - |
| mul-int64 | 12 | 64 位有符号 乘 * |
| div-int64 | 13 | 64 位有符号 除 / |
| mod-int64 | 14 | 64 位有符号 |
| add-uint64 | 15 | 64 位无符号 加 + |
| sub-uint64 | 16 | 64 位无符号 减 - |
| mul-uint64 | 17 | 64 位无符号 乘 * |
| div-uint64 | 18 | 64 位无符号 除 / |
| mod-uint64 | 19 | 64 位无符号 模 % |
| add-flt32 | 20 | 32 位浮点 加 + |
| sub-flt32 | 21 | 32 位浮点 减 - |
| mul-flt32 | 22 | 32 位浮点 乘 * |
| div-flt32 | 23 | 32 位浮点 除 / |
| mod-flt32 | 24 | 32 位浮点 模 % |
| add-flt64 | 25 | 64 位浮点 加 + |
| sub-flt64 | 26 | 64 位浮点 减 - |
| mul-flt64 | 27 | 64 位浮点 乘 * |
| div-flt64 | 28 | 64 位浮点 除 / |
| mod-flt64 | 29 | 64 位浮点 模 % |
| sl-w32 | 30 | 32 位 左移 |
| sr-w32 | 31 | 32 位 右移 |
| sra-w32 | 32 | 32 位 算术右移 |
| rol-w32 | 33 | 32 位 循环左移 |
| ror-w32 | 34 | 32 位 循环右移 |
| and-w32 | 35 | 32 位 位与 |
| or-w32 | 36 | 32 位 位或 |
| xor-w32 | 37 | 32 位 位异或 |
| sl-w64 | 38 | 64 位 左移 |
| sr-w64 | 39 | 64 位 右移 |
| sra-w64 | 40 | 64 位 算术右移 |
| rol-w32 | 41 | 64 位 循环左移 |
| ror-w32 | 42 | 64 位 循环右移 |
| and-w64 | 43 | 64 位 位与 |
| or-w64 | 44 | 64 位 位或 |
| xor-w64 | 45 | 64 位 位异或 |
| andl-w32 | 46 | 32 位 逻辑与 |
| orl-w32 | 47 | 32 位 逻辑或 |
| cmp-int32 | 48 | src < src2 : des=-1 |
| cmp-uint32 | 49 | src == src2 : des=0 |
| cmp-int64 | 50 | src > src2 : des=1 |
| cmp-uint64 | 51 | |
| cmp-flt32 | 52 | |
| cmp-flt64 | 53 | |
二地址操作
二地址文本格式: op.sub des,src
| 助记符 | 操作码 | 操作子码 | 目的寄存器 | 源寄存器 | 源操作数 | 注解 |
|---|---|---|---|---|---|---|
| 8 bit | 8 bit | 8 bit | 8 bit | 指令宽度:32 bit | ||
| math-I8 | sub | des | src | |||
| 8 bit | 8 bit | 16 bit | 16 bit | 指令宽度:48 bit | ||
| math-I16 | sub | des | src |
子码定义
| 助记符 | 操作子码 | 注解 |
|---|---|---|
| not-w32 | 0 | 32 位 按位取反 |
| not-w64 | 1 | 64 位 按位取反 |
| inv-w32 | 2 | 32 位 逻辑取反 |
| inv-w64 | 3 | 64 位 逻辑取反 |
| neg-int32 | 4 | 32 位 符号取反 |
| neg-int64 | 5 | 64 位 符号取反 |
| neg-flt32 | 6 | 32 位 符号取反 |
| neg-flt64 | 7 | 64 位 符号取反 |
| abs-int32 | 8 | 32 位 取绝对值 |
| abs-int64 | 9 | 64 位 取绝对值 |
| abs-flt32 | 10 | 32 位 取绝对值 |
| abs-flt64 | 11 | 64 位 取绝对值 |
| sin-flt32 | 12 | 三角函数 |
| cos-flt32 | 13 | 三角函数 |
| tan-flt32 | 14 | 三角函数 |
| asin-flt32 | 15 | 三角函数 |
| acos-flt32 | 16 | 三角函数 |
| atan-flt32 | 17 | 三角函数 |
| sin-flt64 | 18 | 三角函数 |
| cos-flt64 | 19 | 三角函数 |
| tan-flt64 | 20 | 三角函数 |
| asin-flt64 | 21 | 三角函数 |
| acos-flt64 | 22 | 三角函数 |
| atan-flt64 | 23 | 三角函数 |
跳转指令
直接跳转指令
文本格式: goto imm
| 助记符 | 操作码 | 对齐 | 立即数 | 注解 |
|---|---|---|---|---|
| 8 bit | 8 bit | 指令宽度: 16 bit | ||
| goto8 | imm | 8 bit有符号偏移 | ||
| 8 bit | 8 bit | 16 bit | 指令宽度: 32 bit | |
| goto16 | imm | |||
| 8 bit | 8 bit | 32 bit | 指令宽度: 48 bit | |
| goto32 | imm |
分支跳转指令
文本格式
jbr src,src2,imm
jbr src,imm
- 类型编码:标识操作数的类型。
- 操作子码:标识比较方法。
- 和 0 比较时,无源操作数 src2。
| 助记符 | 操作码 | 操作子码 | 类型码 | 源操作数 | 源操作数 | 立即数 | 注解 |
|---|---|---|---|---|---|---|---|
| 8 bit | 4 bit | 4 bit | |||||
| 8 bit | 8 bit | 16 bit | 指令宽度: 32 bit | ||||
| 8 bit | 8 bit | 32 bit | 指令宽度: 32 bit | ||||
| 16 bit | 16 bit | 16 bit | 指令宽度: 32 bit | ||||
| 16 bit | 16 bit | 32 bit | 指令宽度: 32 bit | ||||
| src | src2 | imm |
操作子码
| 助记符 | 操作子码 | 注解 |
|---|---|---|
| eq | 0 | if( src == src2 ) goto imm |
| ne | 1 | if( src != src2 ) goto imm |
| lt | 2 | if( src < src2 ) goto imm |
| le | 3 | if( src <= src2 ) goto imm |
| gt | 4 | if( src > src2 ) goto imm |
| ge | 5 | if( src >= src2 ) goto imm |
| eqz | 6 | if( src == 0 ) goto imm |
| nez | 7 | if( src != 0 ) goto imm |
| ltz | 8 | if( src < 0 ) goto imm |
| lez | 9 | if( src <= 0 ) goto imm |
| gtz | 10 | if( src > 0 ) goto imm |
| gez | 11 | if( src >= 0 ) goto imm |
注意: 和 0 比较时,无源操作数 src2。
类型码
| 助记符 | 操作子码 | 注解 |
|---|---|---|
| int32 | 0 | 32 位有符号比较 |
| uint32 | 1 | 32 位无符号比较 |
| int64 | 2 | 64 位有符号比较 |
| uint64 | 3 | 64 位无符号比较 |
| flt32 | 4 | 32 位浮点数比较 |
| flt64 | 5 | 64 位浮点数比较 |
返回指令
文本格式: op src op imm
| 助记符 | 操作码 | 操作子码 | 立即数码 | 源操作数 | 注解 |
|---|---|---|---|---|---|
| 8 bit | 8 bit | 指令宽度: 16 bit | |||
| return-void | 无参数返回 | ||||
| return-w32-I8 | 返回 32 bit 值 | ||||
| return-w64-I8 | 返回 64 bit 值 | ||||
| 8 bit | 4 bit | 4 bit | 16/32/64 bit |
操作子码
| 助记符 | 操作子码 | 注解 |
|---|---|---|
| I16 | 0 | 寄存器索引16位 |
| int32 | 1 | 立即数转换到32位有符号整数 |
| uint32 | 2 | 立即数转换到32位有符号整数 |
| int64 | 3 | 立即数转换到32位有符号整数 |
| uint64 | 4 | 立即数转换到32位有符号整数 |
| flt32 | 5 | 立即数转换到32位有符号整数 |
| flt64 | 6 | 立即数转换到32位有符号整数 |
立即数码
| 助记符 | 操作子码 | 注解 |
|---|---|---|
| B16 | 0 | 16 位立即数 |
| B32 | 1 | 32 位立即数 |
| B64 | 2 | 64 位立即数 |
函数调用指令
不固定参数调用
文本格式:op argcnt, arg,arg2,…,func
| 助记符 | 操作码 | 参数个数 | 参数寄存器 | 函数 | 注解 |
|---|---|---|---|---|---|
| 8 bit | 8 bit | 16 bit | 32 bit | ||
| invoke-virtual-nofix | argcnt | arg… | func | 调用虚函数 | |
| invoke-direct-nofix | argcnt | arg… | func | 直接调用函数 | |
| invoke-static-nofix | argcnt | arg… | func | 调用静态函数 | |
| invoke-interface-nofix | argcnt | arg… | func | 调用接口函数 | |
| invoke-native-nofix | argcnt | arg… | func | 调用C语言函数 |
范围参数调用
文本格式:op argcnt,start, end,func
| 助记符 | 操作码 | 参数个数 | 起始寄存器 | 结束寄存器索引 | 函数 | 注解 |
|---|---|---|---|---|---|---|
| 8 bit | 8 bit | 16 bit | 16 bit | 32 bit | ||
| invoke-virtual-range | argcnt | arg… | func | 调用虚函数 | ||
| invoke-direct-range | argcnt | arg… | func | 直接调用函数 | ||
| invoke-static-range | argcnt | arg… | func | 调用静态函数 | ||
| invoke-interface-range | argcnt | arg… | func | 调用接口函数 | ||
| invoke-native-range | argcnt | arg… | func | 调用C语言函数 |
获取返回值指令
文本格式:op des
| 助记符 | 操作码 | 对齐 | 源寄存器 | 注解 |
|---|---|---|---|---|
| 8 bit | 8 bit | 指令宽度: 16 bit | ||
| get-result-w32-I8 | des | 获取32位返回值 | ||
| get-result-w64-I8 | des | 获取64位返回值 | ||
| get-result-obj-I8 | des | 获取对象返回值 | ||
| 8 bit | 8 bit | 16 bit | 指令宽度: 32 bit | |
| get-result-w32-I16 | des | 获取32位返回值 | ||
| get-result-w64-I16 | des | 获取64位返回值 | ||
| get-result-obj-I16 | des | 获取对象返回值 |
异常处理指令
文本格式:op des
| 助记符 | 操作码 | 对齐 | 源寄存器 | 注解 |
|---|---|---|---|---|
| 8 bit | 8 bit | 指令宽度: 16 bit | ||
| get-exception-I8 | des | 获取异常对象 | ||
| throw-I8 | src | 抛出异常对象 | ||
| 8 bit | 8 bit | 16 bit | 指令宽度: 32 bit | |
| get-exception-I16 | des | 获取异常对象 | ||
| throw-I16 | src | 抛出异常对象 |
7.3 基于栈和寄存器的指令集
本章节描述的是作者按照 RISC 指令系统设计的虚拟机指令集。
其类似与硬件指令集,可作为编译器后端指令系统目标,用于提供类似硬件指令系统环境,避免编译原理初学者陷入对硬件指令系统不了解的深渊。 降低学习难度,提高学习效率。
这类指令的主要特点如下:
- 1 寄存器的数量固定;
- 2 指令所操作的寄存器数量固定;
- 3 指令的含义简单;
1 寄存器
虚拟机的寄存器分为三种:
- 1 整数寄存器:主要用于整数运算,位宽为 64 bit,根据指令的含义可选择 32 bit 和 64 bit 运算模式。
- 2 浮点寄存器:主要用于浮点数运算,位宽为 64 bit,和通用寄存器一致,可选择位宽模式。
- 3 系统寄存器:对用户不可见,与虚拟机运行系统相关,对其进行操作隐藏在相关指令的实现细节中。
- 4 根据指令格式,整数寄存器、浮点寄存器最多可以有32个。
2 指令格式
每条指令是 32bit 大小对齐的,其中最低 9bit 是操作码,其余23bit作为操作数或者操作码的补充。如下表所示:
| 操作码 | 操作数 |
|---|---|
| 9 bit | 23 bit |
2.1 格式1
| 操作码 | 操作数 |
|---|---|
| 9 bit | 23 bit |
2.2 格式2
多数指令使用此格式。
| 操作码 | 目的操作数 | 源操作数 | 源操作数 | 操作子码 |
|---|---|---|---|---|
| 9 bit | 5 bit | 5 bit | 5 bit | 8 bit |
2.3 格式3
该格式主要用于比较指令后的三元选择赋值操作。
| 操作码 | 目的操作数 | 源操作数 | 源操作数 | 源操作数 | 操作子码 |
|---|---|---|---|---|---|
| 9 bit | 5 bit | 5 bit | 5 bit | 5 bit | 3 bit |
2.4 格式4
当指令中需要使用立即数时,且在指令中没有足够的空间可以存储时,可以使用指令后跟32bit对齐的立即数操作数。
- 32bit立即数:32bit 指令跟 1 个 32bit 立即数,虚拟机解析执行时,按照指令表达的语义参与运算。
- 64bit立即数:32bit 指令跟 2 个 32bit 立即数,虚拟机解析执行时,按照指令表达的语义,组合成 64bit,后参与运算。
- 其他位宽的立即数类似。
格式如下所示:
| 指令 | 立即数 1 | 立即数 2 | … | 立即数 n |
|---|---|---|---|---|
| 32 bit | 32 bit | 32 bit | … | 32 bit |
3 寄存器与寄存器—指令集
3.1 空指令
空指令一般用于对齐,在本指令集中没有特殊含义,执行空操作。
格式如下:
| 助记符 | 操作码 | 操作数 |
|---|---|---|
| 9 bit | 23 bit | |
| Nop | 0 | 0 |
3.2 算术运算
算术运算包含 +、-、*、/、%,支持的运算类型有 int32、uint32、int64、uint64、flt32、flt64。
- 文本格式: op des,src,src2
- 指令含义:des = src op src2
- 子操作码:可以用于将运算结果进行截断、扩展。
- 助记符后缀的数字(32、64)标识指令运算使用的寄存器位宽。
- 助记符后缀的 i 表示进行有符号运算。
- 助记符后缀的 u 表示进行无符号运算。
- 助记符后缀的 f 表示进行有符号运算。
指令格式如下所示:
| 助记符 | 操作码 | 目的操作数 | 源操作数 | 源操作数 | 操作子码 |
|---|---|---|---|---|---|
| 9 bit | 5 bit | 5 bit | 5 bit | 8 bit | |
| add-i32 | des | src | src2 | ||
| sub-i32 | des | src | src2 | ||
| mul-i32 | des | src | src2 | ||
| div-i32 | des | src | src2 | ||
| mod-i32 | des | src | src2 | ||
| add-u32 | des | src | src2 | ||
| sub-u32 | des | src | src2 | ||
| mul-u32 | des | src | src2 | ||
| div-u32 | des | src | src2 | ||
| mod-u32 | des | src | src2 | ||
| add-i64 | des | src | src2 | ||
| sub-i64 | des | src | src2 | ||
| mul-i64 | des | src | src2 | ||
| div-i64 | des | src | src2 | ||
| mod-i64 | des | src | src2 | ||
| add-u64 | des | src | src2 | ||
| sub-u64 | des | src | src2 | ||
| mul-u64 | des | src | src2 | ||
| div-u64 | des | src | src2 | ||
| mod-u64 | des | src | src2 | ||
| add-f32 | des | src | src2 | ||
| sub-f32 | des | src | src2 | ||
| mul-f32 | des | src | src2 | ||
| div-f32 | des | src | src2 | ||
| add-f64 | des | src | src2 | ||
| sub-f64 | des | src | src2 | ||
| mul-f64 | des | src | src2 | ||
| div-f64 | des | src | src2 |
3.2 位运算
位运算包括位相关的与、或、非、异或、移位、取反等运算。
支持的运算类型有 uint32、uint64。
- 文本格式: op des,src,src2
- 指令含义:des = src op src2
- 子操作码:可以用于将运算结果进行截断、扩展。
- i32:表示进行 32bit 的位运算。
- i64:表示进行 64bit 的位运算。
- 位运算都是看作无符号运算。
指令格式如下所示:
| 助记符 | 操作码 | 目的操作数 | 源操作数 | 源操作数 | 操作子码 |
|---|---|---|---|---|---|
| 9 bit | 5 bit | 5 bit | 5 bit | 8 bit | |
| sl-i32 | des | src | src2 | ||
| sr-i32 | des | src | src2 | ||
| sra-i32 | des | src | src2 | ||
| and-i32 | des | src | src2 | ||
| or-i32 | des | src | src2 | ||
| xor-i32 | des | src | src2 | ||
| andn-i32 | des | src | src2 | ||
| orn-i32 | des | src | src2 | ||
| xorn-i32 | des | src | src2 | ||
| not-i32 | des | src | src2 | ||
| sl-i64 | des | src | src2 | ||
| sr-i64 | des | src | src2 | ||
| sra-i64 | des | src | src2 | ||
| and-i64 | des | src | src2 | ||
| or-i64 | des | src | src2 | ||
| xor-i64 | des | src | src2 | ||
| andn-i64 | des | src | src2 | ||
| orn-i64 | des | src | src2 | ||
| xorn-i64 | des | src | src2 | ||
| not-i64 | des | src | src2 |
3.3 逻辑比较
逻辑比较运算包括:<、>、<=、>=、==、!=、 ==0、!=0. 支持的运算类型有 int32、uint32、int64、uint64、flt32\flt64。
- 文本格式: op des,src,src2
- 指令含义:des = src op src2
- 子操作码:可以用于标识比较的方法。
- 比较的结果,存储在整数寄存器中,且使用位宽 64 bit,即des是整数寄存器。
指令格式如下所示:
| 助记符 | 操作码 | 目的操作数 | 源操作数 | 源操作数 | 操作子码 |
|---|---|---|---|---|---|
| 9 bit | 5 bit | 5 bit | 5 bit | 8 bit | |
| cmp-i32 | des | src | src2 | ||
| cmp-u32 | des | src | src2 | ||
| cmp-i64 | des | src | src2 | ||
| cmp-u64 | des | src | src2 | ||
| cmp-f32 | des | src | src2 | ||
| cmp-f64 | des | src | src2 |
操作子码定义如下:
| 助记符 | 操作码 | 含义 |
|---|---|---|
| lt | < | |
| le | <= | |
| gt | > | |
| ge | >= | |
| eq | == | |
| ne | != | |
| ez | ==0,此时没有源操作数src2 | |
| nz | !=0,此时没有源操作数src2 |
当不使用操作子码,而是使用下面方式运算:
- src < src2,设置des寄存器为 -1。
- src == src2,设置des寄存器为 0。
- src > src2,设置des寄存器为 -1。
3.4 条件赋值
条件赋值指令使用比较指令的结果,对另外 2 个源操作数进行选择,传递个目标操作数。
指令格式如下所示:
| 助记符 | 操作码 | 目的操作数 | 源操作数 | 源操作数 | 源操作数 | 操作子码 |
|---|---|---|---|---|---|---|
| 9 bit | 5 bit | 5 bit | 5 bit | 5 bit | 3 bit | |
| sel-i32 | des | src | src2 | cond | ||
| sel-u32 | des | src | src2 | cond | ||
| sel-i64 | des | src | src2 | cond | ||
| sel-u64 | des | src | src2 | cond | ||
| sel-f32 | des | src | src2 | cond | ||
| sel-f64 | des | src | src2 | cond |
当比较系列指令使用操作子码方式时:
- cond == 0 :des = src
- cond != 0 :des = src2
当比较系列指令不使用操作子码方式时,本系列指令要求使用操作子码进行判断:
操作子码定义如下:
| 助记符 | 操作码 | 含义 |
|---|---|---|
| lt | < :des = cond == -1 ? src : src2 | |
| le | <= :des = cond < 1 ? src : src2 | |
| gt | > :des = cond == 1 ? src : src2 | |
| ge | >= :des = cond > -1 ? src : src2 | |
| eq | == :des = cond == 0 ? src : src2 | |
| ne | != :des = cond != 0 ? src : src2 |
3.5 赋值指令
此系列包括寄存器间赋值或类型转换。
| 助记符 | 操作码 | 目的操作数 | 源操作数 | 源操作数 | 操作子码 |
|---|---|---|---|---|---|
| 9 bit | 5 bit | 5 bit | 5 bit | 8 bit | |
| mov | des | src |
操作子码用于获取源操作数并转换到响应的类型。
操作子码定义如下:
| 助记符 | 操作码 | 含义 |
|---|---|---|
| i8-i32 | ||
| u8-i32 | ||
| i8-i64 | ||
| u8-u64 | ||
| i16-i32 | ||
| u16-i32 | ||
| i16-i64 | ||
| u16-i64 | ||
| i32_i32 | ||
| i32-i64 | ||
| i32-f32 | ||
| i32-f64 | ||
| u32-u32 | ||
| u32-u64 | ||
| u32-f32 | ||
| u32-f64 | ||
| i64-i64 | ||
| i64-f32 | ||
| i64-f64 | ||
| u64-u64 | ||
| u64-f32 | ||
| u64-f64 | ||
| f32-i32 | ||
| f32-u32 | ||
| f32-i64 | ||
| f32-u64 | ||
| f32-f32 | ||
| f32-f64 | ||
| f64-i32 | ||
| f64-u32 | ||
| f64-i64 | ||
| f64-u64 | ||
| f64-f32 | ||
| f64-f64 | ||
| f32-bit-u32 | 位转换 | |
| u32-bit-f32 | 位转换 | |
| f64-bit-u64 | 位转换 | |
| u64-bit-f64 | 位转换 |
3.6 加载存储指令
此系列指令功能是从内存中读取、存储特定类型数据。
| 助记符 | 操作码 | 目的操作数 | 源操作数 | 源操作数 | 操作子码 | 注释 |
|---|---|---|---|---|---|---|
| 9 bit | 5 bit | 5 bit | 5 bit | 8 bit | ||
| load | des | base | offset | 从基址内存中获取数据 | ||
| store | des | base | offset | |||
| gload | des | base | offset | 从全局内存中获取数据 | ||
| gstore | des | base | offset |
操作子码定义如下:
| 助记符 | 操作码 | 含义 |
|---|---|---|
| i8 | ||
| u8 | ||
| i16 | ||
| u16 | ||
| i32 | ||
| u32 | ||
| i64 | ||
| u64 | ||
| f32 | ||
| f64 |
3.7 出入栈指令
此系列指令用于将数据入栈,同时可以进行类型转换。 注意:入栈数据应当进行 32bit 对齐。以加快虚拟机执行速度数据
| 助记符 | 操作码 | 目的操作数 | 源操作数 | 源操作数 | 操作子码 |
|---|---|---|---|---|---|
| 9 bit | 5 bit | 5 bit | 5 bit | 8 bit | |
| push | des | ||||
| pop | des | ||||
| 操作子码定义如下: | |||||
| 助记符 | 操作码 | 含义 | |||
| — | — | — | |||
| i8 | |||||
| u8 | |||||
| i16 | |||||
| u16 | |||||
| i32 | |||||
| u32 | |||||
| i64 | |||||
| u64 | |||||
| f32 | |||||
| f64 |
3.8 栈内存分配释放
此系列指令用于栈内存分配释放。 注意:立即数是无符号整数。
| 助记符 | 操作码 | 目的操作数 | 立即数 | 注释 |
|---|---|---|---|---|
| 9 bit | 5 bit | 18 bit | ||
| grown | des | imm | 分配栈内存,将分配后的栈指针值传递到 des 寄存器 | |
| 9 bit | 23 bit | 释放栈内存, | ||
| shrunk | imm |
3.9 跳转指令
- 跳转的偏移量是无符号整数值;
- 相对于函数代码的起始地址;
- 偏移量是偏移的指令条数;
| 助记符 | 操作码 | 目的操作数 | 立即数 | 注释 |
|---|---|---|---|---|
| 9 bit | 23 bit | |||
| jmp | imm | 直接跳转 | ||
| 9 bit | 5 bit | 18 bit | ||
| jmpx | reg | 偏移量在 reg 寄存器中 | ||
| 9 bit | 5 bit | 18 bit | ||
| jtab | reg | imm | reg 表示偏移量索引,imm表示偏移量数组中偏移数据条数,指令后面接 32 bit 对齐的偏移量数组 |
3.10 分支指令
此系列指令用于条件分支跳转。
| 助记符 | 操作码 | 目的操作数 | 源操作数 | 源操作数 | 操作子码 | 偏移立即数 |
|---|---|---|---|---|---|---|
| 9 bit | 5 bit | 5 bit | 5 bit | 8 bit | 32 bit | |
| jbr-i32 | src | src2 | cond | offset | ||
| jbr-u32 | src | src2 | cond | offset | ||
| jbr-i64 | src | src2 | cond | offset | ||
| jbr-u64 | src | src2 | cond | offset | ||
| jbr-f32 | src | src2 | cond | offset | ||
| jbr-f64 | src | src2 | cond | offset |
操作子码定义如下:
| 助记符 | 操作码 | 含义 |
|---|---|---|
| lt | < | |
| le | <= | |
| gt | > | |
| ge | >= | |
| eq | == | |
| ne | != | |
| ez | ==0,此时没有源操作数src2 | |
| nz | !=0,此时没有源操作数src2 |
3.11 函数指令
| 助记符 | 操作码 | 目的操作数 | 立即数 | 注释 |
|---|---|---|---|---|
| 9 bit | 23 bit | 32 bit | ||
| call | imm | imm表示函数的偏移量或者是编号,看虚拟机的具体实现 | ||
| 9 bit | 5 bit | 18 bit | ||
| callx | reg | reg 寄存器中保存函数的偏移量或者是编号,看虚拟机的具体实现 | ||
| 9 bit | 23 bit | |||
| ret | 函数返回 |
4 寄存器与立即数–指令集
待续
第8章
语言定义
air语言是C语法系的编程语言,提供面向对象、函数式、模板等高级语言功能。
目录
语言定义 的子部分
8.1 语法定义
语法使用非严格的EBNF语法描述。
文件单元
FileUnit = PkgDef (ImportDef) Decl*
包定义
PkgDef = package ID (.ID)*
依赖导入(可选)
ImportDef = 'import' STRING as ID; |'{' (STRING as ID; )* '}'
声明定义
Decl = ScopeDecl | VarDecl | FuncDecl | EnumDecl | StructDecl | UnionDecl | InterfaceDecl | ClassDecl | EntrustDecl | ~
表达式
Exp = BaseExp | DotExp | UnaryExp | BinaryExp | TernaryExp | NewExp | PriorityExp
基础表达式
BaseExp = IDExp | ConstExp | CallExp | ArrarExp | ThisExp | SuperExp
IDExp = ID
ConstExp = c
CallExp = ID '(' ArgList')'
ArrarExp = ID '[' Exp ']'
ThisExp = 'this'
SuperExp = 'super'
成员访问表达式
DotExp = BaseExp ( '.' BaseExp)* //BaseExp不得是ConstExp
一元表达式
UnaryExp = UnaryOP BaseExp
UnaryOP = '-' | '+' | '--' | '++' | '~' | '!'
二元表达式
BinaryExp = Exp BinaryOP Exp
BinaryOP = '+' | '-' | '*' | '/' | '%' |
'&' | '|' | '&&' | '||' |
'<<' | '>>' | '>>>' |
'<' | '>' | '<=' | '>=' |
'==' | '!=' | '=' |
三元表达式
TernaryExp = Exp '?' Exp ':' Exp
括号表达式
PriorityExp = '(' Exp ')'
作用域声明
ScopeDecl = ( 'public' | 'protected' | 'private' ) ':'
变量声明
VarDecl = Scope Type 'id' [=initExp] ';'
Scope = ['public' | 'protected' | 'private'| 'extern' | 'static']
Type = ['const' ] 'id'( '.' 'id')*
代理变量
Scope Type 'id''(' [ arglist] ')' 'delegate' ';'
闭包变量
Scope Type 'id''(' [ arglist] ')' 'closure' ';'
函数申明
VarDecl = Scope Type 'id''(' [ arglist] ')'[@override] [@cfun] [const] [final] (';' | funbody )
arglist = argitem (',' argitem)*
argitem = type ['id']
funbody = BlkState
BlkState = '{' [Statement] '}'
Statement = ( BlkState | ExpState | IfState | ElseifState |
ElseState | SwitchState | ForState | DoState |
WhileState | GotoState | BreakState | ContinueState |
ReturnState )*
TypeDecl = EnumDecl | StructDecl | UnionDecl |EntrustDecl
FuncDecl = Type 'id''(' [ arglist] ')' '=' Serial
Serial = 'u32'
枚举声明
EnumDecl = 'enum' id [: BaseType]'{' EnumItem* '}'
BaseType = 基本整数类型
EnumItem = 'id'[=initExp] ','8.2 代码结构
每一个文件都必须定义一个作用域名,其他内容在此作用域定义。
生成的声明符号都在该作用域内,只能通过该作用域才能访问代码文件中声明的符号内容。
代码结构
包声明
package pkg.pkg2;
依赖单元
Import file=“dir/file.ext”;
Import file2=“dir/file2.ext”;
或者
Import{
file=“dir/file.ext” ;
file2=“dir/file2.ext”;
}
枚举定义
enum name : int32{
item=0,
item2=23,
…
}
结构体定义
Struct name{
Int32 i32;
Union{
Int32 s32;
Flt32 f32;
}
}
联合体定义
Union name{
Int32 s32;
Flt32 f32;
Struct{…}
}
接口定义
Interface IFather{
void eat(int32 arg);
}
Interface IFather2{
void say(int32 arg);
}
Interface IChild :[ IFather,IFather2 ]{
void walk(int32 arg);
}
类定义
Class Parent {
Private:
Int32 mI32;
Public Flt32 mF32;
Public:
Void print(){}
Protected void toString(){}
Virtual void vfun()=0;
}
Class child: Parent :[ IChild ]{
void eat(int32 arg) @override{}
void say(int32 arg) @override{}
void walk(int32 arg) @override{}
void vfun()@override{}
}8.3 关键字
airlang 的关键字分为两种:普通关键字,宏关键字。 两者差别不大,但是宏关键字有特殊的标记作用,一般用于注解一些信息。
宏关键字
| 关键字 | 注解 |
|---|---|
| @file | 代码中获取文件的名称字符串 |
| @line | 代码中获取代码所作行号数字 |
| @func | 代码中获取函数声明字符串 |
| @debug | 用于标记只在debug标志下启用的代码 |
| @NotNulptr | 用于标记需要检查函数的指针参数非空 |
| @override | 标记非静态成员函数是重写父类的函数 |
普通关键字
| 固定位宽类型关键字 | 注解 | 位宽(bit) |
|---|---|---|
| void | 空,一般用于表示无返回值 | 0 |
| bool | 布尔类型 | 8 |
| flt32 | 32位单精度浮点 | 32 |
| flt64 | 64位双精度浮点 | 32 |
| int8 | 8位有符号整数 | 8 |
| int16 | 8位有符号整数 | 16 |
| int32 | 8位有符号整数 | 32 |
| int64 | 8位有符号整数 | 64 |
| uint8 | 8位无符号整数 | 8 |
| uint16 | 16位无符号整数 | 16 |
| uint32 | 32位无符号整数 | 32 |
| uint64 | 64位无符号整数 | 64 |
| char | 字符 | 8 |
可变位宽类型的位宽由编译的目标CPU架构有关。
| 可变位宽类型关键字 | 注解 | CPU32 | CPU64 |
|---|---|---|---|
| sint | 有符号整数 | 32 | 64 |
| uint | 无符号整数 | 32 | 64 |
| uintptr | 指针 | 32 | 64 |
| cstring | 字符串指针 | 32 | 64 |
| 修饰关键字 | 注解 |
|---|---|
| static | 静态 |
| public | 完全公开的 |
| protected | 对部分成员公开的 |
| private | 私有的 成员 |
| const | 常量化,只读 |
| friend | 友元定义 |
| 分支关键字 | 注解 |
|---|---|
| if | 比较分支 |
| elsif | 次比较分支 |
| else | 比较默认分支 |
| for | 循环 |
| foreach | 循环 |
| while | 循环 |
| do | 循环 |
| break | 跳出循环 |
| continue | 继续下一轮循环 |
| goto | 跳转到标签 |
| return | 函数返回 |
| 类型定义关键字 | 注解 |
|---|---|
| enum | 枚举 |
| struct | 结构体 |
| union | 联合体 |
| interface | 接口 |
| class | 类 |
| entrust | 委托指针 |
| 其他关键字 | 注解 |
|---|---|
| false | |
| true | |
| nullptr | |
| this | |
| super |
8.4 操作符
成员访问操作符
成员访问操作符的优先级最高。
| 成员访问操作符 | 优先级 | 注解 |
|---|---|---|
| . | 0 | 成员访问 |
| .? | 0 | 带null检查的成员访问 |
一元操作符
一元操作符优先级一致,主要查看其声明的先后顺序。
| 一元操作符 | 优先级 | 注解 |
|---|---|---|
| ~ | -10 | 按位取反 |
| ! | -10 | 逻辑取反 |
| - | -10 | 符号取反 |
| + | -10 | 取绝对值 |
| ++ | -10 | 自增 |
| -- | -10 | 自减 |
二元操作符
在语法解析表达式中,二元表达式最复杂的。
| 二元操作符 | 优先级 | 注解 |
|---|---|---|
| * | -20 | 乘运算操作符 |
| / | -20 | 除运算操作符 |
| % | -20 | 模运算操作符 |
| + | -30 | 加运算操作符 |
| - | -30 | 减运算操作符 |
| << | -40 | 左移操作符 |
| >> | -40 | 逻辑右移操作符 |
| >>> | -40 | 算术右移操作符 |
| < | -50 | 小于操作符 |
| <= | -50 | 小于等于操作符 |
| > | -50 | 大于于操作符 |
| >= | -50 | 大于等于操作符 |
| == | -60 | 等于操作符 |
| != | -60 | 不等于操作符 |
| & | -70 | 位与操作符 |
| ^ | -71 | 位异或操作符 |
| | | -72 | 位或操作符 |
| && | -80 | 逻辑与操作符 |
| || | -81 | 逻辑或操作符 |
三元操作符
三元操作符主要用于比较赋值、简单的比较分支操作。
| 三元操作符 | 优先级 | 注解 |
|---|---|---|
| ? : | -90 |
赋值操作符
赋值类操作符的优先级一致,优先级最低。
| 赋值操作符 | 优先级 | 注解 |
|---|---|---|
| = | -100 | 赋值操作符 |
| *= | -100 | 乘运算复合赋值操作符 |
| /= | -100 | 除运算复合赋值操作符 |
| %= | -100 | 模运算复合赋值操作符 |
| += | -100 | 加运算复合赋值操作符 |
| -= | -100 | 减运算复合赋值操作符 |
| &= | -100 | 位与运算复合赋值操作符 |
| = | -100 | 位或运算复合赋值操作符 |
| ^= | -100 | 位异或运算复合赋值操作符 |
| ~= | -100 | 位取反运算复合赋值操作符 |
| <<= | -100 | 左移运算复合赋值操作符 |
| >>= | -100 | 逻辑右移运算复合赋值操作符 |
| >>>= | -100 | 算术右移运算复合赋值操作符 |
其他操作符
括号表达式中的括号操作符,用于提升表达式的优先级,在算符优先解析算法,该系列是作为基本表达式进行解析的。
| 括号操作符 | 优先级 | 注解 |
|---|---|---|
| () | -10 | 括号操作符 |
| [] | -10 | 数组下标 |
| cast | -10 | 静态类型转换 |
| dyn_cast | -10 | 动态类型转换 |
| () | -10 | 函数调用 |
8.5 类型系统
基本类型
| 固定位宽类型 | 注解 | 位宽(bit) |
|---|---|---|
| void | 空,一般用于表示无返回值 | — |
| bool | 布尔类型 | 8 |
| flt32 | 32位单精度浮点 | 32 |
| flt64 | 64位双精度浮点 | 32 |
| int8 | 8位有符号整数 | 8 |
| int16 | 8位有符号整数 | 16 |
| int32 | 8位有符号整数 | 32 |
| int64 | 8位有符号整数 | 64 |
| uint8 | 8位无符号整数 | 8 |
| uint16 | 16位无符号整数 | 16 |
| uint32 | 32位无符号整数 | 32 |
| uint64 | 64位无符号整数 | 64 |
| char | 字符 | 8 |
可变位宽类型的位宽由编译的目标CPU架构有关。
| 可变位宽类型 | 注解 | CPU32 | CPU64 |
|---|---|---|---|
| sint | 有符号整数 | 32 | 64 |
| uint | 无符号整数 | 32 | 64 |
| uintptr | 指针 | 32 | 64 |
| cstring | 字符串指针 | 32 | 64 |
枚举类型
枚举定义只能是定义整数类的值,其占用的字节数、有无符号性,通过基类标识指定。
如下所示:
enum Color:uint32{
Red,
Black,
}结构体
结构体在airlang中是值类型,不会进入GC系统,除通过API分配独立的堆内存。
一般用于构成类中的共同属性。
struct Vec2{
int32 x;
int32 y;
}
struct Vec3 :Vec2{
int32 z;
}联合体
union Int32{
int32 i32;
struct{
int8 [4] v4;
}
}接口
interface IEvent{
void eat();
}类
class Parent{
int32 i32;
void doing(){}
}
class Child :Parent <IEvent>{
int64 i64;
void eat()@override{}
}委托
entrust Func = void (int32,int64)@clang;6 数据格式
简介
本篇章收集一些文件数据的详细格式格式,为程序开发提供参考。
目录
数据格式 的子部分
第1章
通用格式设计
1 序
二进制文件的格式一般采用结构 文件头 + 核心内容。
- 文件头:标识文件的基本信息,其设计方法基本一致。
- 核心内容:这部分是真正的文件数据内容。
2 目录
通用格式设计 的子部分
1.1 文件头
描述了文件的整体信息,常见的字段有魔数、检验码、版本号、文件大小等。
顾名思义,即是将文件的整体信息通常放在文件的开头。
在少数情况下,也会将文件头放在文件的尾部,也就是‘文件尾’,但是一般还是叫做 文件头。
1 魔数
魔数作为文件格式的标识,一般用于识别文件是否程序所能处理的文件。其值可以随意选取,主要看设计者自身的喜好。
例如 zip 格式的魔数就是 “PK\x03\x04”,其中 PK 就是设计者 Philip Katz 的名字首字母。
一般程序在分析文件时,会先判断魔数的值是否匹配,不匹配就表明文件格式不正确。
需要注意的是,假如魔数正确,文件格式并非一定能够读取正确,还需要进一步判断。
2 检验码
文件头通常还会有个检验码,用于检验文件是否完整并且没有经过修改的。这个检验码可以使用 crc, 可以使用 md5,也可以使用其它算法。
这也是检查文件格式的正确性中的重要一步,因为即便是魔数相同,校验码所采用的算法不同,和校验码所作的位置不同,所计算的校验码,基本上是不一的,所以进一步就,能区分出文件格式是否正确。
3 版本号
文件头通常还会包含版本号。
版本号不同,就表明文件格式发生变化,可能变化很小,也可能变化很大;可能是某些字段的值在解释上发生变化,也可能是直接添加了一些结构。所以导致文件的读取方式可能会有所不同。
版本号有时只是单独一个数字,不断往上递增。有时也会拆分成两个数字,为主版本号和次版本号。主版本号修改,通常表示文件格式发生大变动。而次版本号修改,通常只是表示添加了一些小功能。
4 字节顺序
字节顺序在文件格式设计中至关重要。
字节顺序分为大端字节序和小端字节序。不同的机器字节序有可能不同,设计文件格式时需要考虑文件用什么字节序保存数据的。
读取和存储的字节序不一致就会导致程序出错。
5 通用结构
通用结构定义如下:
struct FileHeader{
uint8 mMagic[4]; //魔数
uint8 mHash[16]; //检验码
uint32 mEndian; //字节序
uint32 mVersion; //文件版本
...
};1.2 段节格式
分段(或叫分节,后续默认叫法为分段)的二进制文件格式是比较常见的,比如编译器 GCC 输出的目标文件一般为 ELF 的分段文件。
1 整体结构
这类文件一般采用 文件头 + 分段 的结构:
file header
section 0
section 1
....
section N
文件头设计方法在 文件头 中介绍,本章节主要描述分段式存储数据的方法。
2 分段方法
一般有两种结构:
- 分散式:在分区的头部的描述分段的大小等信息。
- 段表式:存在统一的结构描述分段的大小、相对偏移等信息。
分散式
分散式分结构在分区的头部的描述分段的大小等信息,然后各个分段首尾相连的,分段写入。
分段的每一个段的结构通常是:
tag + length
section data
tag 和 length 合起来是分区头部,描述分段中的数据标识,后面紧跟着体数据。
tag 一般是一个整数,用来标识分区的类型。不同的分区用不同的 tag 值表示,不同的分区种类可以使用不同的读取方式。
整体结构如下:
file header
section 0
tag //section 0 的标识
length //section 0 的数据长度
data[] //section 0 的数据
section 1
....
section N
段表式
段表式的结构是有一个描述分段信息的段表,后面存储各个分区的数据。
主要优点就是,可以通过段描述表(简称段表)快速的访问分段的内容,其格式如下。
section table
section 0
section 1
....
section N
段表一般描述分段的类型、数据长度、相对偏移等,结构如下。
kind
length
offset
C 语言定义如下:
struct SegTabItem{
uint32 kind; //类型
uint32 length; //数据长度
uint32 offset; //相对偏移
};整体结构如下:
file header
section table
kind //section 0 的类型
length //section 0 的数据长度
offset //section 0 的相对偏移
kind //section 1 的类型
length //section 1 的数据长度
offset //section 1 的相对偏移
...
kind //section N 的类型
length //section N 的数据长度
offset //section N 的相对偏移
section 0
section 1
....
section N1.3 TLV格式
1 简介
TLV 是一种可变的格式,由三个域构成:标识域(Tag)+长度域(Length)+值域(Value),简称TLV格式。
其中:
- T 可以理解为 Tag 或 Type ,用于标识标签或者编码格式信息;
- L 定义数值的长度;
- V 表示实际的数值。
T 和 L 的长度固定,一般是2或4个字节,V 的长度由 Length 指定。
- T 和 L 一般都是整数值。
- V 可以存储整数、浮点、字符串、字节串,其类型是由格式定义者根据 T 的不同值,指定不同的类型。
2 基本结构
data 0
T = 1
L = 1
V = 1
data 1
T = 1
L = 1
V = 2
...
data N
T = 1
L = 1
V = n
当然V中的数据也是可以嵌套,至于嵌套几层看设计者的规定的。
结构如下:
data 0
T = 1
L = 3
V =[
data x
T = 1
L = 1
V = 1
]
data 1
T = 1
L = 1
V = 2
...
data N
T = 1
L = 1
V = n第2章
程序格式
1 序
2 目录
程序格式 的子部分
2.1 ELF 格式
1 序
2 目录
ELF 格式 的子部分
1.1 ELF32 格式
1.2 ELF64 格式
第3章
颜色格式
1 序
颜色常用颜色空间来表示。颜色空间是用一种数学方法形象化表示颜色,人们用它来指定和产生颜色。例如,
- 对于人来说,我们可以通过色调、饱和度和明度来定义颜色;
- 对于显示设备来说,人们使用红、绿和蓝磷光体的发光量来描述颜色;
- 对于打印或者印刷设备来说,人们使用青色、品红色、黄色和黑色的反射和吸收来产生指定的颜色。
颜色空间有设备相关和设备无关之分。
设备相关的颜色空间是指颜色空间指定生成的颜色与生成颜色的设备有关。例如,RGB颜色空间是与显示系统相关的颜色空间,计算机显示器使用RGB来显示颜色,用像素值(例如,R=250,G=123,B=23)生成的颜色将随显示器的亮度和对比度的改变而改变。
设备无关的颜色空间是指颜色空间指定生成的颜色与生成颜色的设备无关,例如,CIE Lab*颜色空间就是设备无关的颜色空间,它构建在HSV(hue, saturation and value)颜色空间的基础上,用该空间指定的颜色无论在什么设备上生成的颜色都相同。
2 目录
颜色格式 的子部分
3.1 RGBA
RGB 的基本概念
RGB 代表红(Red)、绿(Green)、蓝(Blue)。这三种颜色被称为光的三原色。在 RGB 色彩模式下,通过不同强度比例的红、绿、蓝三种光的混合,可以产生出各种各样的颜色。
从物理学角度来看,光是一种电磁波,而人眼能够感知到的可见光波段内,红、绿、蓝这三种颜色的光具有独特的波长范围。红色光的波长大约在 620 - 750 纳米之间,绿色光波长约为 495 - 570 纳米,蓝色光波长则在 450 - 480 纳米左右。当这三种颜色的光以不同的能量强度同时作用于人眼时,大脑就会感知到不同的色彩。 例如,当红色光以最强的强度发出,而绿色光和蓝色光强度为零时,我们看到的就是纯粹的红色;同理,单独最强强度的绿色光呈现绿色,单独最强强度的蓝色光呈现蓝色。而当三种光强度相等时,就会产生白色光。
RGB的一些具体格式
其中 RGB、RGBA是比较常用的。
RGB24
RGB24 是一种 24 位的像素格式,它使用 8 位来表示红、绿和蓝的颜色分量。也被称作 RGB888。
typedef struct
{
unsigned char r;
unsigned char g;
unsigned char b;
}RGB,RGB24,RGB888;
#define RGB(r,g,b) ((unsigned int)(((unsigned char)(r)|(((unsigned char)(g))<<8))|(((unsigned char)(b))<<16)))注:windows 平台下,一般使用BGR。颜色分量顺序为 BGR。
RGBA32
RGBA32 是一种 32 位的像素格式,它使用 8 位来表示红、绿、蓝和透明度的颜色分量。也被称作 RGB8888。
typedef union
{
unsigned int rgba;
struct
{
unsigned char r;
unsigned char g;
unsigned char b;
unsigned char a;
};
}RGBA,RGBA32,RGBA8888;
#define RGBA(r,g,b,a) ((unsigned int)(((unsigned char)(r)|(((unsigned char)(g))<<8))|(((unsigned char)(b))<<16)|(((unsigned char)(a))<<24)))RGB555
RGB555 是一种 16 位的像素格式,它使用 5 位来表示红、绿和蓝的颜色分量。其中的1位作为透明分量(可以不使用),共 16 位。
typedef struct
{
unsigned short r : 5;
unsigned short g : 5;
unsigned short b : 5;
unsigned short a : 1;
}RGBA555;
//各分量取值:
#define RGB555_MASK_RED 0x7C00
#define RGB555_MASK_GREEN 0x03E0
#define RGB555_MASK_BLUE 0x001F
#define RGB555_MASK_ALPHA 0x8000
R = (wPixel & RGB555_MASK_RED) >> 10; // 取值范围0-31
G = (wPixel & RGB555_MASK_GREEN) >> 5; // 取值范围0-31
B = wPixel & RGB555_MASK_BLUE; // 取值范围0-31
A = (wPixel & RGB555_MASK_ALPHA) >> 15;
#define RGB555(r,g,b,a) (unsigned short)( (r|0x08 << 10) | (g|0x08 << 5) | b|0x08 | (a << 15) )RGB565
RGB565使用16位表示一个像素,这16位中的5位用于R,6位用于G,5位用于B。程序中通常使用一个字(WORD,一个字等于两个字节)来操作一个像素。当读出一个像素后,这个字的各个位意义如下:
typedef struct
{
unsigned short r : 5;
unsigned short g : 6;
unsigned short b : 5;
}RGB565;
//各分量取值:
#define RGB565_MASK_RED 0xF800
#define RGB565_MASK_GREEN 0x07E0
#define RGB565_MASK_BLUE 0x001F
R = (wPixel & RGB565_MASK_RED) >> 11;
G = (wPixel & RGB565_MASK_GREEN) >> 5;
B = wPixel & RGB565_MASK_BLUE;
#define RGB(r,g,b) (unsigned int)( (r|0x08 << 11) | (g|0x08 << 6) | b|0x08 )3.2 HSL/HSV
HSL是一种将RGB色彩模型中的点在圆柱坐标系中的表示法。这两种表示法试图做到比基于笛卡尔坐标系的几何结构RGB更加直观。是运用最广的颜色系统之一
HSL即色相、饱和度、亮度(英语:Hue, Saturation, Lightness)。 色相(H)是色彩的基本属性,就是平常所说的颜色名称,如红色、黄色等。 饱和度(S)是指色彩的纯度,越高色彩越纯,低则逐渐变灰,取0-100%的数值。 明度(V),亮度(L),取0-100%。
HSV即色相、饱和度、明度(英语:Hue, Saturation, Value),又称HSB,其中B即英语:Brightness。 HSL和HSV二者都把颜色描述在圆柱坐标系内的点,这个圆柱的中心轴取值为自底部的黑色到顶部的白色而在它们中间的是灰色,绕这个轴的角度对应于“色相”,到这个轴的距离对应于“饱和度”,而沿着这个轴的高度对应于“亮度”、“色调”或“明度”。 这两种表示在目的上类似,但在方法上有区别。二者在数学上都是圆柱,但HSV(色相、饱和度、明度)在概念上可以被认为是颜色的倒圆锥体(黑点在下顶点,白色在上底面圆心),HSL在概念上表示了一个双圆锥体和圆球体(白色在上顶点,黑色在下顶点,最大横切面的圆心是半程灰色)。注意尽管在HSL和HSV中“色相”指称相同的性质,它们的“饱和度”的定义是明显不同的。 因为HSL和HSV是设备依赖的RGB的简单变换,(h,s,l)或 (h,s,v)三元组定义的颜色依赖于所使用的特定RGB“加法原色”。每个独特的RGB设备都伴随着一个独特的HSL和HSV空间。但是 (h,s,l)或 (h,s,v)三元组在被约束于特定RGB空间比如sRGB的时候就更明确了。
HSL、HSV与RGB的转换
HSL和HSV在数学上定义为在RGB空间中的颜色的R,G和B的坐标的变换。
HSL与RGB的转换
// 定义结构体表示 HSL 颜色
typedef struct {
float h; // 色调,范围 [0, 360]
float s; // 饱和度,范围 [0, 1]
float l; // 亮度,范围 [0, 1]
} HSL;
// 将 RGB 转换为 HSL
HSL rgb_to_hsl(int r, int g, int b) {
// 归一化 RGB 值
float rf = r / 255.0;
float gf = g / 255.0;
float bf = b / 255.0;
// 计算最大值和最小值
float max = fmaxf(fmaxf(rf, gf), bf);
float min = fminf(fminf(rf, gf), bf);
float delta = max - min;
HSL hsl = {0, 0, 0};
// 计算亮度 L
hsl.l = (max + min) / 2.0;
if (delta == 0) {
hsl.h = 0; // 色调不确定,设为 0
hsl.s = 0; // 饱和度为 0
} else {
// 计算饱和度 S
if (hsl.l < 0.5) {
hsl.s = delta / (max + min);
} else {
hsl.s = delta / (2.0 - max - min);
}
// 计算色调 H
if (rf == max) {
hsl.h = (gf - bf) / delta;
} else if (gf == max) {
hsl.h = 2 + (bf - rf) / delta;
} else {
hsl.h = 4 + (rf - gf) / delta;
}
hsl.h *= 60.0; // 转换为度数
if (hsl.h < 0) {
hsl.h += 360.0;
}
}
return hsl;
}
// 将 HSL 转换为 RGB
RGB hsl_to_rgb(HSL hsl) {
RGB rgb = {0, 0, 0};
if (hsl.s == 0) {
// 如果饱和度为 0,则是灰度颜色
rgb.r = rgb.g = rgb.b = (int)(hsl.l * 255);
return rgb;
}
float c = (1 - fabs(2 * hsl.l - 1)) * hsl.s;
float x = c * (1 - fabs(fmod(hsl.h / 60.0, 2) - 1));
float m = hsl.l - c / 2;
float r, g, b;
if (hsl.h >= 0 && hsl.h < 60) {
r = c; g = x; b = 0;
} else if (hsl.h >= 60 && hsl.h < 120) {
r = x; g = c; b = 0;
} else if (hsl.h >= 120 && hsl.h < 180) {
r = 0; g = c; b = x;
} else if (hsl.h >= 180 && hsl.h < 240) {
r = 0; g = x; b = c;
} else if (hsl.h >= 240 && hsl.h < 300) {
r = x; g = 0; b = c;
} else if (hsl.h >= 300 && hsl.h < 360) {
r = c; g = 0; b = x;
}
rgb.r = (int)((r + m) * 255);
rgb.g = (int)((g + m) * 255);
rgb.b = (int)((b + m) * 255);
return rgb;
}代码解释:
- 归一化:将输入的 RGB 值从 [0, 255] 范围归一化到 [0, 1] 范围。
- 计算最大值和最小值:用于后续计算亮度和饱和度。
- 计算亮度 L:根据最大值和最小值的平均值计算。
- 计算饱和度 S:根据最大值和最小值的差值以及亮度 L 计算。
- 计算色调 H:根据最大值对应的 RGB 分量计算,并转换为度数。
HSV与RGB的转换
// 定义结构体表示 RGB 颜色
typedef struct {
int r; // 红色分量,范围 [0, 255]
int g; // 绿色分量,范围 [0, 255]
int b; // 蓝色分量,范围 [0, 255]
} RGB;
// 定义结构体表示 HSV 颜色
typedef struct {
float h; // 色调,范围 [0, 360)
float s; // 饱和度,范围 [0, 1]
float v; // 明度,范围 [0, 1]
} HSV;
// 将 HSV 转换为 RGB
RGB hsv_to_rgb(HSV hsv) {
RGB rgb = {0, 0, 0};
float c = hsv.v * hsv.s;
float x = c * (1 - fabs(fmod(hsv.h / 60.0, 2) - 1));
float m = hsv.v - c;
if (hsv.h >= 0 && hsv.h < 60) {
rgb.r = (int)((c + m) * 255);
rgb.g = (int)((x + m) * 255);
rgb.b = (int)(m * 255);
} else if (hsv.h >= 60 && hsv.h < 120) {
rgb.r = (int)((x + m) * 255);
rgb.g = (int)((c + m) * 255);
rgb.b = (int)(m * 255);
} else if (hsv.h >= 120 && hsv.h < 180) {
rgb.r = (int)(m * 255);
rgb.g = (int)((c + m) * 255);
rgb.b = (int)((x + m) * 255);
} else if (hsv.h >= 180 && hsv.h < 240) {
rgb.r = (int)(m * 255);
rgb.g = (int)((x + m) * 255);
rgb.b = (int)((c + m) * 255);
} else if (hsv.h >= 240 && hsv.h < 300) {
rgb.r = (int)((x + m) * 255);
rgb.g = (int)(m * 255);
rgb.b = (int)((c + m) * 255);
} else if (hsv.h >= 300 && hsv.h < 360) {
rgb.r = (int)((c + m) * 255);
rgb.g = (int)(m * 255);
rgb.b = (int)((x + m) * 255);
}
return rgb;
}
// 将 HSV 转换为 RGB
RGB hsv_to_rgb(HSV hsv) {
RGB rgb = {0, 0, 0};
float c = hsv.v * hsv.s;
float x = c * (1 - fabs(fmod(hsv.h / 60.0, 2) - 1));
float m = hsv.v - c;
if (hsv.h >= 0 && hsv.h < 60) {
rgb.r = (int)((c + m) * 255);
rgb.g = (int)((x + m) * 255);
rgb.b = (int)(m * 255);
} else if (hsv.h >= 60 && hsv.h < 120) {
rgb.r = (int)((x + m) * 255);
rgb.g = (int)((c + m) * 255);
rgb.b = (int)(m * 255);
} else if (hsv.h >= 120 && hsv.h < 180) {
rgb.r = (int)(m * 255);
rgb.g = (int)((c + m) * 255);
rgb.b = (int)((x + m) * 255);
} else if (hsv.h >= 180 && hsv.h < 240) {
rgb.r = (int)(m * 255);
rgb.g = (int)((x + m) * 255);
rgb.b = (int)((c + m) * 255);
} else if (hsv.h >= 240 && hsv.h < 300) {
rgb.r = (int)((x + m) * 255);
rgb.g = (int)(m * 255);
rgb.b = (int)((c + m) * 255);
} else if (hsv.h >= 300 && hsv.h < 360) {
rgb.r = (int)((c + m) * 255);
rgb.g = (int)(m * 255);
rgb.b = (int)((x + m) * 255);
}
return rgb;
}代码解释:
- 定义结构体:RGB 和 HSV 结构体分别用于存储 RGB 和 HSV 颜色值。
- 计算临时变量:
- c:色度,计算公式为 V * S。
- x:辅助变量,计算公式为 c * (1 - |(H / 60) % 2 - 1|)。
- m:偏移量,计算公式为 V - c。
- 根据色调 H 的范围选择相应的 RGB 值:通过条件判断,根据 H 的值选择合适的 RGB 分量。
3.3 YUV
简介
YUV,是一种颜色编码方法。常使用在各个视频处理组件中。 YUV在对照片或视频编码时,考虑到人类的感知能力,允许降低色度的带宽。 YUV是编译true-color颜色空间(color space)的种类,Y’UV, YUV, YCbCr,YPbPr等专有名词都可以称为YUV,彼此有重叠。“Y”表示明亮度(Luminance或Luma),也就是灰阶值,“U”和“V”表示的则是色度(Chrominance或Chroma),作用是描述影像色彩及饱和度,用于指定像素的颜色。
Y’代表明亮度(luma;brightness)而U与V存储色度(色讯;chrominance;color)部分;亮度(luminance)记作Y,而Y’的prime符号记作伽玛校正。 YUVFormats分成两个格式: 紧缩格式(packedformats):将Y、U、V值存储成MacroPixels数组,和RGB的存放方式类似。 平面格式(planarformats):将Y、U、V的三个分量分别存放在不同的矩阵中。 紧缩格式(packedformat)中的YUV是混合在一起的,对于YUV常见格式有AYUV格式(4:4:4采样、打包格式);YUY2、UYVY(采样、打包格式),有UYVY、YUYV等。平面格式(planarformats)是指每Y分量,U分量和V分量都是以独立的平面组织的,也就是说所有的U分量必须在Y分量后面,而V分量在所有的U分量后面,此一格式适用于采样(subsample)。平面格式(planarformat)有I420(4:2:0)、YV12、IYUV等。
常用的YUV格式
为节省带宽起见,大多数YUV格式平均使用的每像素位数都少于24位。主要的抽样(subsample)格式有YCbCr4:2:0、YCbCr4:2:2、YCbCr4:1:1和YCbCr4:4:4。YUV的表示法称为A:B:C表示法:
- 4:4:4表示完全取样。
- 4:2:2表示2:1的水平取样,垂直完全采样。
- 4:2:0表示2:1的水平取样,垂直2:1采样。
- 4:1:1表示4:1的水平取样,垂直完全采样。
最常用Y:UV记录的比重通常1:1或2:1,DVD-Video是以YUV4:2:0的方式记录,也就是我们俗称的I420,YUV4:2:0并不是说只有U(即Cb),V(即Cr)一定为0,而是指U:V互相援引,时见时隐,也就是说对于每一个行,只有一个U或者V分量,如果一行是4:2:0的话,下一行就是4:0:2,再下一行是4:2:0…以此类推。
至于其他常见的YUV格式有YUY2、YUYV、YVYU、UYVY、AYUV、Y41P、Y411、Y211、IF09、IYUV、YV12、YVU9、YUV411、YUV420等。
YUY2及常见表示方法
YUY2(和YUYV)格式为像素保留Y,而UV在水平空间上相隔二个像素采样一次(Y0U0Y1V0),(Y2U2Y3V2)…其中,(Y0U0Y1V0)就是一个macro-pixel(宏像素),它表示了2个像素,(Y2U2Y3V2)是另外的2个像素。以此类推,再如:Y41P(和Y411)格式为每个像素保留Y分量,而UV分量在水平方向上每4个像素采样一次。一个宏像素为12个字节,实际表示8个像素。
图像数据中YUV分量排列顺序如下:(U0Y0V0Y1U4Y2V4Y3Y4Y5Y6Y7)
YVYUUYVY
YVYU,UYVY格式跟YUY2类似,只是排列顺序有所不同。Y211格式是Y每2个像素采样一次,而UV每4个像素采样一次。AYUV格式则有一Alpha通道。
YV12
YV12格式与IYUV类似,每个像素都提取Y,在UV提取时,将图像2x2的矩阵,每个矩阵提取一个U和一个V。YV12格式和I420格式的不同处在V平面和U平面的位置不同。在YV12格式中,V平面紧跟在Y平面之后,然后才是U平面(即:YVU);但I420则是相反(即:YUV)。NV12与YV12类似,效果一样,YV12中U和V是连续排列的,而在NV12中,U和V就交错排列的。
3.4 XYZ
XYZ模型
CIE 1931 XYZ色彩空间(也叫做CIE 1931色彩空间)是其中一个最先采用数学方式来定义的色彩空间,它由国际照明委员会(CIE)于1931年创立。
XYZ 色彩空间作用
XYZ 色彩空间是为了解决更精确地定义色彩而提出来的, XYZ 三个分量中, XY代表的是色度, 其中Y分量既可以代表亮度也可以代表色度, 三个分量的单位都是 cd/m2 , (或者叫做nit)。我们无法用RGB来精确定义颜色, 因为,不同的设备显示的RGB都是不一样的,不同的设备, 显示同一个RGB, 在人眼看出来是千差万别的, 如果我们用XYZ定义一个设备的色彩空间, 这样就精确多了!
转换公式
XYZ 转 RGB
R = 3.2406 * X + -1.5372 * Y + -0.4986 * Z
G = -0.9689 * X + 1.8758 * Y + 0.0415 * Z
B = 0.0557 * X + -0.2040 * Y + 1.0570 * ZRGB 转 XYZ
X = 0.4124 * R + 0.3576 * G + 0.1805 * B
Y = 0.2126 * R + 0.7152 * G + 0.0722 * B
Z = 0.0193 * R + 0.1192 * G + 0.9505 * B3.5 LAB
Lab色彩模型是由照度(L)和有关色彩的a, b三个要素组成。L表示照度(Luminosity),相当于亮度,a表示从红色至绿色的范围,b表示从蓝色至黄色的范围。L的值域由0到100,L=50时,就相当于50%的黑;a和b的值域都是由+120至-120,其中+120 a就是红色,渐渐过渡到-120 a的时候就变成绿色;同样原理,+120 b是黄色,-120 b是蓝色。所有的颜色就以这三个值交互变化所组成。
详情请在网络上搜索。
3.6 CMYK
CMYK代表印刷上用的四种颜色,C代表青色(Cyan),M代表洋红色或者品红(Magenta),Y代表黄色(Yellow),K代表黑色(Black)。因为在实际应用中,青色、洋红色和黄色很难叠加形成真正的黑色,最多不过是褐色而已。因此才引入了K——黑色。黑色的作用是强化暗调,加深暗部色彩。
详情请在网络上搜索。
第4章
压缩格式
1 序
2 目录
第5章
图片格式
1 序
2 目录
第6章
视频格式
1 序
2 目录
视频格式 的子部分
6.1 MP4文件格式重点全解析
本文由 简悦 SimpRead 转码, 原文地址 zhuanlan.zhihu.com
MP4 文件格式又被称为 MPEG-4 Part 14,出自 MPEG-4 标准第 14 部分 。它是一种多媒体格式容器,广泛用于包装视频和音频数据流、海报、字幕和元数据等。(顺便一提,目前流行的视频编码格式 AVC/H264 定义在 MPEG-4 Part 10)。MP4 文件格式基于 Apple 公司的 QuickTime 格式,因此,Introduction to QuickTime File Format Specification 也可以作为我们研究 MP4 的重要参考。
作者:张武星
审核:泰一
01. Overview
MP4 文件由 box 组成,每个 box 分为 Header 和 Data。其中 Header 部分包含了 box 的类型和大小,Data 包含了子 box 或者数据,box 可以嵌套子 box。
下图是一个典型 MP4 文件的基本结构:

图中看到 MP4 文件有几个主要组成部分:
fytp
File Type Box,一般在文件的开始位置,描述的文件的版本、兼容协议等。
moov
Movie Box,包含本文件中所有媒体数据的宏观描述信息以及每路媒体轨道的具体信息。一般位于 ftyp 之后,也有的视频放在文件末尾。注意,当改变 moov 位置时,内部一些值需要重新计算。
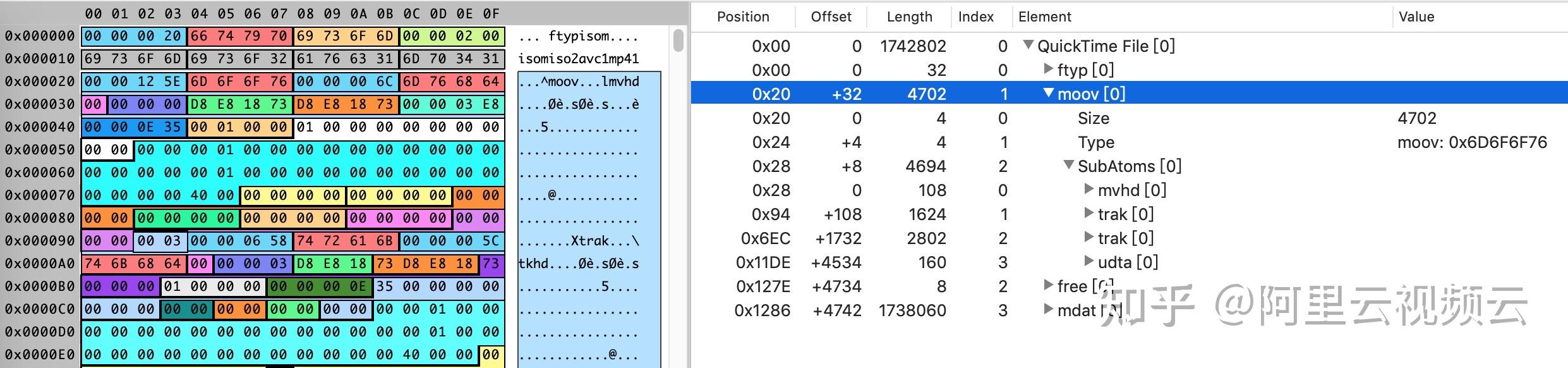
mdat
Media Data Box,存放具体的媒体数据。
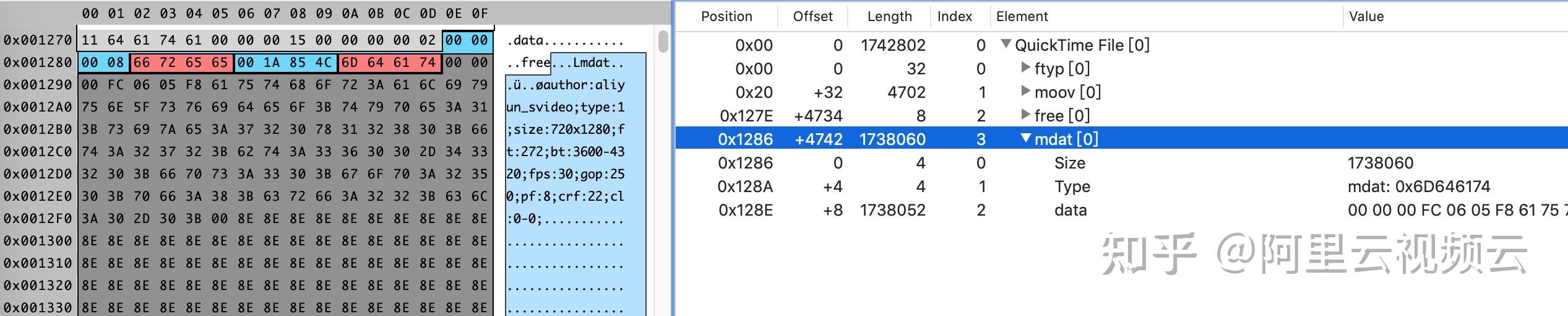
02. Moov Insider
MP4 的媒体数据信息主要存放在 Moov Box 中,是我们需要分析的重点。moov 的主要组成部分如下:
mvhd
Movie Header Box,记录整个媒体文件的描述信息,如创建时间、修改时间、时间度量标尺、可播放时长等。
下图示例中,可以获取文件信息如时长为 3.637 秒。
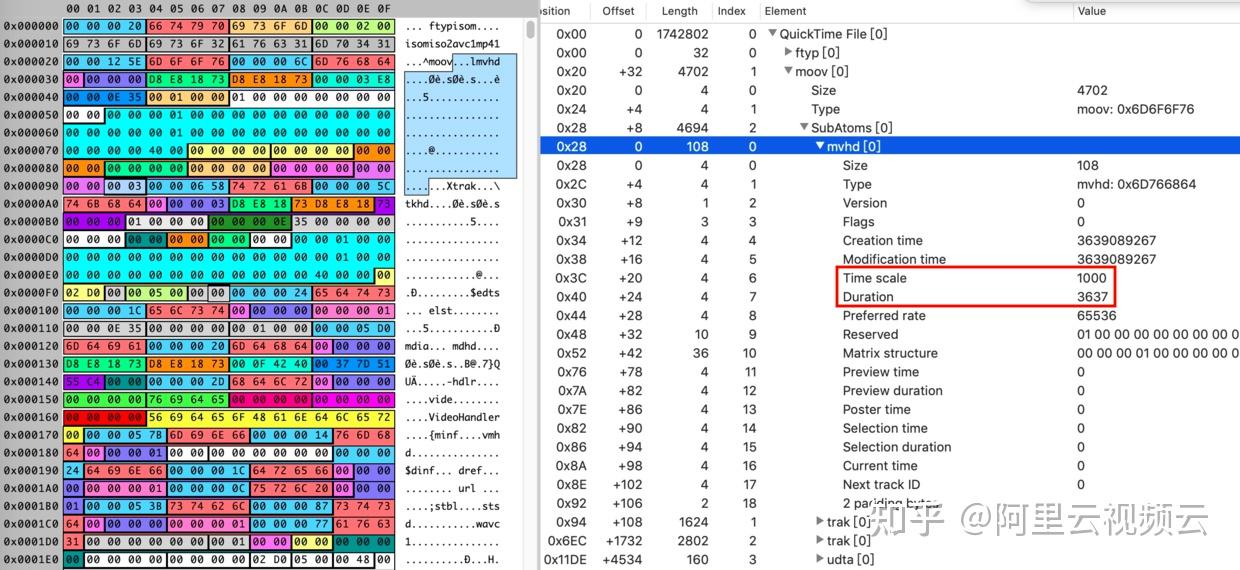
udta
User Data Box,自定义数据。
track
Track Box,记录媒体流信息,文件中可以存在一个或多个 track,它们之间是相互独立的。每个 track 包含以下几个组成部分:
1. tkhd
Track Header Box,包含关于媒体流的头信息。
下图示例中,可以看到流信息如视频流宽度 720,长度 1280。
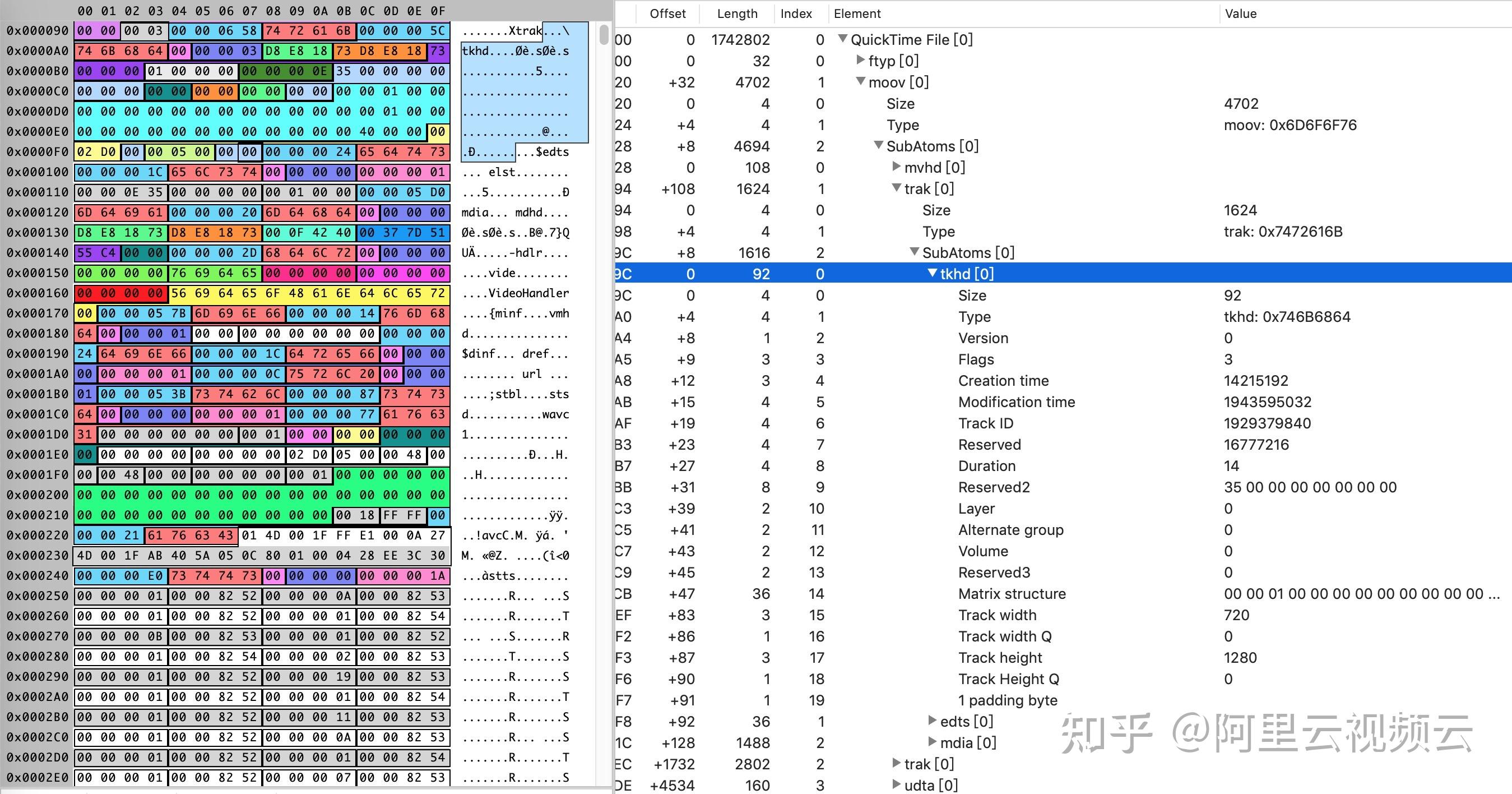
2. mdia
Media Box,这是一个包含 track 媒体数据信息的 container box。子 box 包括:
- mdhd:Media Header Box,存放视频流创建时间,长度等信息。
- hdlr:Handler Reference Box,媒体的播放过程信息。
- minf:Media Information Box,解释 track 媒体数据的 handler-specific 信息。minf 同样是个 container box,其内部需要关注的内容是 stbl,这也是 moov 中最复杂的部分。
stbl 包含了媒体流每一个 sample 在文件中的 offset,pts,duration 等信息。想要播放一个 MP4 文件,必须根据 stbl 正确找到每个 sample 并送给解码器。mdia 展开如下图所示:
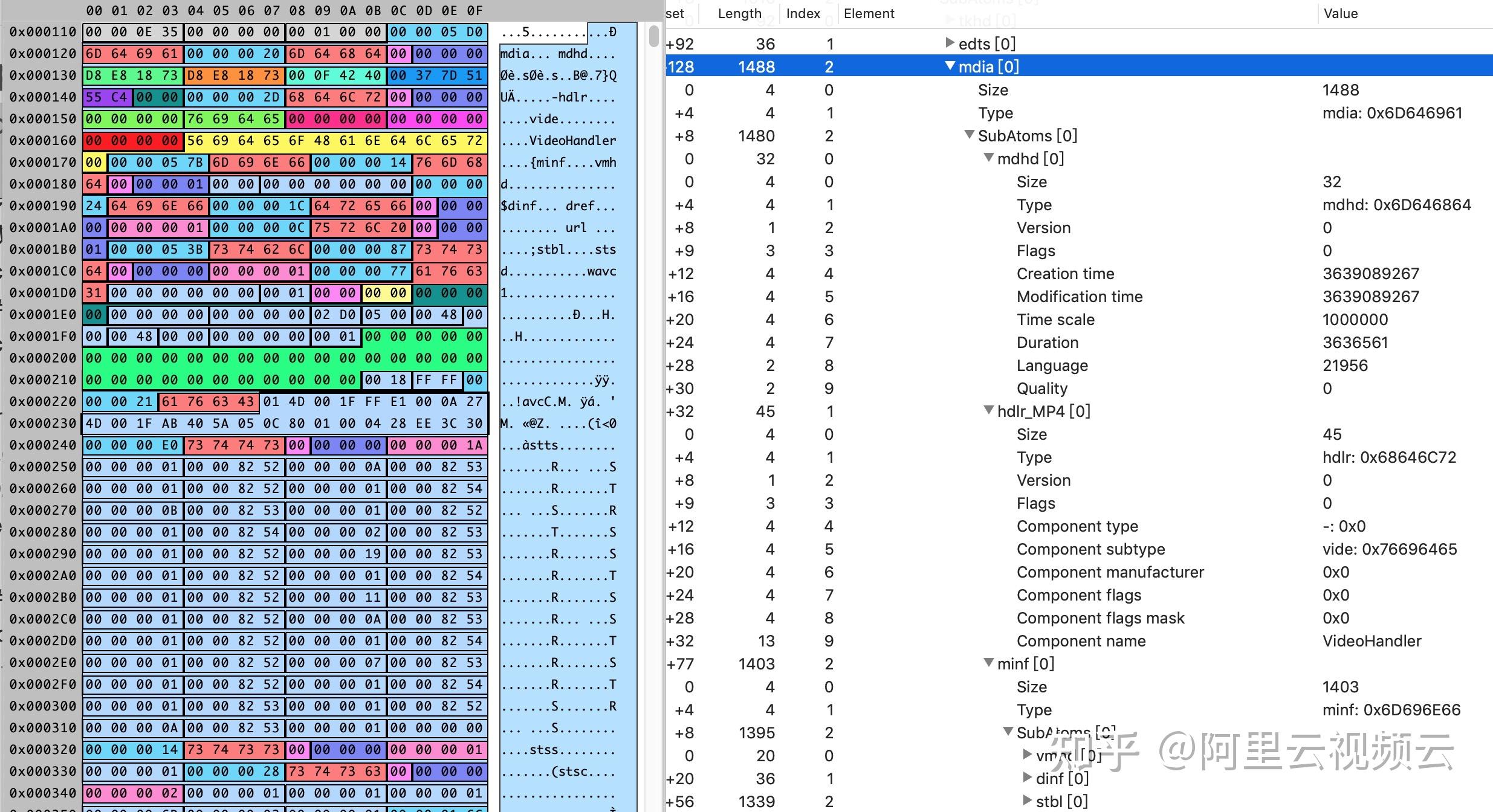
03. Stbl Insider
Sample Table Box,上文提到 mdia 中最主要的部分是存放文件中每个 Sample 信息的 stbl。在解析 stbl 前,我们需要区分 Chunk 和 Sample 这两个概念。在 MP4 文件中,Sample 是一个媒体流的基本单元,例如视频流的一个 Sample 代表实际的 nal 数据。Chunk 是数据存储的基本单位,它是一系列 Sample 数据的集合,一个 Chunk 中可以包含一个或多的 Sample。
stbl 用来描述每个 Sample 的信息,包含以下几个主要的子 box:
stsd
Sample Description Box,存放解码必须的描述信息。
下图示例中,对于 h264 的视频流,其具体类型为 avc1,extensions 中存放有 sps,pps 等解码必要信息。
stts
Time-to-Sample Box,定义每个 Sample 时长。Time To Sample 的 table entry 布局如下:

- Sample count:sample 个数
- Sample duration:sample 持续时间
持续时间相同的连续的 Sample 可以放到一个 entry 里面,以达到节省空间的目的。
下图示例中,第 1 个 Sample 时间为 33362 微秒,第 2-11 个 Sample 时间为 33363 微秒:
stss
Sync Sample Box,同步 Sample 表,存放关键帧列表,关键帧是为了支持随机访问。stss 的 table entry 布局如下:

下图示例中,该视频 track 只有一个关键帧即第 1 帧:
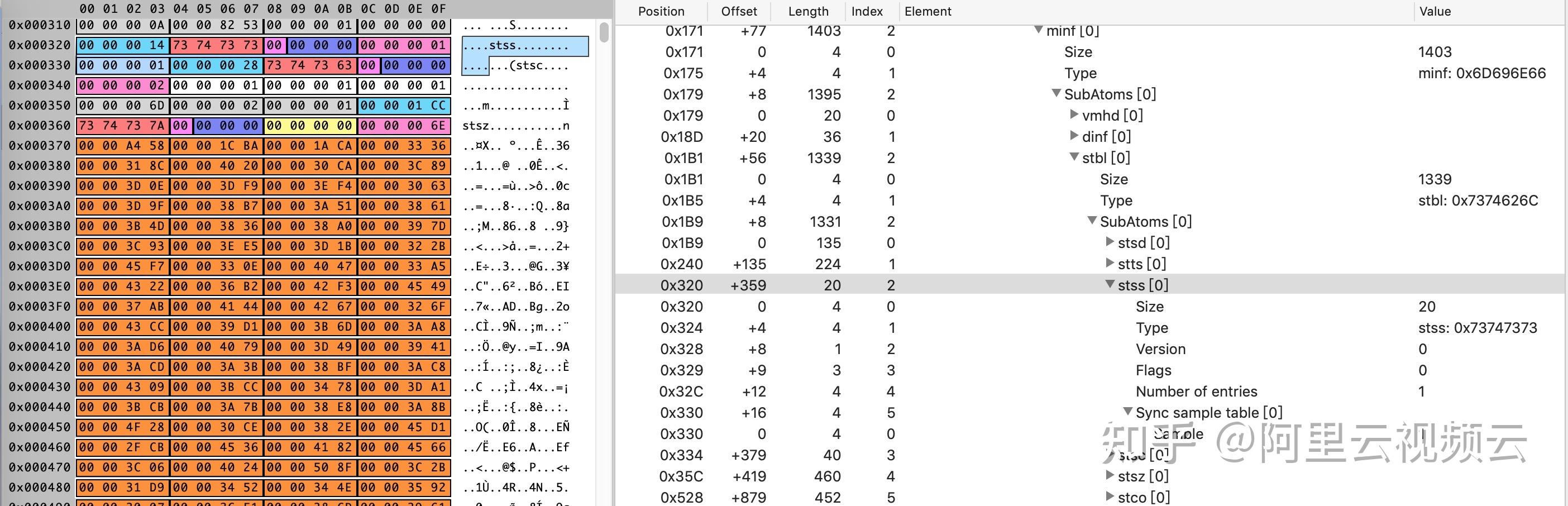
stsc
Sample-To-Chunk Box,Sample-Chunk 映射表。上文提到 MP4 通常把 Sample 封装到 Chunk 中,一个 Chunk 可能会包含一个或者几个 Sample。Sample-To-Chunk Atom 的 table entry 布局如下图所示:

- First chunk:使用该表项的第一个 chunk 序号。
- Samples per chunk:使用该表项的 chunk 中包含有几个 sample。
- Sample description ID:使用该表项的 chunk 参考的 stsd 表项序号。
下图示例中,可以看到该视频 track 一共有两个 stsc 表项,Chunk 序列 1-108,每个 Chunk 包含一个 sample,Chunk 序列 109 开始,每个 Chunk 包含两个 Sample。
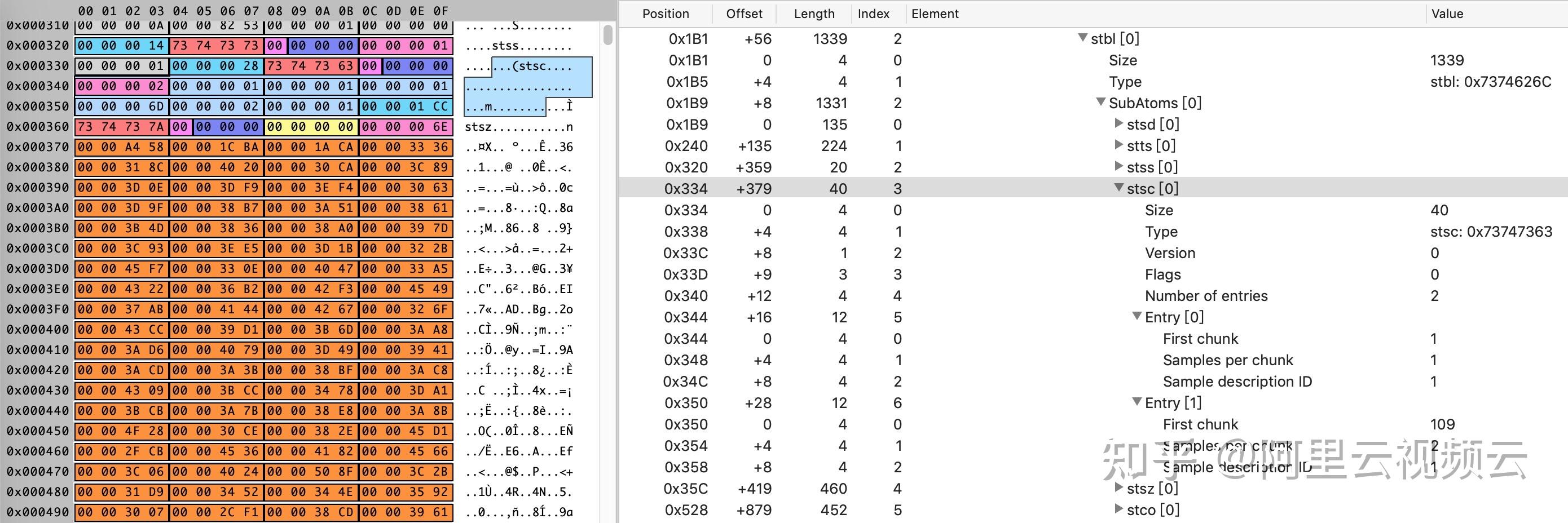
stsz
Sample Size Box,指定了每个 Sample 的 size。Sample Size Atom 包含两 Sample 总数和一张包含了每个 Sample Size 的表。Sample Size 表的 entry 布局如下图:
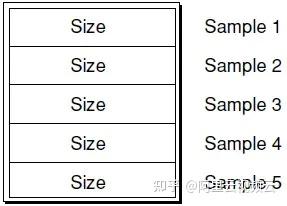
下图示例中,该视频流一共有 110 个 Sample,第 1 个 Sample 大小为 42072 字节,第 2 个 Sample 大小为 7354 个字节。
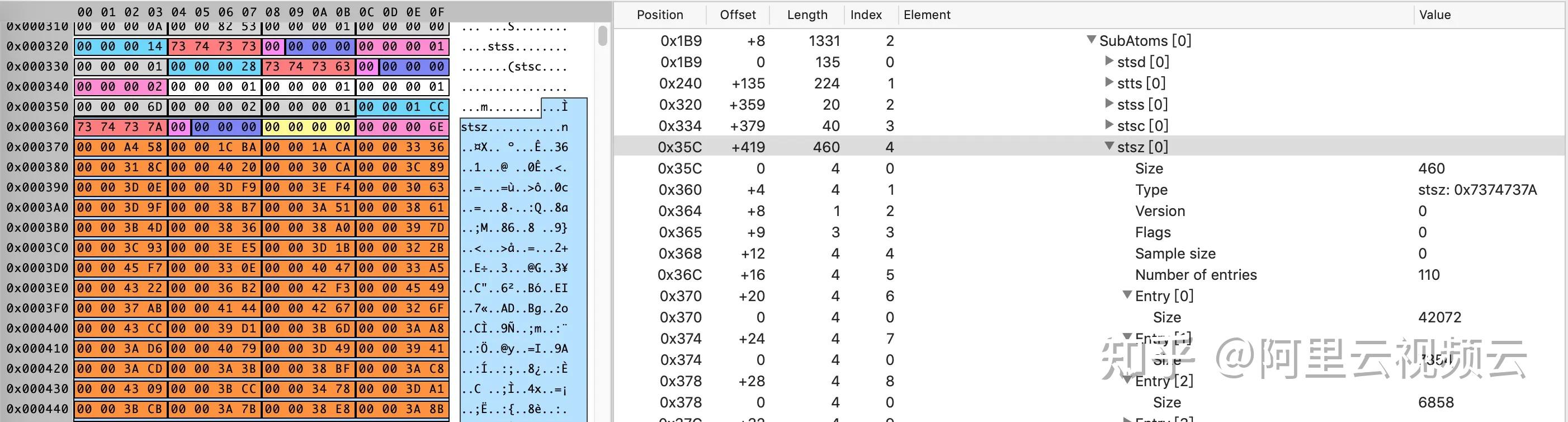
stco
Chunk Offset Box,指定了每个 Chunk 在文件中的位置,这个表是确定每个 Sample 在文件中位置的关键。该表包含了 Chunk 个数和一个包含每个 Chunk 在文件中偏移位置的表。每个表项的内存布局如下:

需要注意,这里 stco 只是指定的每个 Chunk 在文件中的偏移位置,并没有给出每个 Sample 在文件中的偏移。想要获得每个 Sample 的偏移位置,需要结合 Sample Size box 和 Sample-To-Chunk 计算后取得。
下图示例中,该视频流第 1 个 Chunk 在文件中的偏移为 4750,第 1 个 Chunk 在文件中的偏移为 47007。
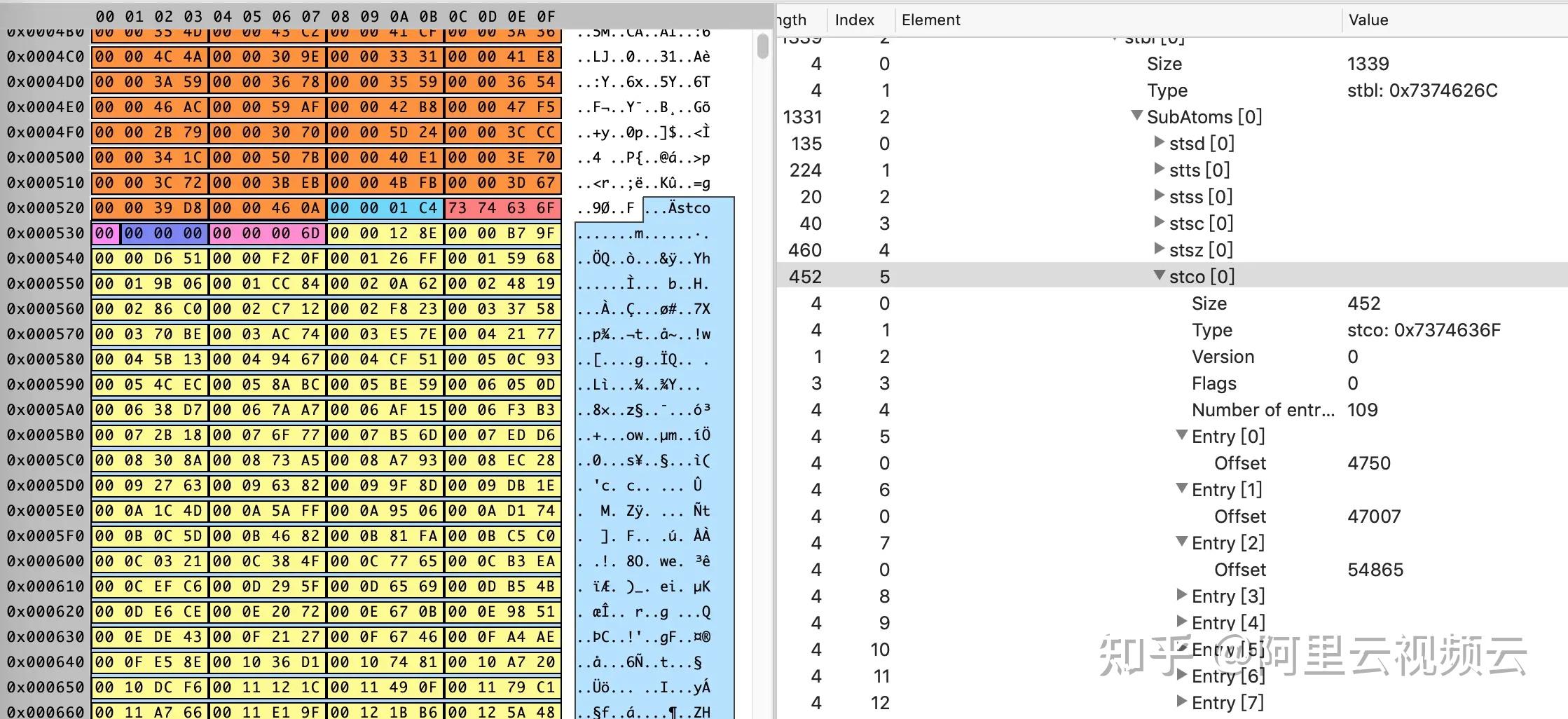
04. 如何计算 Sample 偏移位置
上文提到通过 stco 并不能直接获取某个 Sample 的偏移位置,下面举例说明如何获取某一个 pts 对应的 Sample 在文件中的位置。大体需要以下步骤:
将 pts 转换到媒体对应的时间坐标系。
根据 stts 计算某个 pts 对应的 Sample 序号。
根据 stsc 计算 Sample 序号存放在哪个 Chunk 中。
根据 stco 获取对应 Chunk 在文件中的偏移位置。
根据 stsz 获取 Sample 在 Chunk 内的偏移位置并加上第 4 步获取的偏移,计算出 Sample 在文件中的偏移。
例如,想要获取 3.64 秒视频 Sample 数据在文件中的位置:
根据 time scale 参数,将 3.64 秒转换为视频时间轴对应的 3640000。
遍历累加下表所示 stts 所有项目,计算得到 3640000 位于第 110 个 Sample。
type stts
size 224
flags 0
version 0
sample_counts 1,10,1,1,11,1,1,2,1,25,1,1,1,17,1,10,1,1,1,7,1,1,1,1,10,1
sample_deltas 33362,33363,33362,33364,33363,33362,33364,33363,33362,33363,33362,33364,33362,33363,33362,33363,33362,33364,33362,33363,33362,33364,33363,33362,33363,0- 查询下表所示 stsc 所有项目,计算得到第 110 个 Sample 位于第 109 个 Chunk,并且在该 Chunk 中位于第 2 个 Sample。
type stsc
size 40
flags 0
version 0
first_chunk 1,109
samples_per_chunk 1,2
sample_description_index 1,1- 查询下表所示 stco 所有项目,得到第 109 个 Chunk 在文件中偏移位置为 1710064。
Property name Property value
type stco
size 452
flags 0
version 0
chunk_offsets 4750,47007,54865,61967,75519,88424,105222,117892,133730,149529,165568,182034,194595,210776,225470,240756,255358,270711,285459,300135,315217,330899,347372,363196,376409,394509,407767,424615,438037,455603,469784,487287,505197,519638,536714,553893,567187,584744,599907,615298,630669,645918,662605,678655,693510,708980,724061,738946,754170,771520,787233,800847,816997,832490,847814,862559,877929,898379,911054,925810,943883,956497,974403,991527,1009478,1025198,1041806,1062609,1078401,1091360,1105142,1118748,1132815,1145281,1156966,1171871,1186742,1202760,1218235,1236688,1249330,1263163,1280880,1297903,1313162,1332885,1345726,1359017,1376283,1391401,1405512,1419550,1433644,1452103,1475241,1492689,1511291,1522606,1535368,1559413,1575331,1588853,1609829,1626623,1642798,1658640,1674160,1693972,1710064- 查询下表所示 stsz 所有项目,得到第 109 个 Sample 的 size 为 14808。计算得到 3.64 秒视频 Sample 数据在文件中:
offset:1710064 + 14808 = 1724872
size:17930
type stsz
size 460
flags 0
version 0
sample_sizes 42072,7354,6858,13110,12684,16416,12490,15497,15630,15865,16116,12387,15775,14519,14929,14433,15181,14390,14496,14717,15507,16101,15643,12843,17911,13070,16455,13221,17186,14002,17139,17737,14251,16708,16999,12911,17356,14801,15213,15016,15062,16505,15689,14657,15053,14907,14527,15048,17161,15308,13432,15777,15307,14971,14568,14987,20264,12494,14382,17873,12235,17718,16770,17766,15366,16420,20623,15403,12761,13394,13390,13714,12295,11505,14541,14689,15635,15291,18091,12458,13645,17346,16847,14902,19530,12446,13105,16872,14937,13944,13657,13908,18092,22959,17080,18421,11129,12400,23844,15564,13340,20603,16609,15984,15474,15339,19451,15719,14808,17930
sample_size 0
sample_count 110- 验证:用编辑器打开 MP4 文件,定位到文件偏移 offset = 1724872 的位置,前 4 字节值为 0x00004606。在 avcc 中一个 Sample 的前 4 个字节代表这个包的大小,转换为十进制是 17926,该值正好等于 size = 17930 减去表示长度的四个字节。
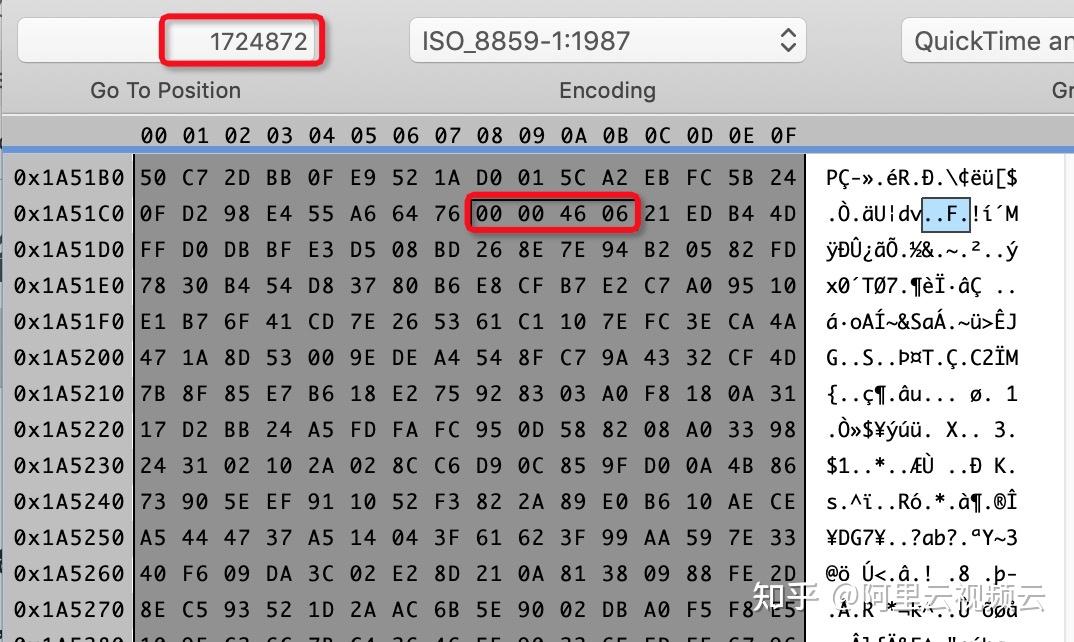
参考资料
QuickTime File Format Specification
「视频云技术」公众号,每周阿里云一线专家分享,音视频领域最佳技术干货,欢迎关注。
6.2 视频封装格式:MP4_格式详解
本文由 简悦 SimpRead 转码, 原文地址 zhuanlan.zhihu.com
1.MP4 格式概述
1.1 简介
MP4 或称 MPEG-4 第 14 部分(MPEG-4 Part 14)是一种标准的数字多媒体容器格式。扩展名为. mp4。虽然被官方标准定义的唯一扩展名是. mp4,但第三方通常会使用各种扩展名来指示文件的内容:
- 同时拥有音频视频的 MPEG-4 文件通常使用标准扩展名. mp4;
- 仅有音频的 MPEG-4 文件会使用. m4a 扩展名。
大部分数据可以通过专用数据流嵌入到 MP4 文件中,因此 MP4 文件中包含了一个单独的用于存储流信息的轨道。目前得到广泛支持的编解码器或数据流格式有:
- 视频格式:H.264/AVC、H.265/HEVC、VP8/9 等
- 音频格式:AAC、MP3、Opus 等
1.2 术语
为了后面能比较规范的了解这种文件格式,这里需要了解下面几个概念和术语,这些概念和术语是理解好 MP4 媒体封装格式和其操作算法的关键。
(1)Box
这个概念起源于 QuickTime 中的 atom,也就是说 MP4 文件就是由一个个 Box 组成的,可以将其理解为一个数据块,它由 Header+Data 组成,Data 可以存储媒体元数据和实际的音视频码流数据。Box 里面可以直接存储数据块但是也可以包含其它类型的 Box,我们把这种 Box 又称为 container box。
(2)Sample
简单理解为采样,对于视频可以理解为一帧数据,音频一帧数据就是一段固定时间的音频数据,可以由多个 Sample 数据组成,简而言之:存储媒体数据的单位是 sample。
(3)Track
表示一些 sample 的集合,对于媒体数据而言就是一个视频序列或者音频序列,我们常说的音频轨和视频轨可以对照到这个概念上。当然除了 Video Track 和 Audio Track 还可以有非媒体数据,比如 Hint Track,这种类型的 Track 就不包含媒体数据,可以包含一些将其他数据打包成媒体数据的指示信息或者字幕信息。简单来说:Track 就是电影中可以独立操作的媒体单位。
(4)Chunk
一个 track 的连续几个 sample 组成的单元被称为 chunk,每个 chunk 在文件中有一个偏移量,整个偏移量从文件头算起,在这个 chunk 内,sample 是连续存储的。
这样就可以理解为 MP4 文件里面有多个 Track, 一个 Track 又是由多个 Chunk 组成,每个 Chunk 里面包含着一组连续的 Sample,正是因为定义了上述几个概念,MP4 这种封装格式才容易实现灵活、高效、开放的特性,所以要仔细理解。
2.MP4 整体结构
2.1 MP4 结构概览
MP4 格式是一个 box 的格式,box 容器套 box 子容器,box 子容器再套 box 子容器。
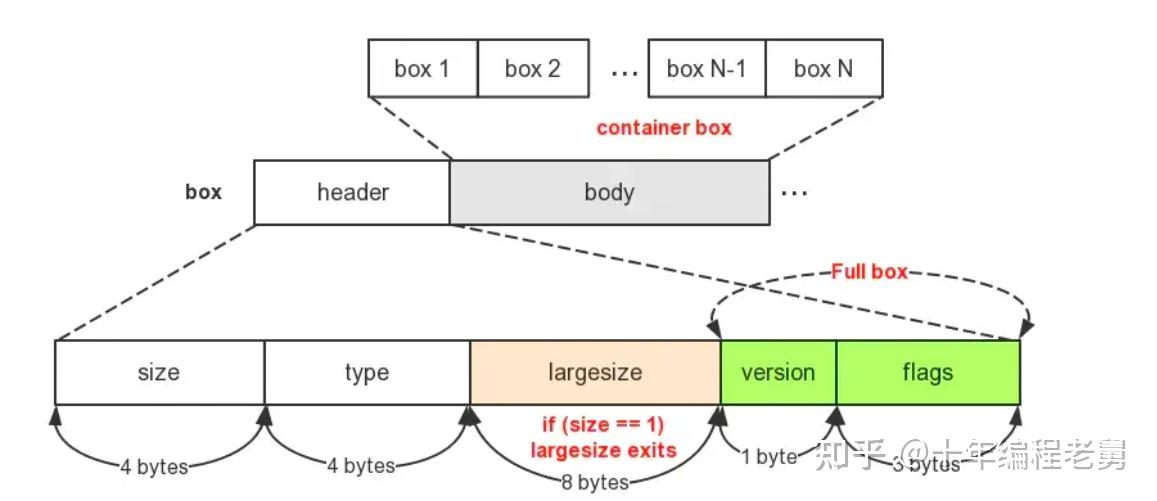
一个 box 由两部分组成:box header、box body。
- box header:box 的元数据,比如 box type、box size。
- box body:box 的数据部分,实际存储的内容跟 box 类型有关,比如 mdat 中 body 部分存储的媒体数据。
box header 中,只有 type、size 是必选字段。当 size==1 时,存在 largesize 字段。如果 size==0,表示该 box 为文件的最后一个 box。在部分 box 中,还存在 version、flags 字段,这样的 box 叫做 Full Box。当 box body 中嵌套其他 box 时,这样的 box 叫做 container box。
mp4box 图示如下:
完整的 Box 结构:
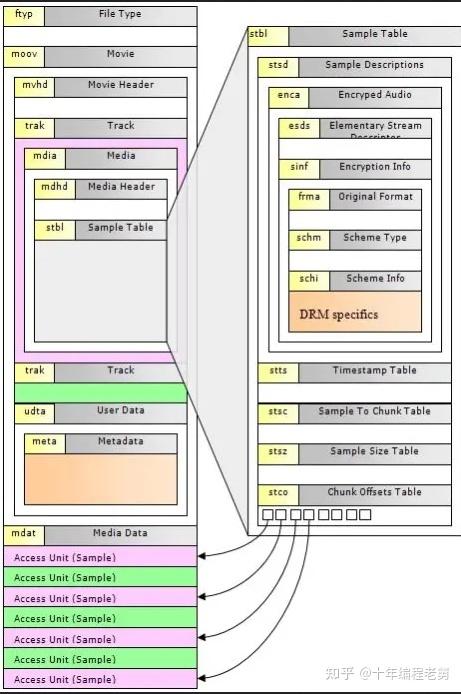
每个 Box 承载的数据内容如下:
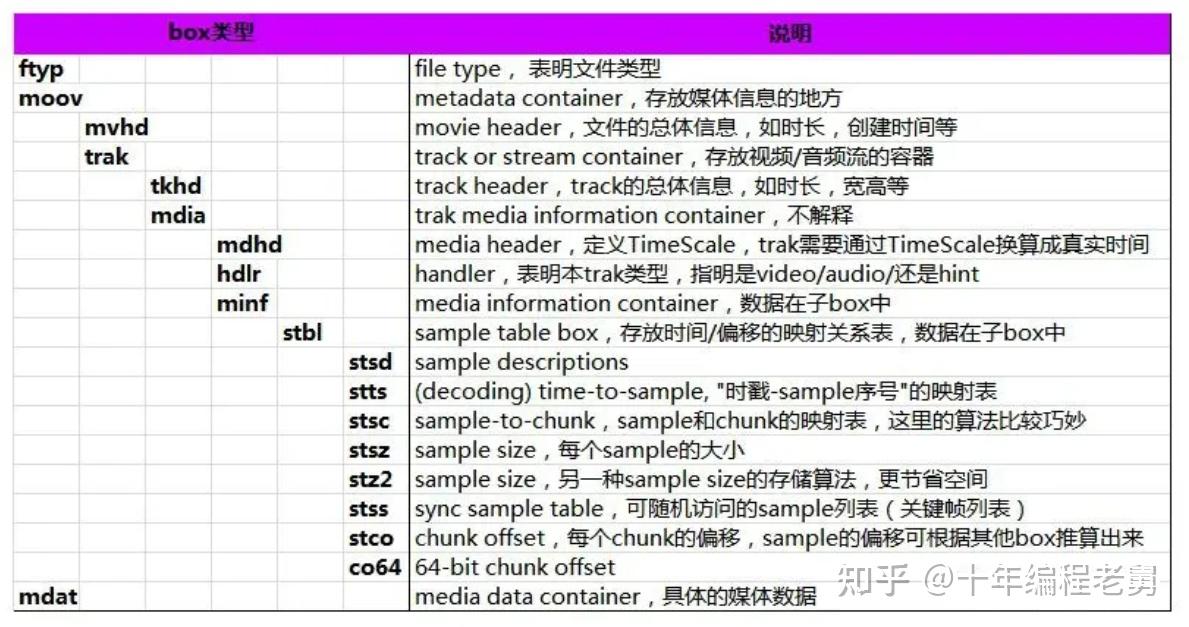
2.2 Box 结构
mp4 封装格式采用称为 box 的结构来组织数据。结构如下:
+-+-+-+-+-+-+-+-+-+-+
| header | body |
+-+-+-+-+-+-+-+-+-+-+其它所有 box 都在语法上继承自此基本 box 结构。
2.2.1 box header
box 分为普通 box 和 fullbox。
(1)普通 box header 结构如下:
| 字段 | 类型 | 描述 |
| size | 4 Bytes | 包含 box header 的整个 box 的大小 |
| type | 4 Bytes | 4 个 ascii 值,如果是 "uuid",则表示此 box 为用户自定义,可忽略 |
| large size | 8 Bytes | size=1 时才有的字段,用于扩展,例如 mdat box 会需要此字段 |
(2)fullbox 在上面的基础上新增了 2 个字段:
| 字段 | 类型 | 描述 |
| version | 1 Bytes | 版本号 |
| flags | 3 Bytes | 标识 |
2.2.2 box body
一个 box 可能会包含其它多个 box,此种 box 称为 container box。因此 box body 可能是一种具体 box 类型,也有可能是其它 box。
虽然 Box 的类型非常多,大概有 70 多种,但是并不是都是必须的,一般的 MP4 文件都是含有必须的 Box 和个别非必须 Box,我用 MP4info 这种工具分析了一首 MP4 的文件,具体的 Box 显示如下:
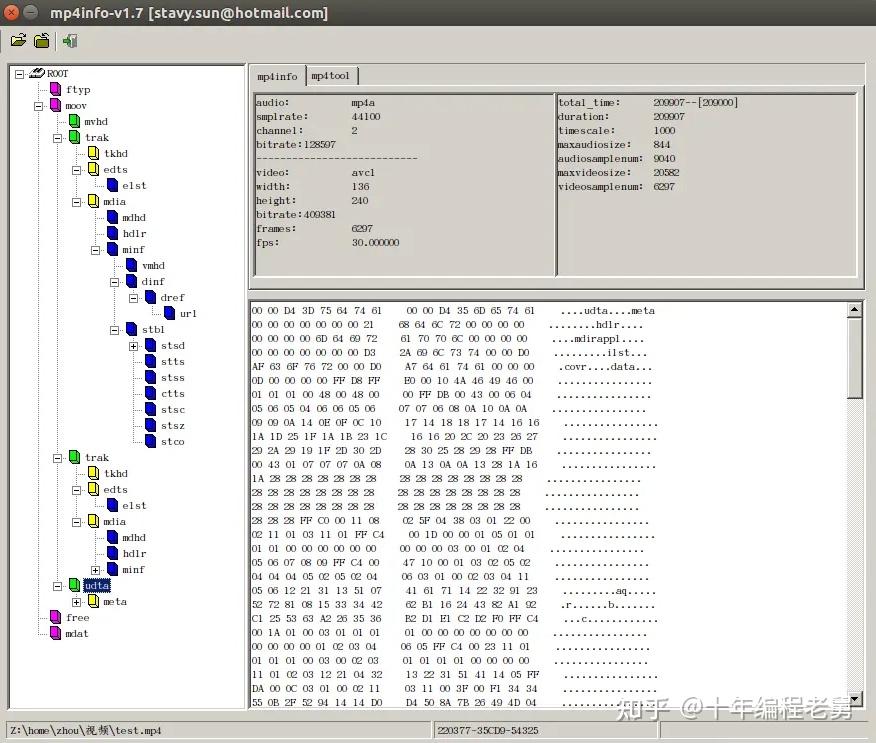
通过上述工具分析出来的结果,我们大概可以总结出 MP4 以下几个特点:
- MP4 文件就是由一个个 Box 组成,其中 Box 还可以相互嵌套,排列紧凑没有多的冗余数据;
- Box 类型并没有很多,主要是由必须的 ftyp、moov、mdat 组成,还有 free,udta 非必须 box 组成即去掉这两种 box 对于播放音视频也没有啥影响。
- Moov 一般存储媒体元数据,比较复杂嵌套层次比较深,后面会详细解释各个 box 的字段含义和组成。
2.3 ftyp(File Type Box)
ftyp 一般出现在文件的开头,用来指示该 mp4 文件使用的标准规范:
| 字段 | 类型 | 描述 |
| major_brand | 4 bytes | 主版本 |
| minor_version | 4 bytes | 次版本 |
| compatible_brands[] | 4 bytes | 指定兼容的版本,注意此字段是一个 list,即可以包含多个 4 bytes 版本号 |
一个示例如下:

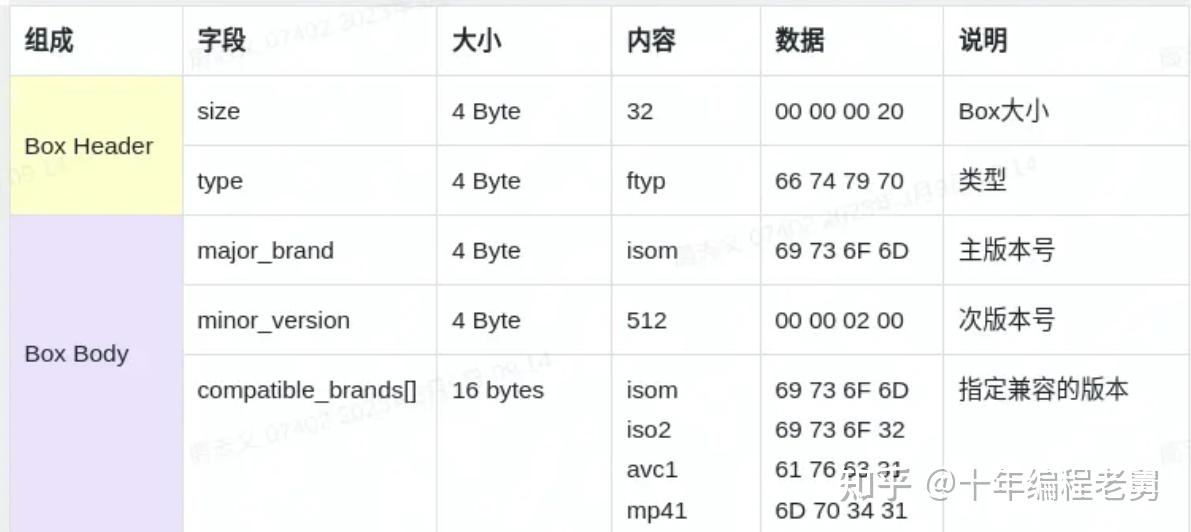
2.4 moov(Movie Box)
- moov 是一个 container box,一个文件只有一个,其包含的所有 box 用于描述媒体信息(metadata)。
- moov 的位置可以紧随着 ftyp 出现,也可以出现在文件末尾。
- 由于是一个 container box,所以除了 box header,其 box body 就是其它的 box。
子 Box:
- mvhd(moov header):用于简单描述一些所有媒体共享的信息。
- trak:即 track,轨道,用于描述音频流或视频流信息,可以有多个轨道,如上出现了 2 次,分别表示一路音频和一路视频流。
- udta(user data):用户自定义,可忽略。
一个示例如下:
(1)结构
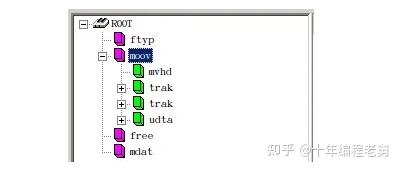
(2)数据
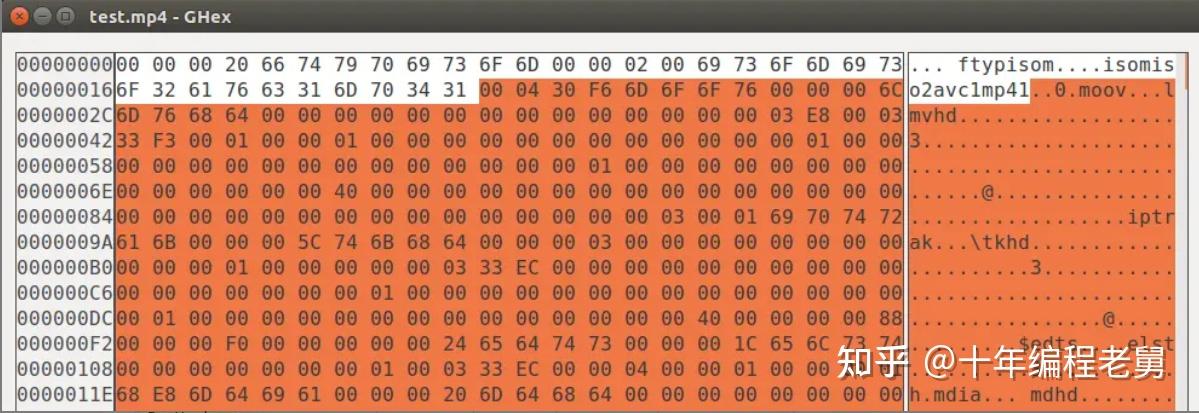
(3)成分
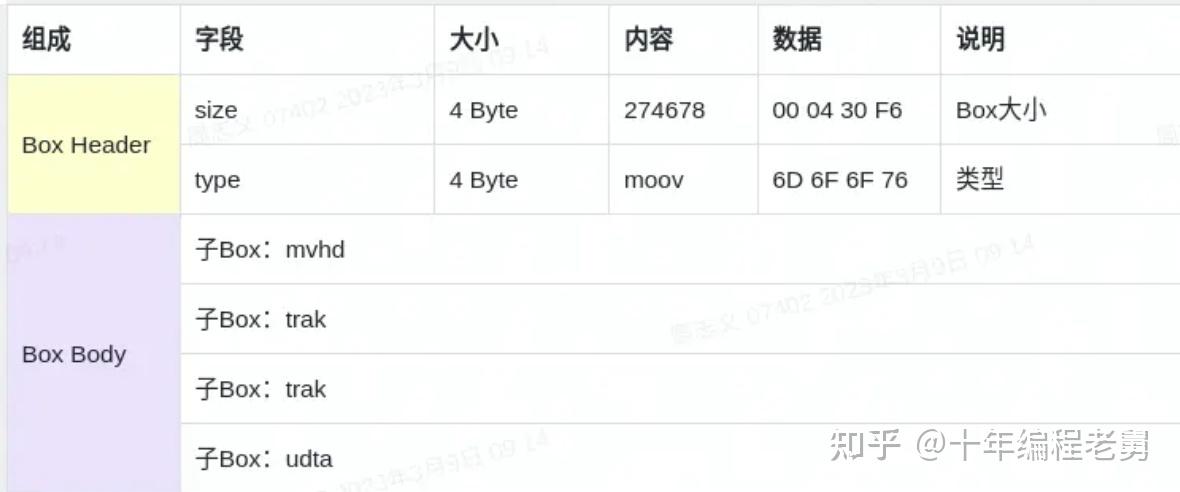
子 Box:mvhd
用于简单描述一些所有媒体共享的信息。

子 Box:trak
track,轨道,用于描述音频流或视频流信息,可以有多个轨道,如上出现了 2 次,分别表示一路音频和一路视频流。

2.5 mvhd(Movie Header Box)
mvhd 作为媒体信息的 header 出现 (注意此 header 不是 box header,而是 moov 媒体信息的 header),用于描述一些所有媒体共享的基本信息。
mvhd 语法继承自 fullbox,注意下述示例出现的 version 和 flags 字段属于 fullbox header。
Box Body:

2.6 trak(track)
- trak box 是一个 container box,其子 box 包含了该 track 的媒体信息。
- 一个 mp4 文件可以包含多个 track,track 之间是独立的,trak box 用于描述每一路媒体流。
- 一般情况下有两个 trak,分别对应音频流和视频流。
一个示例如下:
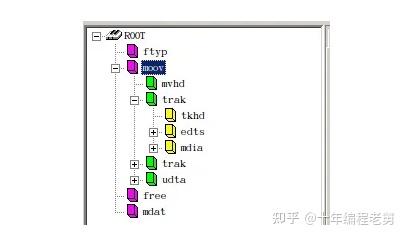
其中:
- tkhd(track header box):用于简单描述该路媒体流的信息,如时长,宽度等。
- mdia(media box):用于详细描述该路媒体流的信息
- edts(edit Box):子 Box 为 elst(Edit List Box),它的作用是使某个 track 的时间戳产生偏移。
2.7 tkhd(track header box)
- tkhd 作为媒体信息的 header 出现 (注意此 header 不是 box header,而是 track 媒体信息的 header),用于描述一些该 track 的基本信息。
- tkhd 语法继承自 fullbox,注意下述示例出现的 version 和 flags 字段属于 fullbox header。
Box Body:
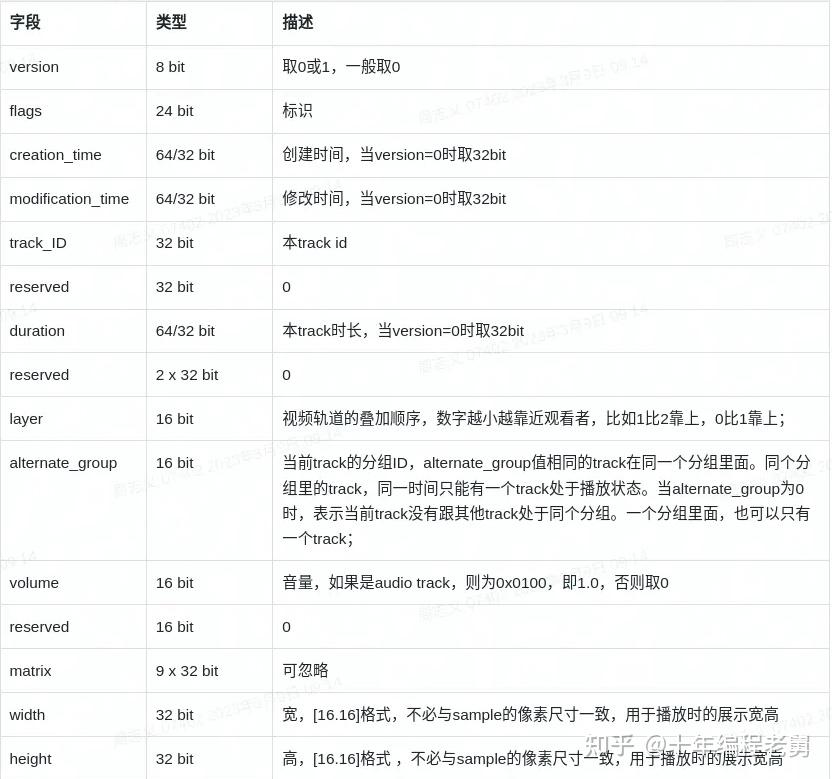
2.8 edts(edit Box)
它下边有一个 elst(Edit List Box),它的作用是使某个 track 的时间戳产生偏移。看一下一些字段:
- segment_duration: 表示该 edit 段的时长,以 Movie Header Box(mvhd)中的 timescale 为单位, 即 segment_duration/timescale = 实际时长(单位 s)
- media_time: 表示该 edit 段的起始时间,以 track 中 Media Header Box(mdhd)中的 timescale 为单位。如果值为 - 1(FFFFFF),表示是空 edit,一个 track 中最后一个 edit 不能为空。
- media_rate: edit 段的速率为 0 的话,edit 段相当于一个”dwell”,即画面停止。画面会在 media_time 点上停止 segment_duration 时间。否则这个值始终为 1。
- 需要注意的问题:
为使 PTS 从 0 开始,media_time 字段一般设置为第一个 CTTS 的值,计算 PTS 和 DTS 的时候,他们分别都减去 media_time 字段的值就可以将 PTS 调整为从 0 开始的值。
如果 media_time 是从一个比较大的值,则表示要求 PTS 值大于该值时画面才进行显示,这时应该将第一个大于或等于该值的 PTS 设置为 0,其他的 PTS 和 DTS 也相应做调整。
2.9 mdia(media box)
- 定义了 track 媒体类型以及 sample 数据,描述 sample 信息。
- 它是一个 container box,它必须包含 mdhd,hdlr 和 minf。
一个示例如下:

其中:
- mdhd(Media Header Box):用于简单描述该路媒体流的信息。
- hdlr(Handler Reference Box):主要定义了 track 类型。
- stbl(Media Information Box):用于描述该路媒体流的解码相关信息和音视频位置等信息。
2.10 mdhd(Media Header Box)
- mdhd 作为媒体信息的 header 出现 (注意此 header 不是 box header,而是 media 媒体信息的 header),用于描述一些该 media 的基本信息。
- mdhd 和 tkhd ,内容大致都是一样的。不过 tkhd 通常是对指定的 track 设定相关属性和内容。而 mdhd 是针对于独立的 media 来设置的。
- mdhd 语法继承自 fullbox,注意下述示例出现的 version 和 flags 字段属于 fullbox header。
Box Body:
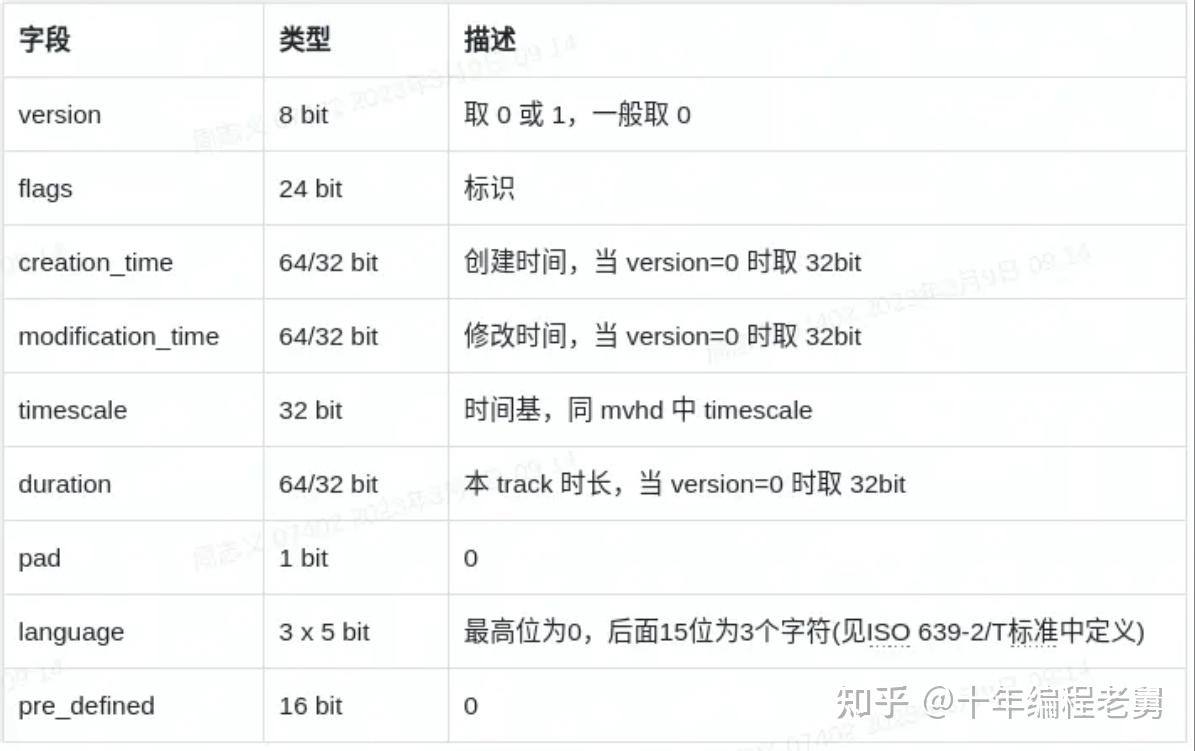
注:timescale 同 mvhd 中的 timescale,但是需要注意虽然意义相同,但是值有可能不同,下边 stts,ctts 等时间戳的计算都是以 mdhd 中的 timescale。
2.11 hdlr(Handler Reference Box)
- 主要解释了媒体的播放过程信息。声明当前 track 的类型,以及对应的处理器(handler)。
- hdlr 语法继承自 fullbox,注意下述示例出现的 version 和 flags 字段属于 fullbox header。
Box Body:

2.12 minf(Media Information box)
- 解释 track 媒体数据的 handler-specific 信息,media handler 用这些信息将媒体时间映射到媒体数据并进行处理。minf 同样是个 container box,其内部需要关注的内容是 stbl,这也是 moov 中最复杂的部分。
- 一般情况下,“minf”包含一个 header box,一个 “dinf” 和一个 “stbl”,其中,header box 根据 track type(即 media handler type)分为“vmhd”、“smhd”、“hmhd” 和“nmhd”,“dinf”为 data information box,“stbl”为 sample table box。
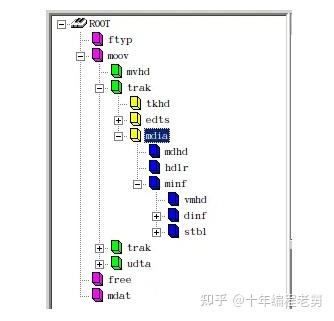
2.13 *mhd (Media Info Header Box)
可分为 “vmhd”、“smhd”、“hmhd” 和“nmhd”,比如视频类型则为 vmhd,音频类型为 smhd。
(1)vmhd
- graphics mode:视频合成模式,为 0 时拷贝原始图像,否则与 opcolor 进行合成。
- opcolor:一组 (red,green,blue),graphics modes 使用。
(2)smhd - balance:立体声平衡,[8.8] 格式值,一般为 0 表示中间,-1.0 表示全部左声道,1.0 表示全部右声道。
2.14 dinf(Data Information Box)
- 描述了如何定位媒体信息,是一个 container box。
- “dinf” 一般包含一个 “dref”(data reference box)。
- “dref”下会包含若干个 “url” 或“urn”,这些 box 组成一个表,用来定位 track 数据。简单的说,track 可以被分成若干段,每一段都可以根据 “url” 或“urn”指向的地址来获取数据,sample 描述中会用这些片段的序号将这些片段组成一个完整的 track。一般情况下,当数据被完全包含在文件中时,“url”或 “urn” 中的定位字符串是空的。
2.15 stbl(Sample Table Box)
在介绍 stbl box 之前,需要先介绍一下 mp4 中定义的 sample 与 chunk:
- sample:ISO/IEC 14496-12 中定义 samples 之间不能共享同一个时间戳,因此,在音视频 track 中,一个 sample 代表一个视频或音频帧。
- chunk:多个 sample 的集合,实际上音视频 track 中,chunk 与 sample 一一对应。
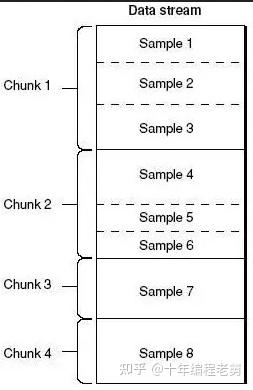
stbl box 是一个 container box,是整个 track 中最重要的一个 box,其子 box 描述了该路媒体流的解码相关信息、音视频位置信息、时间戳信息等。
MP4 文件的媒体数据部分在 mdat box 里,而 stbl 则包含了这些媒体数据的索引以及时间信息。
一个示例如下:
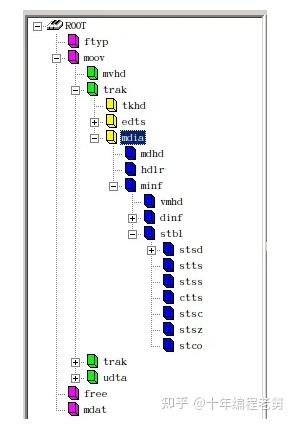
其中:
- stsd(sample description box):存储了编码类型和初始化解码器需要的信息,并与具体编解码器类型有关。
- stts(time to sample box):存储了该 track 每个 sample 到 dts 的时间映射关系。
- stss(sync sample box):针对视频 track,关键帧所属 sample 的序号。
- ctts(composition time to sample box):存储了该 track 中,每个 sample 的 cts 与 dts 的时间差。
- stsc/stz2(sample to chunk box):存储了该 track 中每个 sample 与 chunk 的映射关系。
- stsz(sample size box):存储了该 track 中每个 sample 的字节大小。
- stco/co64(chunk offset box):存储了该 track 中每个 chunk 在文件中的偏移。
2.16 stsd(sample description box)
主要存储了编码类型和初始化解码器需要的信息。这里以视频为例,包含子 box:avc1,表示是 H264 的视频。

2.16.1 h264 stsd
对于 h264 视频,典型结构如下:
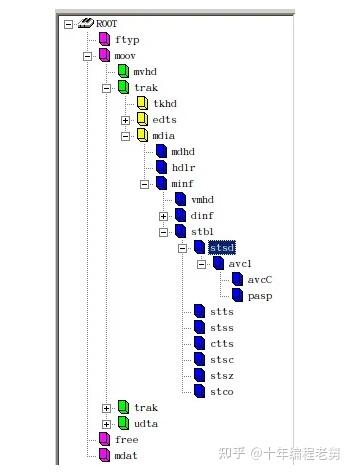
其上 (只列出 avc1 与 avcC,其余 box 可忽略):
- avc1,是 avc/h264/mpeg-4 part 10 视频编解码格式的代称,是一个 container box,但是 box body 也携带自身的信息。
Box Body:

avcC(AVC Video Stream Definition Box),存储 sps && pps,即在 ISO/IEC 14496-15 中定义的 AVCDecoderConfigurationRecord 结构

注:在 srs 中,解析 avcc/AVCDecoderConfigurationRecord 结构解析参见 srs/trunk/src/kernel/srs_kerner_codec.cpp::SrsFormat::avc_demux_sps_pps() 函数。
2.16.2 aac stsd
对于 aac 音频,典型结构如下:
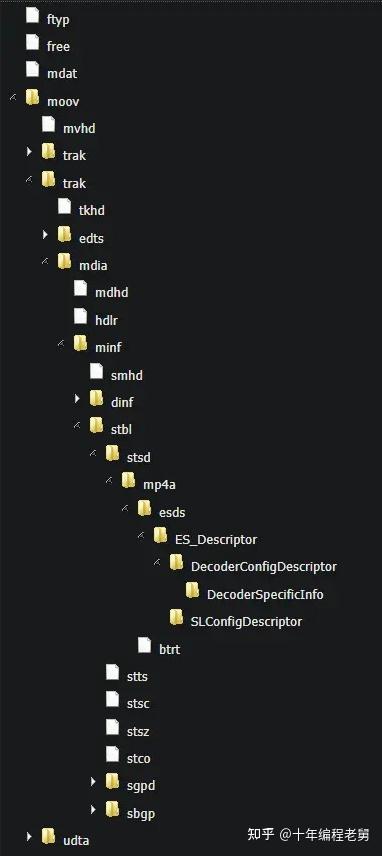
可以看到,aac stsd 结构比较复杂,box 众多。实际上,在 ISO/IEC 14496-3 中,定义了 AudioSpecificConfig 类型,aac stsd 结构主要信息就来自 AudioSpecificConfig。
具体不做分析,可以参看 srs 中:
- 解析 AudioSpecificConfig 结构的 srs/trunk/src/kernel/srs_kerner_codec.cpp::SrsFormat::audio_aac_sequence_header_demux() 函数
- 封装 aac stsd 结构的 srs/trunk/src/kernel/srs_kernel_mp4.cpp::SrsMp4Encoder::flush() 函数
2.17 stts(time to sample box)
- 存储了该 track 每个 sample 到 dts 的时间映射关系。
- 包含了一个压缩版本的表,通过这个表可以从解码时间映射到 sample 序号。表中的每一项是连续相同的编码时间增量 (Decode Delta) 的个数和编码时间增量。通过把时间增量累加就可以建立一个完整的 time to sample 表。
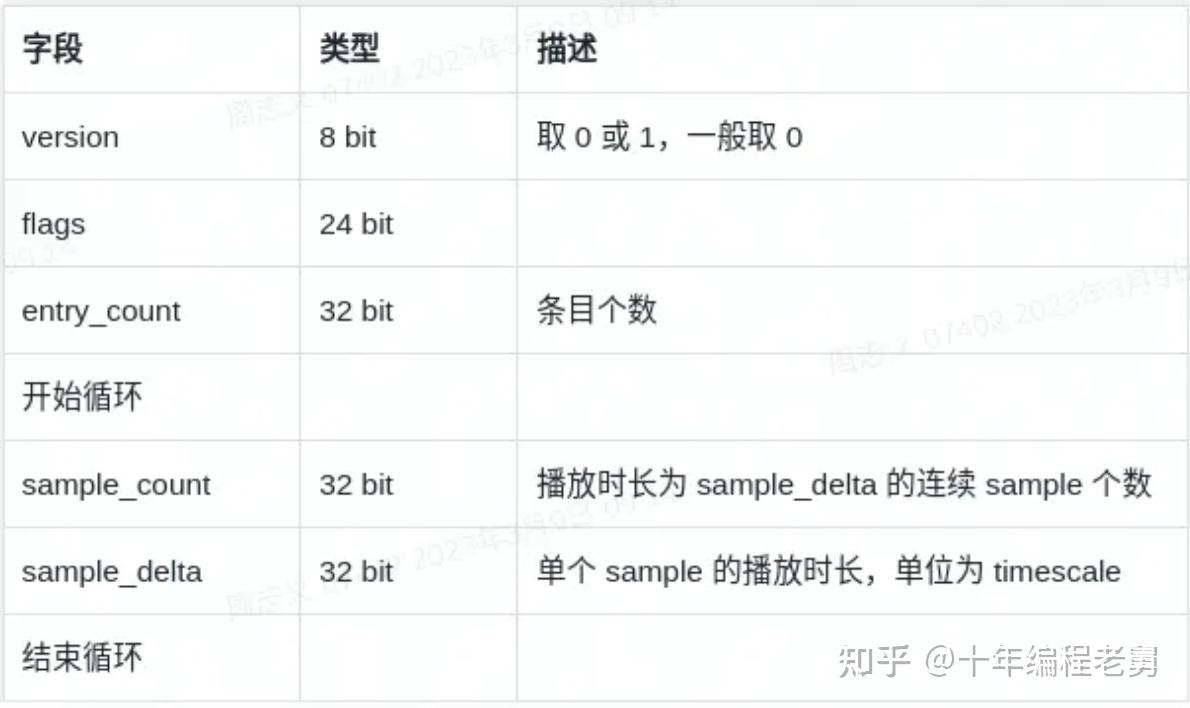
这里为了节约条目的个数,采用了压缩存储的方式,即 sample_count 个连续的 sample 如果 sample_delta 时长一样,那么用一个条目就能表示了。
一个音频 track 的示例如下:
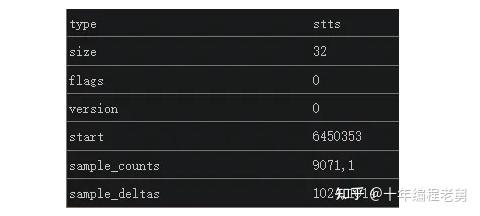
一个视频 track 的示例如下:
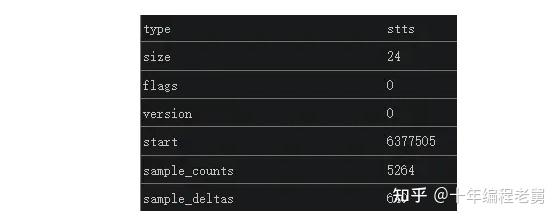
2.18 ctts(composition time to sample box)
- 存储了该 track 中,每个 sample 的 pts 与 dts 时间差 (cts = pts - dts):
- 如果一个视频只有 I 帧和 P 帧,则 ctts 这个表就不需要了,因为解码顺序和显示顺序是一致的,但是如果视频中存在 B 帧,则需要 ctts。

注意:
- 此 box 在 dts 和 pts 不一样的情况下必须存在,如果一样,不用包含此 box。
- 如果 box 的 version=0,意味着所有 sample 都满足 pts >= dts,因而差值用一个无符号的数字表示。只要存在一个 pts < dts,那么必须使用 version=1、有符号差值来表示。
- 关于 ctts 的生成,可以参看 srs/trunk/src/kernel/srs_kernel_mp4.cpp::SrsMp4SampleManager::write_track() 函数 pts、dts、cts 满足公式:pts - dts = cts。
2.19 stss(sync sample box)
它包含 media 中的关键帧的 sample 表。关键帧是为了支持随机访问。如果此表不存在,说明每一个 sample 都是一个关键帧。
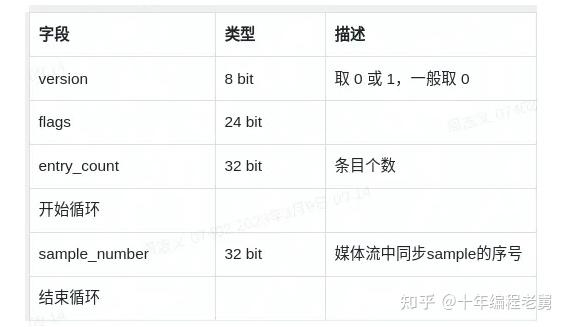
一个视频示例如下:
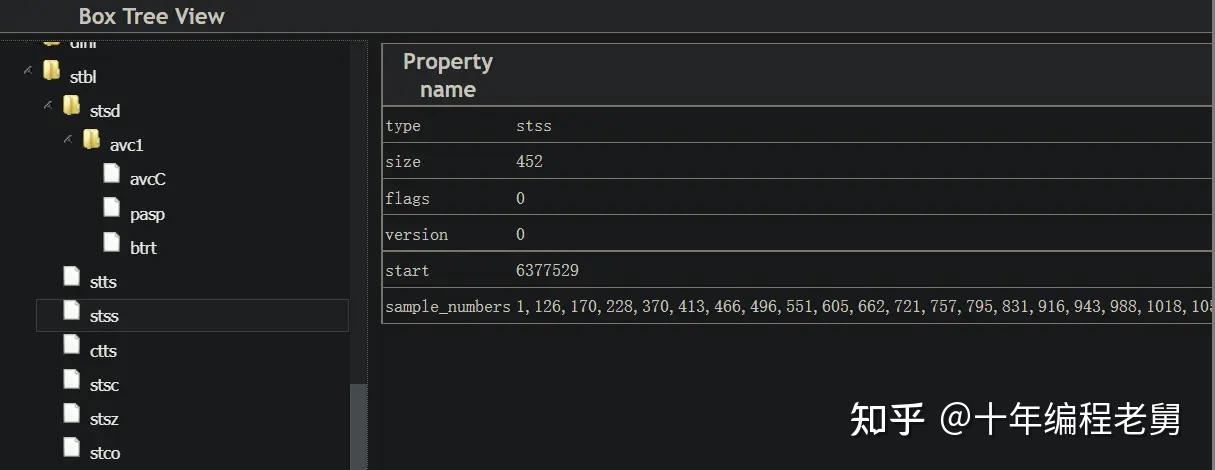
2.20 stsc/stz2(sample to chunk box)
存储了该 track 中每个 sample 与 chunk 的映射关系。
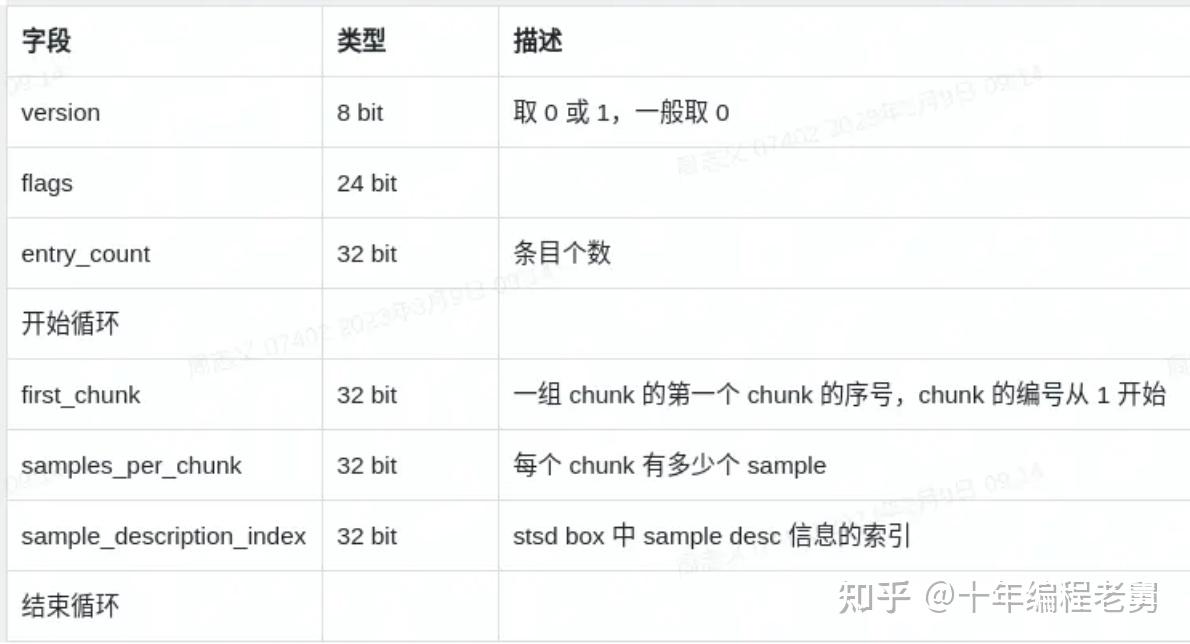
一个音频示例如下:
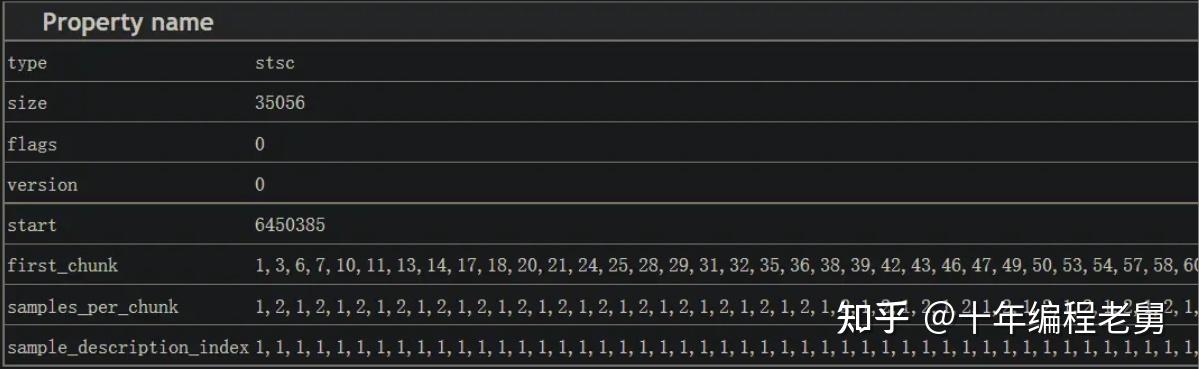
- 第一组 chunk 的 first_chunk 序号为 1,每个 chunk 的 sample 个数为 1,因为第二组 chunk 的 first_chunk 序号为 2,可知第一组 chunk 中只有一个 chunk。
- 第二组 chunk 的 first_chunk 序号为 2,每个 chunk 的 sample 个数为 2,因为第三组 chunk 的 first_chunk 序号为 24,可知第二组 chunk 中有 22 个 chunk,有 44 个 sample。
- 这个并不是说,这个视频流只有 3 个 sample,也就是只有 3 帧,不可能的,而是第三,第四行省略了,也就是说,第三跟第四,等等,后面的 chunk 里面都只有 1 个 sample,跟第二个 chunk 一样。本视频流有 239 个 chunk。因为本视频流一共 240 帧,第一个 chunk 里面有 2 帧,后面的都是 1 帧,所以计算出来只有 239 个 chunk。
2.21 stsz(sample size box)
包含 sample 的数量和每个 sample 的字节大小,这个 box 相对来说体积比较大的。表明视频帧或者音频帧大小,FFmpeg 里面的 AVPacket 的 size 数据大小,就是从这个 box 中来的。

2.22 stco/co64(chunk offset box)
- Chunk Offset 表存储了每个 chunk 在文件中的位置,这样就可以直接在文件中找到媒体数据,而不用解析 box。
- 需要注意的是一旦前面的 box 有了任何改变,这张表都要重新建立。
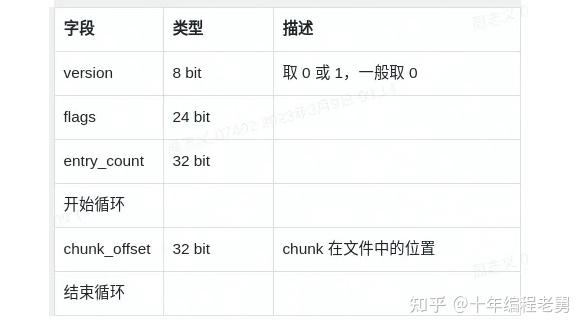
stco 有两种形式,如果你的视频过大的话,就有可能造成 chunkoffset 超过 32bit 的限制。所以,这里针对大 Video 额外创建了一个 co64 的 Box。它的功效等价于 stco,也是用来表示 sample 在 mdat box 中的位置。只是,里面 chunk_offset 是 64bit 的。
- 需要注意,这里 stco 只是指定的每个 Chunk 在文件中的偏移位置,并没有给出每个 Sample 在文件中的偏移。想要获得每个 Sample 的偏移位置,需要结合 Sample Size box 和 Sample-To-Chunk 计算后取得。
2.23 udta(user data box)
用户自定义数据。
2.24 free(free space box)
- “free” 中的内容是无关紧要的,可以被忽略。该 box 被删除后,不会对播放产生任何影响。
- Ftyp 可以是 free 或 skip。
2.25 mdat(media data box)
- mdat 就是具体的编码后的数据。
- mdat 也是一个 box,拥有 box header 和 box body。
- mdat 可以引用外部的数据,参见 moov –> udta –> meta,这里不讨论,只讨论数据存储在本文件中的形式。
- 对于 box body 部分,采用一个一个 samples 的形式进行存储,即一个一个音频帧或视频帧的形式进行存储。
- 码流组织方式采用 avcc 格式,即 AUD + slice size + slice 的形式。
第7章
音频格式
1 序
2 目录
第8章
模型3D
1 序
2 目录
7 平台
目录
平台 的子部分
7.1 windows
windows 的子部分
1.1 调试
调试 的子部分
1.1 Minidump
本文由 简悦 SimpRead 转码, 原文地址 blog.csdn.net
1. 简介
在过去几年里,崩溃转储 (crash dump) 成为了调试工作的一个重要部分。如果软件在客户现场或者测试实验室发生故障,最有价值的解决方式是能够创建一个故障瞬间的应用程序状态镜像,然后可以在开发者的机器上通过调试器进行分析。第一代的 crash dump 通常被称为 “全用户转储(full user dump)”,它包含了进程的虚拟内存的全部内容。毫无疑问,这样的 dump 对于事后调试非常有价值。但是,这样的 dump 经常非常大,使得通过电子方式发送给开发者非常困难,甚至没法完成。另外,没用公共接口可以通过程序调用来创建 dump,我们必须依赖于第三方工具(例如,Dr. Watson 或者 Userdump) 来创建他们。
随着 Windows XP,微软发布了一组新的被称为 “minidump” 的崩溃转存技术。Minidump 很容易定制。按照最常用的配置,一个 minidump 只包括了最必要的信息,用于恢复故障进程的所有线程的调用堆栈,以及查看故障时刻局部变量的值。这样的 dump 文件通常很小(只有几 K 字节)。所以,很容易通过电子方式发送给软件开发人员。一旦需要,minidump 甚至可以包含比原来的 crash dump 更多的信息。例如,可以包含进程使用的内核对象的信息。另外,DbgHelp.dll 提供了通过编程创建 minidump 的公开 API。而且,它是可以重新发布的。我们可以不再依赖于外部工具。
minidump 可以定制,给我们带来了一个问题 - 保存多少应用程序状态信息才能既保证调试有效,又能够尽量保证 minidump 文件尽可能小?尽管调试简单的异常访问只需要调用堆栈和局部变量的信息,但是解决更复杂的问题需要更多的信息。例如,我们可能需要查看全局变量的值、检查堆的完整性和分析进程虚拟内存的布局。同时,可执行程序的代码段往往是多余的,开发用的机器上可以很容易找到这些执行程序。
幸运的是我们可以通过 DbgHelp 函数组(MiniDumpWriteDump 和 MiniDumpCallback)来控制这些功能,甚至可以更复杂。在这篇文章里面,我们会解释怎么样使用这些函数来创建 mindump,保证文件足够小但是又能有效调试。也会讲解 minidump 中应该包括那些数据,并且如何使用通用调试器 (WinDbg 和 VS.NET) 来看这些信息。
2. Minidump 类型
先看一些代码。Figure 1 是 MiniDumpWriteDump 的函数声明。Figure 2 显示如何使用这个函数创建简单的 minidump。
Figure 1:
BOOL MiniDumpWriteDump(
HANDLE hProcess,
DWORD ProcessId,
HANDLE hFile,
MINIDUMP_TYPE DumpType,
PMINIDUMP_EXCEPTION_INFORMATION ExceptionParam,
PMINIDUMP_USER_STREAM_INFORMATION UserStreamParam,
PMINIDUMP_CALLBACK_INFORMATION CallbackParam
);Figure 2:
void CreateMiniDump(EXCEPTION_POINTERS* pep)
{
// Open the file
HANDLE hFile = CreateFile(_T("MiniDump.dmp"), GENERIC_READ | GENERIC_WRITE,
0, NULL, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL);
if ((hFile != NULL) && (hFile != INVALID_HANDLE_VALUE))
{
// Create the minidump
MINIDUMP_EXCEPTION_INFORMATION mdei;
mdei.ThreadId = GetCurrentThreadId();
mdei.ExceptionPointers = pep;
mdei.ClientPointers = FALSE;
MINIDUMP_TYPE mdt = MiniDumpNormal;
BOOL rv = MiniDumpWriteDump(GetCurrentProcess(), GetCurrentProcessId(),
hFile, mdt, (pep != 0) ? &mdei : 0, 0, 0);
if (!rv)
_tprintf(_T("MiniDumpWriteDump failed. Error: %u \n"), GetLastError());
else
_tprintf(_T("Minidump created.\n"));
// Close the file
CloseHandle(hFile);
}
else
{
_tprintf(_T("CreateFile failed. Error: %u \n"), GetLastError());
}
}在这个例子里面,我们如何指定 minidump 应该包括那些数据呢?主要取决于 MiniDumpWriteDump 的第四个参数 MINIDUMP_TYPE。下表 Figure 3 是参数的定义。
Figure 3:
typedef enum _MINIDUMP_TYPE {
MiniDumpNormal = 0x00000000,
MiniDumpWithDataSegs = 0x00000001,
MiniDumpWithFullMemory = 0x00000002,
MiniDumpWithHandleData = 0x00000004,
MiniDumpFilterMemory = 0x00000008,
MiniDumpScanMemory = 0x00000010,
MiniDumpWithUnloadedModules = 0x00000020,
MiniDumpWithIndirectlyReferencedMemory = 0x00000040,
MiniDumpFilterModulePaths = 0x00000080,
MiniDumpWithProcessThreadData = 0x00000100,
MiniDumpWithPrivateReadWriteMemory = 0x00000200,
MiniDumpWithoutOptionalData = 0x00000400,
MiniDumpWithFullMemoryInfo = 0x00000800,
MiniDumpWithThreadInfo = 0x00001000,
MiniDumpWithCodeSegs = 0x00002000,
MiniDumpWithoutManagedState = 0x00004000,
} MINIDUMP_TYPE;MINIDUMP_TYPE 枚举是一些标志,允许我们来控制 minidump 包含哪些内容。我们来看一下这些值得内容,以及如何使用它们。
MiniDumpNormal
MiniDumpNormal 是一个特别的标志。它的值是 0,意味着这个值永远隐含存在,甚至不需要显示指定。因此,我们可以假定这个标记代表了 minidump 中永远存在的一组基础数据集合。通过指定用户自定义的回调函数,可以过滤这些值。
Figure 4 的表格显示了数据基础数据集合中的数据类型。
Figure 4:
| 数据类型 | 描述 |
|---|---|
| 系统信息 | 关于操作系统和 CPU 的信息,包括:操作系统版本 (包括服务包) 处理器的数量和型号在 WinDbg 中,可以通过 “vertarget” 和 “!cpuid” 显示相应信息。 |
| 进程信息 | 关于进程 (Process) 的信息,包括:进程 ID 进程时间(创建时间,用户态和核心态的执行时间)WinDbg 通过 | (Process Status)命令显示进程 ID,“.time”显示进程时间。 |
| 模块(Module) 信息 | 对于进程装载的所有可执行模块,显示如下信息:装载地址模块的大小文件名(包括路径)版本信息 (VS_FIXEDFILEINFO structure) 模块识别信息,帮助调试器定位相应的模块并且装载调试信息 (校验和,时间戳,调试信息记录)在 WinDbg 和 VS.NET 中,可以在 Modules 窗口中看到这些信息。WinDbg 的 “lm” 也可以看到这些信息。 |
| 线程信息 | 对于进程中的任何一个线程,会包括这些信息:线程 ID 优先级线程上下文暂停计数 (Suspend count) 线程环境块 (thread environment block ,TEB) 的地址,但是不包括 TEB 的内容 VS.NET 中,Threads 窗口中可以显示大多数这些信息。WinDbg 中用 “~”命令显示线程信息。 |
| 线程栈 | 对于每一个线程,minidump 包含了栈内存的内容。允许我们得到所有线程的调用栈,查看函数参数和局部变量的值。 |
| 指令窗口 | 对于每一线程,当前指令指针前后的 256 自己内存会保留下来。允许我们即使没有可执行模块,也可以获得故障时刻的线程代码的反编译信息。 |
| 异常信息 | 可以通过 MiniDumpWriteDump 函数的第 5 个参数 (见 Figure 2) 把异常信息包含到 minidump 中。这种情况下 minidump 会包括如下异常信息:异常记录 (EXCEPTION_RECORD structure)异常发生时刻的线程上下文指令窗口(发生异常的指令地址附近的 256 字节)当 VS.NET debugger 装载带有异常信息的 minidump 数据, debugger 会自动显示异常时刻应用程序状态(包括调用堆栈、寄存器值、反汇编的指令和抛出异常的代码行)。WinDbg 中,需要使用. ecxr 命令切换到异常发生时刻的应用程序状态。 |
确实,MiniDumpNormal 指定的基础信息集合非常有用。我们可以定位出现问题的指令,检查线程怎么样进入到这种状态。甚至可以产看到函数参数和局部变量的值。另外,这些信息也可以用来调试死锁,因为我们可以看到所有线程的调用栈,并且知道他们在等待什么。
同时,所有这些信息的代价非常小,minidump 的大小通常不超过 20KB。主要影响大小的因素的线程栈的大小 - 他们占用的内存越多,minidump 的文件越大。
但是,如果需要调试的问题比较复杂,而不是像非法访问或者死锁这样的简单问题,我们就会发现 MiniDumpNormal 标记收集的信息还不够。我们有可能需要查看全局变量,但是里面没有。也有可能需要查看堆里面分配的结构体的内容,minidump 也没有包括相应的堆信息。当我们需要更多的 minidump 数据时,就需要研究 MINIDUMP_TYPE 的其他成员了。
MiniDumpWithFullMemory
这可能是除了 MiniDumpNormal 以外使用最多的标志了。如果指定了这个标志,minidump 会包含进程地址空间中所有可读页面的内容。我们可以看到应用程序分配的所有内存,这使我们有很多的调试方法。可以查看存储在栈上、堆上、模块数据段的所有数据。甚至还可以看到线程和进程环境块 (Process Environment Block 和 Thread Environment Bolck, PEB 和 TEB) 的数据。这些没有公开的数据结构可以给我们的调试提供无价的帮助。
使用这个标记的唯一问题是会使 minidump 变得很大,至少有几 MByte。另外,minidump 的内容里面包含了冗余信息,所有可执行模块的代码段都包含在了里面。但是很多时候,我们很容易从其他地方获得可执行代码。让我们一起来看看 MINIDUMP_TYPE,是否能够找到更好的选项。
MiniDumpWithPrivateReadWriteMemory
如果指定这个标志,minidump 会包括所有可读和可写的私有内存页的内容。这使我们可以察看栈、堆甚至 TLS 的数据。PEB 和 TEB 也包括在里面。
这时候,minidump 没有包括共享内存也的内容。也就是说,我们不能查看内存映射文件的内容。同样,可执行模块的代码和数据段也没有包括进来。不包括代码段意味着 dump 没有占用不需要的空间。但是,我们也没有办法查看全局变量的值。
无论如何,通过组合其他一些选项,MiniDumpWithPrivateReadWriteMemory 是一个非常有用的选项。我们会在后面看到。
MiniDumpWithIndirectlyReferencedMemory
如果指定这个标志,MiniDumpWriteDump 检查线程栈内存中的每一个指针。这些指针可能指向线程地址空间的其他可读内存页。一旦发现这样的指针,程序会读取指针附近 1024 字节的内容存到 minidump 中(指针前的 256 字节和指针后的 768 字节)。
Figure 5 是一段例子代码.
Figure 5:
#include <stdio.h>
struct A
{
int a;
void Print()
{
printf("a: %d\n", a);
}
};
struct B
{
A* pA;
B() : pA(0) {}
};
int main(int argc, char* argv[])
{
B* pB = new B();
pB->pA->Print();
return 0;
}在这个例子中,主程序试图通过 null 对象指针(pB->pA)调用 A::Print。这会导致一个运行时非法访问。如果使用 MiniDumpNormal 产生的 minidumo 来调试,会发现没有办法看到指针 pB 指向的结构体的内容。这些内容存在堆上。我们只能猜测传给 A::Print 的对象指针是 null。
如果我们指定了标志 MiniDumpWithIndirectlyReferencedMemory,MiniDumpWriteDump 会发现栈上有一个指针 pB 指向了堆上的其他区域。就会把 pB 指向地址附近的 1024 字节存到 minidump 中。因此,通过调试器就可以看到结构体 B 的内容,进而发现 pA 是 null。
当然,MiniDumpWriteDump 不能访问调试信息。因此,他没有办法区分真正的指针和另外一些值。这些值恰好可以被认为指向有效内存区域。Figure 6. 解释了这种情况。
Figure 6:
#include <stdio.h>
void PrintSum(unsigned long sum)
{
printf("sum: %x", sum);
// access violation
*(int*)0 = 1;
}
unsigned long Sum(unsigned long a, unsigned long b)
{
unsigned long sum = a + b;
PrintSum(sum);
return sum;
}
int main()
{
Sum(0x10000, 0x120);
return 0;
}当 PrintSum 导致非法访问的时候,0x10000 和 0x120 的和保存在栈上。这个和 (0x10120) 不是指针。但是,MiniDumpWriteDump 没有办法知道。如果 0x10120 恰好是可读内存页的有效地址,minidump 会包括 1024 字节的内存(0x10020 – 0x10520)。
当搜索栈的时候,MiniDumpWriteDump 会忽略指向可执行模块的数据段的指针。这就导致 MiniDumpWithIndirectlyReferencedMemory 没办法让我们看到全局变量的值。即使栈指向它们都不行。后面我们会看到,MINIDUMP_TYPE 还包括其他标志可以完成这个功能。
加上 MiniDumpWithIndirectlyReferencedMemory 标记,minidump 大小会增加。增加的数量取决于栈中指针的数量。
MiniDumpWithDataSegs
如果指定这个标志,minidump 会包括进程装载的所有可执行模块的可写数据段。如果我们希望查看全局变量的值,有不希望被 MiniDumpWithFullMemory 困扰,就可以使用 MiniDumpWithDataSegs。
这个标志对于 minidump 大小的影响完全取决于相关数据段的大小。系统 DLL 的数据段也包含在内,所以,即使一个简单的程序,也可能会增加几百 KB。 例如,DbgHelp 的. data 段超过 100K。如果我们只是为了使用 MiniDumpWriteDump,这代价可能太大了。在文章的后半部分,会给大家演示,怎么样控制 MiniDumpWriteDump 来保证只包含真正需要的数据段。
MiniDumpWithCodeSegs
如果指定这个标志,mindump 会包括所有进程装载的可执行模块的代码段。就像 MiniDumpWithDataSegs,minidump 大小会有明显增长。在文章的后半部分,我会演示增么样定制 MiniDumpWriteDump,保证只包含必要的代码段。
MiniDumpWithHandleData
如果指定这个标志,minidump 会包括故障时刻进程故障表里面的所有句柄。可以用 WinDbg 的! handle 来显示这些信息。
这个标志对于 minidump 大小的影响取决于进程句柄表中的句柄数量。
MiniDumpWithThreadInfo
MiniDumpWithThreadInfo 可以帮助收集进程中线程的附加信息。对于每一个线程,会提供下列信息:
- 线程时间 (创建时间,执行用户代码和内核代码的时间)
- 入口地址
- 相关性
WinDbg 中,可以通过. ttime 命令查看线程时间。
MiniDumpWithProcessThreadData
有些时候我们需要查看线程和进程环境块的内容(PEB 和 TEB)。假设 minidump 包括了这些块占用的内存,就可以通过 WinDbg 的! peb 和! teb 命令来查看。这正是 MiniDumpWithProcessThreadData 所提供的数据。当使用这个标志时,minidump 会包含 PEB 和 TEB 占据的内存页。同时,也包括了另外一些它们也用的内存页 (例如,环境变量和进程参数保存的位置,通过 TlsAlloc 分配的 TLS 空间)。遗憾的是,有一些 PEB 和 TEB 引用的内存被忽略了,例如,通过__declspec(thread) 分配的线程 TLS 数据。如果确实需要,就不得不使用 MiniDumpWithFullMemory 或者 MiniDumpWithPrivateReadWriteMemory 来获得。
MiniDumpWithFullMemoryInfo
如果希望检查整个继承的虚拟内存布局,我们可以使用 MiniDumpWithFullMemoryInfo 标志。如果指定它,mindump 会包含进程虚拟内存布局的完整信息。可以通过 WinDbg 的! vadump 和! vprot 命令查看。这个标志对 minidump 大小的影响取决于虚拟内存布局 - 每个有相似特性的页面区域(参考 VirtualQuery 函数说明)会增加 48 字节。
MiniDumpWithoutOptionalData
我们已经看过的所有 MINIDUMP_TYPE 标记都是想 minidump 中添加一些数据。也有一些标志作用相反,它们从 minidump 中去除一些不必要的数据。MiniDumpWithoutOptionalData 就是其中一个。他可以用来减小保存在 dump 中的内存的内容。当指定这个标志是,只有 MiniDumpNormal 指定的内存会被保存。其他内存相关的标志 (MiniDumpWithFullMemory, MiniDumpWithPrivateReadWriteMemory, MiniDumpWithIndirectlyReferencedMemory) 即使指定,也是无效的。同时,他不影响这些标志的行为:MiniDumpWithProcessThreadData, MiniDumpWithThreadInfo, MiniDumpWithHandleData, MiniDumpWithDataSegs, MiniDumpWithCodeSegs, MiniDumpWithFullMemoryInfo
MiniDumpFilterMemory
如果指定这个标志,栈内存的内容会在保存之前进行过滤。只有重建调用栈需要的数据才会被保留。其他数据会被写成 0。也就是说,调用栈可以被重建,但是所有局部变量和函数参数的值都是 0。
这个标志不影响 minidump 的大小。它只是没有改变保存的内存数量,只是把其中一部分用 0 覆盖了。同时,这个标志只影响线程栈占用内存的内容。其他内存(比如堆)不受影响。如果使用了 MiniDumpWithFullMemory,这个标志就不起作用了。
MiniDumpFilterModulePaths
这个标志控制模块信息中是否包括模块路径 (参考 MiniDumpNormal 的说明)。如果指定这个标记,模块路径会从 dump 中删除,只保留模块的名字。按照文档说明,它也可以帮助从 minidump 中删除可能涉及隐私的信息(例如有些时候模块的路径会包含用户名)。
由于模块路径数量不多,这个标志对 minidump 的大小影响不大。对调试的影响也不大。我们经常需要告诉调试器匹配的可执行程序保存的位置。
MiniDumpScanMemory
这个标志可以帮助我们节约 minidump 占用的空间。它会把调试不需要的可执行模块去掉。这个标志会和 MiniDumpCallback 函数紧密合作。因此,我们首先看一下这个函数,然后回头讨论 MiniDumpScanMemory。
3. MiniDumpCallback 函数
如果 MINIDUMP_TYPE 不能满足我们定制 minidump 内容的需要,我们可以使用 MiniDumpCallback 函数。这是一个用户定义的回调函数,MiniDumpWriteDump 会调用它,让用户来决定是否把某些数据放到 minidump 中。通过这个函数,我们可以完成这些功能:
- 从 minidump 的模块信息中移除一个可执行模块信息(部分或者全部)
- 从 minidump 的线程信息中移除一个线程信息(部分或者全部)
- 在 minidump 中添加一段用户指定范围的内存的内容
让我们先看一下 MiniDumpCallback 的声明(见 Figure 7):
Figure 7:
BOOL CALLBACK MiniDumpCallback(
PVOID CallbackParam,
const PMINIDUMP_CALLBACK_INPUT CallbackInput,
PMINIDUMP_CALLBACK_OUTPUT CallbackOutput
);这个函数有四个参数。第一个参数 CallbackParam 是一个用户为回调函数定义的数据结构(例如,一个指向 C++ 对象的指针)。第二个参数 CallbackInput 是 MiniDumpWriteDump 传递给回调函数的数据。第三个参数 CallbackOutput 包含了回调函数返回给 MiniDumpWriteDump 的数据。这个数据通常就是指定关于那些数据应该包含在 minidump 中。
现在,让我们看一下 MINIDUMP_CALLBACK_INPUT 和 MINIDUMP_CALLBACK_OUTPUT 结构体的内容。
Figure 8:
typedef struct _MINIDUMP_CALLBACK_INPUT {
ULONG ProcessId;
HANDLE ProcessHandle;
ULONG CallbackType;
union {
HRESULT Status;
MINIDUMP_THREAD_CALLBACK Thread;
MINIDUMP_THREAD_EX_CALLBACK ThreadEx;
MINIDUMP_MODULE_CALLBACK Module;
MINIDUMP_INCLUDE_THREAD_CALLBACK IncludeThread;
MINIDUMP_INCLUDE_MODULE_CALLBACK IncludeModule;
};
} MINIDUMP_CALLBACK_INPUT, *PMINIDUMP_CALLBACK_INPUT;
typedef struct _MINIDUMP_CALLBACK_OUTPUT {
union {
ULONG ModuleWriteFlags;
ULONG ThreadWriteFlags;
struct {
ULONG64 MemoryBase;
ULONG MemorySize;
};
struct {
BOOL CheckCancel;
BOOL Cancel;
};
HANDLE Handle;
};
} MINIDUMP_CALLBACK_OUTPUT, *PMINIDUMP_CALLBACK_OUTPUT;
typedef enum _MINIDUMP_CALLBACK_TYPE {
ModuleCallback,
ThreadCallback,
ThreadExCallback,
IncludeThreadCallback,
IncludeModuleCallback,
MemoryCallback,
CancelCallback,
WriteKernelMinidumpCallback,
KernelMinidumpStatusCallback,
} MINIDUMP_CALLBACK_TYPE;MINIDUMP_CALLBACK_INPUT 结构体包含 MiniDumpWriteDump 对回调函数的请求。前两个成员意义很明显 - 创建 minidump 的进程的 id 和句柄。第三个成员 CallbackType 是请求的类型,通常叫做回调类型。所有 CallbackType 的可能的值定义在 MINIDUMP_CALLBACK_TYPE 枚举集合中(见 Figure 8)。我们在后面会仔细看一下这些值。结构体的第四个参数是一个联合,它的意义依赖于 CallbackType 的值。这个联合包含了 MiniDumpWriteDump 请求的附加数据。
MINIDUMP_CALLBACK_OUTPUT 结构体要简单一点。它有一个联合构成,联合的意义依赖于 MINIDUMP_CALLBACK_INPUT 的值。联合的 CallbackType 成员包含了回调对于 MiniDumpWriteDump 的反馈。
下面我们来过一下回调类型 (callback type) 对应的一些最终重要的请求,以及回调函数如何对他们做出响应。在开始之前,先看一下 Figure 9。这个例子表示了怎么样告诉 MiniDumpWriteDump 有一个用户自定的回调函数需要调用。
Figure 9:
void CreateMiniDump(EXCEPTION_POINTERS* pep)
{
// Open the file
HANDLE hFile = CreateFile(_T("MiniDump.dmp"), GENERIC_READ | GENERIC_WRITE,
0, NULL, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL);
if ((hFile != NULL) && (hFile != INVALID_HANDLE_VALUE))
{
// Create the minidump
MINIDUMP_EXCEPTION_INFORMATION mdei;
mdei.ThreadId = GetCurrentThreadId();
mdei.ExceptionPointers = pep;
mdei.ClientPointers = FALSE;
MINIDUMP_CALLBACK_INFORMATION mci;
mci.CallbackRoutine = (MINIDUMP_CALLBACK_ROUTINE)MyMiniDumpCallback;
mci.CallbackParam = 0; // this example does not use the context
MINIDUMP_TYPE mdt = MiniDumpNormal;
BOOL rv = MiniDumpWriteDump(GetCurrentProcess(), GetCurrentProcessId(),
hFile, mdt, (pep != 0) ? &mdei : 0, 0, &mci);
if (!rv)
_tprintf(_T("MiniDumpWriteDump failed. Error: %u \n"), GetLastError());
else
_tprintf(_T("Minidump created.\n"));
// Close the file
CloseHandle(hFile);
}
else
{
_tprintf(_T("CreateFile failed. Error: %u \n"), GetLastError());
}
}
BOOL CALLBACK MyMiniDumpCallback(
PVOID pParam,
const PMINIDUMP_CALLBACK_INPUT pInput,
PMINIDUMP_CALLBACK_OUTPUT pOutput
)
{
// Callback implementation
…
}IncludeModuleCallback
当回调类型被设成 IncludeModuleCallback,MiniDumpWriteDump 询问回调函数是否要把特定可执行模块的信息存到 minidump 中。回调函数根据 MINIDUMP_CALLBACK_INPUT 的内容做出决定。此时,联合成员应该是 MINIDUMP_INCLUDE_MODULE_CALLBACK:
typedef struct _MINIDUMP_INCLUDE_MODULE_CALLBACK {
ULONG64 BaseOfImage;
} MINIDUMP_INCLUDE_MODULE_CALLBACK, *PMINIDUMP_INCLUDE_MODULE_CALLBACK;这里,BaseOfImage 是模块在内存中的基地址。利用这个地址,可以获得模块更多的信息,以便决定是否需要存到 minidump 中。
回调函数利用返回值来把决定返回给 MiniDumpWriteDump。如果回调返回值是 TRUE,关于模块的信息会被包含进 minidump 中。通过后续的回调调用可以更精确的定义那些信息需要保存。如果返回值是 FALSE,模块的所有信息会被丢弃。Minidump 中看不到任何模块存在的痕迹。
对于这个回调类型,MINIDUMP_CALLBACK_OUTPUT 没有用处。
ModuleCallback
一个模块通过了 IncludeModuleCallback 的测试之后,它会面临在通往 minidump 之路上的另外一个障碍。这个障碍是 ModuleCallback。这个回调函数会决定关于这个模块的哪些信息需要保存。
这一次回调函数必须返回 TRUE,来保证 MiniDumpWriteDump 继续工作。回调函数使用 MINIDUMP_CALLBACK_OUTPUT 结构体通知 MiniDumpWriteDump 的关于数据的决定。这个结构体中的联合包括一个 ModuleWriteFlags 成员。MiniDumpWriteDump 会初始化它的值。它的值代表了可以保存在 minidump 中的各种模块信息。MODULE_WRITE_FLAGS 枚举包含了所有可用的标志。
Figure 10:
typedef enum _MODULE_WRITE_FLAGS {
ModuleWriteModule = 0x0001,
ModuleWriteDataSeg = 0x0002,
ModuleWriteMiscRecord = 0x0004,
ModuleWriteCvRecord = 0x0008,
ModuleReferencedByMemory = 0x0010,
ModuleWriteTlsData = 0x0020,
ModuleWriteCodeSegs = 0x0040,
} MODULE_WRITE_FLAGS;当 MiniDumpWriteDump 带着 ModuleCallback 参数调用回调函数,它会设置一些标志,告诉回调函数哪些模块信息可以包含在 minidump 中。回调函数可以分析这些标志,然后决定清除其中的一部分和还是全部。这样就可以告诉 MiniDumpWriteDump 哪些信息不需要保存。Figure 11 中的表格列出了目前可用的所有标志,并且解释了他们所代表的信息。
Figure 11:
| 标志 | 描述 |
|---|---|
| ModuleWriteModule | 这个标志允许从 minidump 中排除模块的所有信息。如果回调函数清除了这个标志,minidump 中就不会包含这个模块的任何信息。 默认条件下,这个标志总是被设置的。 |
| ModuleWriteCvRecord, ModuleWriteMiscRecord | 这些标志可以用来从 minidump 中排除模块的调试信息记录。如果清除这个标志,只有在开发机器是有这个模块的时候,调试器才能装载模块的调试信息。 通常,只有在模块包含调试信息记录的时候,这些标志才会被设置,也就是,模块是带着调试信息进行编译的时候。 可以在这里面找到关于调试信息的更详细说明,http://www.debuginfo.com/articles/debuginfomatch.html |
| ModuleWriteDataSeg | 这个标志可以用来从 minidump 中排除模块的数据段的内容。如果我们在 MiniDumpWriteDump 使用了 MiniDumpWithDataSegs 标志,又希望选择哪些模块的数据段需要包含进来,这个标记就非常有用了。通常,我们希望看到所有我们自己模块的数据段(以便在调试器中看到全局变量),以及一小部分系统模块(比如,ntdll.dll)。其他第三方模块或者系统模块的数据段没有用处。由于可执行模块的数据段在 minidump 中占用了很大的空间。这个标记给我们提供一个很好的优化文件尺寸的机会。 只有 MiniDumpWithDataSegs 标志被传给 MiniDumpWriteDump 的时候,这个标志才会被设置。 |
| ModuleWriteCodeSegs | 这个标记可以用来从 minidump 中排除模块的代码段。只有 MiniDumpWithCodeSegs 传给 MiniDumpWriteDump 函数的时候,这个标志才可用。这个标志可以用来选择哪些模块的代码段可以包含在 minidump 中。一定不要包含所有模块的代码段,这会显著增加 minidump 的大小。 |
| ModuleReferencedByMemory | 这个标志需要和 MINIDUMP_TYPE 中的 MiniDumpScanMemory 一起使用。如果 MiniDumpScanMemory 被传给 MiniDumpWriteDump,函数会遍历进程中的所有线程栈,查找指向可执行模块的地址空间的所有指针。搜索完成后,MiniDumpWriteDump 就知道了哪些模块被引用了,哪些模块没有被引用。 如果一个模块没有被任何一个线程栈引用,那么重建调用栈可能不会用到这个模块。Minidump 就可以不包括这个模块,来节省空间。为了让回调函数作最终决定,如果一个模块被栈引用了,MiniDumpWriteDump 会设置 ModuleReferencedByMemory 标志,没有被引用的模块的标志会被清除。. 接着,回调函数可以检查这个模块是否被引用过。然后,可以通过清除 ModuleWriteModule 标志,来把模块排除到 minidump 之外。 |
| ModuleWriteTlsData | 这个标志可能是用来控制模块的 TLS 数据(通过__declspec(thread) 分配)是否要包括在 mindump 中。但是,到写这篇文章为止,还不能工作。 |
注意 ModuleCallback 只允许我们排除一些模块信息,但是不允许添加新的数据。这意味着,如果 MiniDumpWriteDump 没有设置相应的标志,在回调函数中设置相应的标志没有用处。例如,如果没有给 MiniDumpWriteDump 设置 MiniDumpWithDataSegs 标志,MiniDumpWriteDump 函数就不会给任何模块设置 ModuleWriteDataSeg 标志。进一步,即使回调函数设置一个模块的 ModuleWriteDataSeg 标志,minidump 中也不会真的包含模块数据段的内容。
在讨论很长时间 MINIDUMP_CALLBACK_OUTPUT 结构体之后,我们回头来看 MINIDUMP_CALLBACK_INPUT 结构体。这时候,这个联合会被解析成 MINIDUMP_MODULE_CALLBACK 结构体 (Figure 12)。它里面包括了关于模块的丰富的信息,例如,名称和路径、大小、版本信息。
Figure 12:
typedef struct _MINIDUMP_MODULE_CALLBACK {
PWCHAR FullPath;
ULONG64 BaseOfImage;
ULONG SizeOfImage;
ULONG CheckSum;
ULONG TimeDateStamp;
VS_FIXEDFILEINFO VersionInfo;
PVOID CvRecord;
ULONG SizeOfCvRecord;
PVOID MiscRecord;
ULONG SizeOfMiscRecord;
} MINIDUMP_MODULE_CALLBACK, *PMINIDUMP_MODULE_CALLBACK;IncludeThreadCallback
这个回调类型对于对于线程的作用,和 IncludeModuleCallback 对于模块的作用一样。这给我们一个机会来决定一个线程的哪些信息需要保存到 minidump 中。就像 IncludeModuleCallback,回调函数返回 TRUE 表示要把线程信息保存到 mindump,返回 FASLE 表示完全放弃这些信息。可以通过存储在 MINIDUMP_CALLBACK_INPUT 的 ID 来区分线程。
typedef struct _MINIDUMP_INCLUDE_THREAD_CALLBACK {
ULONG ThreadId;
} MINIDUMP_INCLUDE_THREAD_CALLBACK, *PMINIDUMP_INCLUDE_THREAD_CALLBACK;
MINIDUMP_CALLBACK_OUTPUT structure is not used.ThreadCallback
这个回调类型的目的和 ModuleCallback 对于模块的作用一样。回调类型的基本原则也一样。MINIDUMP_CALLBACK_OUTPUT 中的联合包括了一系列的标志 (ThreadWriteFlags),回调函数可以清除部分或者全部标记,来从 minidump 清除相应的线程信息。
MINIDUMP_CALLBACK_INPUT 提供了很多种关于线程的信息。这里面的联合可以解释成 MINIDUMP_THREAD_CALLBACK (Figure 13)。包括了线程 ID 和句柄、线程上下文、线程栈的边界。为了保证 MiniDumpWriteDump 继续运行,回调函数必须返回 TRUE.
Figure 13:
typedef struct _MINIDUMP_THREAD_CALLBACK {
ULONG ThreadId;
HANDLE ThreadHandle;
CONTEXT Context;
ULONG SizeOfContext;
ULONG64 StackBase;
ULONG64 StackEnd;
} MINIDUMP_THREAD_CALLBACK, *PMINIDUMP_THREAD_CALLBACK;Figure 14 种表格列出了所有常用标志,以及他们所代表的信息。
Figure 14:
| Flag | Description |
|---|---|
| ThreadWriteThread | 通过这个标志可以从 minidump 中清除一个线程的所有信息。如果回调函数清除了这个标志,所有其他的标志都会被忽略。Minidump 就不保存任何关于这个线程的信息了。 通常,这个标志总是被设置的。 |
| ThreadWriteStack | 这个标志允许从 minidump 中清除线程栈的内容。因此,如果回调函数清除了这个标志,调试器就没办法看到线程的调用栈了。线程栈通常有几 KB ,极少数情况可以达到几 MB。因此这个标志会影响 minidump 的大小。 通常,这个标志总是被设置的。 |
| ThreadWriteContext | 通过这个标志可以清除线程上下文的内容 (定义在 winnt.h 中的 CONTEXT 结构体)。如果回调清除了这个标志,调试器就不能看到线程上下文和调用栈,所有寄存器会被置成 0。 通常线程上下文不会占据很大的 minidump 空间 (X86 环境下是 716 字节),因此对于 minidump 大小的影响很小。 通常,这个标志总是被设置的。 |
| ThreadWriteInstructionWindow | 通过这个标志可以清除线程指令窗口(当前执行指针附近的 256 字节)。如果清除这个标志,就没有办法直接看到出故障时的反汇编代码。如果想看到,就必须在开发者的计算机上装载相应的模块。 |
| ThreadWriteThreadInfo | 只有给 MiniDumpWriteDump 传递了 MiniDumpWithThreadInfo 参数时,这个标志才被设置。通过这个标志,可以清除 minidump 中的额外线程信息。(参考本文中关于 MiniDumpWithThreadInfo 的解释) |
| ThreadWriteThreadData | 只有给 MiniDumpWriteDump 传递了 MiniDumpWithProcessThreadData 参数时,这个标志才被设置。通过这个标志可以从 minidump 中清除线程的特别信息(TEB 的内容、TLS 存储和一些附加信息) |
MemoryCallback
有些时候,我们肯能希望在 minidump 中添加一些额外内存区域的内容。例如,我们可能在堆上分配了一些数据 (也可能是通过 VirtualAlloc),希望在调试 minidump 的时候能够看到这些数据。我们可以通过 MemoryCallback 来完成这个功能。MiniDumpWriteDump 会在通过回调调用处理完线程和模块之后调用这个回调函数。
当使用 MemoryCallback 作为回调函数的回调参数时,MINIDUMP_CALLBACK_OUTPUT 中的联合会被解析成:
struct { ULONG64 MemoryBase; ULONG MemorySize;};如果回调函数在这个结构体中写入可读内存块的资质和大小,并且返回 TRUE,这个内存块的内容就会被放到 minidump 中。我们可以添加多个内存块。当回调函数返回 TRUE 的时候,这个回调会被再次调用。MiniDumpWriteDump 会一直等到返回 FALSE 才停止调用这个回调函数。
CancelCallback
MiniDumpWriteDump 会定期调用这个回调类型。这个回调类型允许终止创建 minidump 的过程,这对于 GUI 应用程序很有用。MINIDUMP_CALLBACK_OUTPUT 结构体被解析成两个值,Cancel 和 CheckCancel:
struct {
BOOL CheckCancel;
BOOL Cancel;
};如果我们希望彻底取消创建 minidump,我们应该把 Cancel 设成 TRUE。如果我们不想取消 minidump,而只是不想再接收 CancelCallback 的回调,就把 CheckCancel 设成 TRUE。如果两个成员都设置成 FALSE,MiniDumpWriteDump 就不再使用 CancelCallback 调用回调函数。
回调函数应该返回 TRUE 来确认 MINIDUMP_CALLBACK_OUTPUT 的值被设置了。
回调的顺序
在讨论完回调的类型之后,我们可能会关心这些回调类型的顺序。调用的顺序如下:
- IncludeThreadCallback – 进程中的每一个线程一次
- IncludeModuleCallback –进程中每一个可执行模块一次
- ModuleCallback – 没有被 IncludeModuleCallback 排除的模块,每个调用一次
- ThreadCallback –没有被 IncludeThreadCallback 排除的线程,每个调用一次
- MemoryCallback 会调用一次或者多次,一直到回调函数返回 FALSE
另外,CancelCallback 会在其他回调类型之间定期调用。这样,保证在需要的时候可以中断 minidump 的创建过程。
这个例子程序(http://www.debuginfo.com/examples/src/effminidumps/CallbackOrder.cpp)会显示实际的调用顺序。你也可以使用 MiniDump Wizard 来测试各种回调 (http://www.debuginfo.com/tools/minidumpwizard.html)。
MiniDump Wizard
你可以使用 MiniDump Wizard 来试验各种 minidump 的选项并且看到他们会怎么影响 minidump 的大小和内容。MiniDump Wizard 可以创建任意进程的 minidump。它也可以模拟异常来创建自己的 mindump 文件。你可以选择把哪些类型标志 传递给 MiniDumpWriteDump ,然后通过一系列的对话框对回调请求做出响应。
当创建完 minidump,可以在一个调试器中装载它,然后查看包括了哪些信息。也可以使用 MinDumpView(http://www.debuginfo.com/tools/minidumpview.html) 应用来得到 minidump 中内容的清单。
4. 用户数据流
除了 MiniDumpWriteDump 已经捕获的成功调试需要的所有应用程序状态之外,我们经常需要程序运行环境的一些额外信息。例如,如果可以查看配置文件的内容或者应用程序相关的注册表设置会很有帮助。Minidump 允许把这些信息作为额外数据流添加进来。
这个例子程序显示了如何做到这一点(http://www.debuginfo.com/examples/src/effminidumps/WriteUserStream.cpp)。我们需要声明一个 MINIDUMP_USER_STREAM_INFORMATION 变量,在里面填充流的数量和用户数据流的指针数组。每个用户数据流用一个 MINIDUMP_USER_STREAM 结构体表示。结构体里面包括流的类型、大小、以及一个指向流数据的指针。流类型是识别流的一个唯一标志,必须是一个比 LastReservedStream 大的常数。
Figure 14:
typedef struct _MINIDUMP_USER_STREAM_INFORMATION {
ULONG UserStreamCount;
PMINIDUMP_USER_STREAM UserStreamArray;
} MINIDUMP_USER_STREAM_INFORMATION, *PMINIDUMP_USER_STREAM_INFORMATION;
typedef struct _MINIDUMP_USER_STREAM {
ULONG32 Type;
ULONG BufferSize;
PVOID Buffer;
} MINIDUMP_USER_STREAM, *PMINIDUMP_USER_STREAM;当我们向一个 minidump 添加了用户数据流,我们可以通过 MiniDumpReadDumpStream 函数来读出这些信息。这个例子程序 (http://www.debuginfo.com/examples/src/effminidumps/WriteUserStream.cpp) 显示了如何从前一个例子 (http://www.debuginfo.com/examples/src/effminidumps/WriteUserStream.cpp) 写入的例子数据。
5. 策略
MiniDumpWriteDump 有丰富功能和大量的可用选项。这使得找到一个所有应用都适用的策略会很困难。对于每一个特定的情况,应用程序的开发者必须决定哪些选项对他们的调试工作有用。在这我会试着描述一些基本策略,用来解释如何把 MiniDumpWriteDump 的配置选项应用到真实场景中。我们会看到四种不同的 MiniDumpWriteDump 收集数据的策略。并且来了解他们会对 minidump 的大小和调试的可能性发生什么影响。
TinyDump
这不是一个真实世界的场景。这个方法显示了怎么样来创建一个最小可能数据集的 minidump,来使它有一点用途。Figure 15 总结了这种 MiniDumpWriteDump 配置选项。
Figure 15:
| MINIDUMP_TYPE 标志 | MiniDumpNormal |
|---|---|
| MiniDumpCallback | IncludeThreadCallback – exclude all threads IncludeModuleCallback – exclude all modules |
实现这种方式的例子程序在这个地址 http://www.debuginfo.com/examples/src/effminidumps/TinyDump.cpp。
结果 minidump 非常小,在我的系统上非常小。并不令人惊讶,我们去掉了所有线程和模块的信息。如果你试着用 WinDbg or VS.NET debugger 来装载,你会发现调试器没有办法装载它。
但是,这个 minidump 还包含了异常的信息,所以不是完全无用,我们可以手工读取这些信息(使用 MiniDumpReadDumpStream 函数),可以看到异常发生的地址、异常时刻的线程上下文、异常代码甚至反汇编。你可以使用 MinDumpView 工具 (http://www.debuginfo.com/tools/minidumpview.html) 来查看其中的信息。为了保持工具简单,没有提供返汇编。
MiniDump
不像 TinyDump,这种方式对于真实世界场景是有用的。它收集了足够的调试信息同时又保持 minidump 足够小。Figure 16 中的表格描述了相应的 MiniDumpWriteDump 配置项。
Figure 16:
| MINIDUMP_TYPE | MiniDumpWithIndirectlyReferencedMemory, MiniDumpScanMemory |
|---|---|
| MiniDumpCallback | IncludeThreadCallback – 包括所有线程 IncludeModuleCallback – 包括所有模块 ThreadCallback – 包括所有线程 ModuleCallback – 检查 ModuleWriteFlags ,把所有 ModuleReferencedByMemory 没有设置的模块排除掉(清除这些模块的 ModuleWriteModule 标志) |
可以在这找到例子程序(http://www.debuginfo.com/examples/src/effminidumps/MiniDump.cpp)
结果的 mindump 文件仍然很小(在我的系统上大约 40-50KB)。他比 mindump 的标准方式(MiniDumpNormal + no MiniDumpCallback))包含了更多的信息量。他允许查看栈上的引用的数据。为了优化大小,我们把所有线程栈没有引用的模块从 minidump 中去掉了(在我的系统上,advapi32.dll 和 rpcrt4.dll 被去掉了)。
但是,这个 minidump 还缺少一些重要的信息。例如,我们看不到全局标量的值,不能查看堆和 TLS 中分配的数据(除非他们被线程栈引用了)。
MidiDump
下一个方式会产生一个信息量充足的 minidump,同时保证文件不会过大。Figure 17 的表格描述了配置。
Figure 17:
| MINIDUMP_TYPE flags | MiniDumpWithPrivateReadWriteMemory, MiniDumpWithDataSegs, MiniDumpWithHandleData, MiniDumpWithFullMemoryInfo, MiniDumpWithThreadInfo, MiniDumpWithUnloadedModules |
|---|---|
| MiniDumpCallback | IncludeThreadCallback –包括所有线程 IncludeModuleCallback – 包括所有模块 ThreadCallback – 包括所有线程 ModuleCallback – 只保留主模块和 ntdll.dll 的数据区 |
例子程序可以在这看到 (http://www.debuginfo.com/examples/src/effminidumps/MidiDump.cpp)。minidump 的大小在我的系统上大约 1350KB。当在调试器中装载的时候,我们可以得到应用程序的几乎所有信息,包括全局变量的值、堆和 TLS 的内容、PEB、TEB。我们甚至可以得到句柄信息以及虚拟内存布局。这是一个非常有用的 dump,并且不是很大。下面的信息没有包括在 mindump 中:
- 所有模块的代码区 (如果我们可以得到这些模块,就不需要他们)
- 某些模块的数据区 (我们只包括了我们希望看到全局变量的模块的数据区)
MaxiDump
最后一个例子显示了如何创建一个包含所有可能数据的 minidump。Figure 18 的表格显示了如何做到这一点。
Figure 18:
| MINIDUMP_TYPE flags | MiniDumpWithFullMemory, MiniDumpWithFullMemoryInfo, MiniDumpWithHandleData, MiniDumpWithThreadInfo, MiniDumpWithUnloadedModules |
|---|---|
| MiniDumpCallback | Not used |
例子程序可以在这找到 http://www.debuginfo.com/examples/src/effminidumps/MaxiDump.cpp。
这个 minidump 对于这样一个简单程序来说已经很大了(在我的系统上有 8MB)。但是,它给了我们在一个 mindump 中包含所有信息的可能。
对比
Figure 19 的表格比较和四种方式创建的 minidump 的大小。除了这个例子程序的数据之外 (它和真实程序会有一定差距),我还添加了一个真实程序的数据。同样也使用这四种不同的 minidump。
Figure 19:
| TinyDump | MiniDump | MidiDump | MaxiDump | |
|---|---|---|---|---|
| 例子程序 | 2 KB | 40-50 KB | 1,35 MB | 8 MB |
| 真实程序 | 2 KB | 200 KB | 14 MB | 35 MB |
6. 补充
关于 64 位系统
这篇文章没有讨论 MiniDumpWriteDump 中关于 64 位系统的选项。我的实验室里面没有 64 位的机器,我没有办法提供关于他们的更有效信息。
关于 DbgHelp 版本
DbgHelp.dll 一直在不断改进。新的特性会随着 Debugging Tools for Windows 工具包的新版本推出。在写这篇文章的时候,使用的版本是 DbgHelp.dll 6.3。
例子程序
这篇文上涉及的所有例子程序(包括编译指令)可以在这找到。(http://www.debuginfo.com/examples/effmdmpexamples.html)
联系方式
Have questions or comments? Free free to contact Oleg Starodumov at firstname@debuginfo.com.
这份文件翻译自
http://www.debuginfo.com/articles/effminidumps.html
http://www.debuginfo.com/articles/effminidumps2.html
[补充]
如果希望找到一个完整的实现,可以使用 XCrashReport
http://www.codeproject.com/Articles/5257/XCrashReport-Exception-Handling-and-Crash-Reportin
原文摘自 http://www.debuginfo.com/articles/effminidumps.html
本文转载自:https://blog.csdn.net/pkrobbie/article/details/6636310
https://blog.csdn.net/pkrobbie/article/details/6641081
1.2 OpenGL
OpenGL 的子部分
2.1 windows 上的OpenGL离屏渲染
本文由 简悦 SimpRead 转码, 原文地址 wiki.woodpecker.org.cn
呵呵,有了第一次的经验,我们就要开始我们的 GL 离屏渲染的绑定了。
呵呵,有了第一次的经验,我们就要开始我们的 GL 离屏渲染的绑定了。
关于 OpenGL 的离屏渲染,前面已经有一些涉及了。再说一下吧,OpenGL 有两种渲染方式:一种是通过操作系统打开窗口进行渲染,然后可以直接在屏幕上显示,这种渲染方式叫做屏幕渲染。一种通过在内存中一块位图区域内渲染,这种渲染方式在没有通过 SwapBuffer 方式前不可以在屏幕上显示,所以这种方法叫离屏渲染。一般来说,OpenGL 通过屏幕显示方式展示它的魅力,屏幕渲染方式是大多数情况下的首选。而且很多窗口系统都有实现 OpenGL 的屏幕渲染方式。比如 glut,wxwidgets,QT,gtk。但是有些时候我们不需要屏幕显示。只是想把它保存成一个图像文件就好。而且我们就是不想打开一个窗口。这样就需要用离屏渲染的方法。在内存中画,最后保存成图像。
可惜的是 OpenGL 没有统一的离屏渲染操作 API。GL 把这些事情全部交给系统。这样就导致各个系统的离屏渲染都有各自的 API,Windows,X,Apple,SGI,OS2 都有自己的离屏 RC 上下文构建方法,每套 API 都不同。在缺少了榜样的力量后,各个系统就纷纷开始诸侯割据了,就造成天下大乱的局势。这样确实不太好。不过现在乱了就让它乱吧,谁叫我们是 “小程序员”?天下大势就这样,你要怎么着吧 -_-! 没办法。实在是没办法~~~如今的世界太疯狂…… 如今的世界变化快……
我还是静下心来看看这么在各个系统上实现离屏渲染吧。OS2 大概八辈子用不到了吧,Apple 是高高在上的贵族们的东西。咱们老百姓…… 还是算了吧。老老实实研究一下 Windows 和 X 吧。于是先开始研究 WGL。
WGL 要建立离屏渲染,可以参看官方解释,不过太多,太乱了,红宝书中的解释比较浅显。这里也有两句解释(不过这里主要是 SIG 的解释,X 的解释也比较详细)。最令人激动的是这里有 win32 上的完整例子。
简单得说吧,要进行离屏渲染,win32 下需要做下面的几个步骤:
- 创建一个内存 DC
- 创建一个位图
- 把位图选入 DC
- 设置 DC 的像元格式
- 通过 DC 创建 OpenGL 的渲染上下文 RC
- 开始渲染.
好了,可用的渲染过程如下:
#include "stdafx.h"
#include <windows.h>
#include <iostream>
#include <commctrl.h>
#include <gl/gl.h>
#include <gl/glu.h>
#include <string>
using namespace std;
BOOL SaveBmp(HBITMAP hBitmap, string FileName)
{
HDC hDC;
//当前分辨率下每象素所占字节数
int iBits;
//位图中每象素所占字节数
WORD wBitCount;
//定义调色板大小, 位图中像素字节大小 ,位图文件大小 , 写入文件字节数
DWORD dwPaletteSize=0, dwBmBitsSize=0, dwDIBSize=0, dwWritten=0;
//位图属性结构
BITMAP Bitmap;
//位图文件头结构
BITMAPFILEHEADER bmfHdr;
//位图信息头结构
BITMAPINFOHEADER bi;
//指向位图信息头结构
LPBITMAPINFOHEADER lpbi;
//定义文件,分配内存句柄,调色板句柄
HANDLE fh, hDib, hPal,hOldPal=NULL;
//计算位图文件每个像素所占字节数
hDC = CreateDC("DISPLAY", NULL, NULL, NULL);
iBits = GetDeviceCaps(hDC, BITSPIXEL) * GetDeviceCaps(hDC, PLANES);
DeleteDC(hDC);
if (iBits <= 1) wBitCount = 1;
else if (iBits <= 4) wBitCount = 4;
else if (iBits <= 8) wBitCount = 8;
else wBitCount = 24;
GetObject(hBitmap, sizeof(Bitmap), (LPSTR)&Bitmap);
bi.biSize = sizeof(BITMAPINFOHEADER);
bi.biWidth = Bitmap.bmWidth;
bi.biHeight = Bitmap.bmHeight;
bi.biPlanes = 1;
bi.biBitCount = wBitCount;
bi.biCompression = BI_RGB;
bi.biSizeImage = 0;
bi.biXPelsPerMeter = 0;
bi.biYPelsPerMeter = 0;
bi.biClrImportant = 0;
bi.biClrUsed = 0;
dwBmBitsSize = ((Bitmap.bmWidth * wBitCount + 31) / 32) * 4 * Bitmap.bmHeight;
//为位图内容分配内存
hDib = GlobalAlloc(GHND,dwBmBitsSize + dwPaletteSize + sizeof(BITMAPINFOHEADER));
lpbi = (LPBITMAPINFOHEADER)GlobalLock(hDib);
*lpbi = bi;
// 处理调色板
hPal = GetStockObject(DEFAULT_PALETTE);
if (hPal)
{
hDC = ::GetDC(NULL);
hOldPal = ::SelectPalette(hDC, (HPALETTE)hPal, FALSE);
RealizePalette(hDC);
}
// 获取该调色板下新的像素值
GetDIBits(hDC, hBitmap, 0, (UINT) Bitmap.bmHeight, (LPSTR)lpbi + sizeof(BITMAPINFOHEADER)
+dwPaletteSize, (BITMAPINFO *)lpbi, DIB_RGB_COLORS);
//恢复调色板
if (hOldPal)
{
::SelectPalette(hDC, (HPALETTE)hOldPal, TRUE);
RealizePalette(hDC);
::ReleaseDC(NULL, hDC);
}
//创建位图文件
fh = CreateFile(FileName.c_str(), GENERIC_WRITE,0, NULL, CREATE_ALWAYS,
FILE_ATTRIBUTE_NORMAL | FILE_FLAG_SEQUENTIAL_SCAN, NULL);
if (fh == INVALID_HANDLE_VALUE) return FALSE;
// 设置位图文件头
bmfHdr.bfType = 0x4D42; // "BM"
dwDIBSize = sizeof(BITMAPFILEHEADER) + sizeof(BITMAPINFOHEADER) + dwPaletteSize + dwBmBitsSize;
bmfHdr.bfSize = dwDIBSize;
bmfHdr.bfReserved1 = 0;
bmfHdr.bfReserved2 = 0;
bmfHdr.bfOffBits = (DWORD)sizeof(BITMAPFILEHEADER) + (DWORD)sizeof(BITMAPINFOHEADER) + dwPaletteSize;
// 写入位图文件头
WriteFile(fh, (LPSTR)&bmfHdr, sizeof(BITMAPFILEHEADER), &dwWritten, NULL);
// 写入位图文件其余内容
WriteFile(fh, (LPSTR)lpbi, dwDIBSize, &dwWritten, NULL);
//清除
GlobalUnlock(hDib);
GlobalFree(hDib);
CloseHandle(fh);
return TRUE;
}
void mGLRender()
{
glClearColor(0.9f,0.9f,0.3f,1.0f);
glClear(GL_COLOR_BUFFER_BIT);
glMatrixMode(GL_PROJECTION);
gluPerspective(30.0, 1.0, 1.0, 10.0);
glMatrixMode(GL_MODELVIEW);
gluLookAt(0, 0, -5, 0, 0, 0, 0, 1, 0);
glBegin(GL_TRIANGLES);
glColor3d(1, 0, 0);
glVertex3d(0, 1, 0);
glColor3d(0, 1, 0);
glVertex3d(-1, -1, 0);
glColor3d(0, 0, 1);
glVertex3d(1, -1, 0);
glEnd();
glFlush(); // remember to flush GL output!
}
int _tmain(int argc, _TCHAR* argv[])
{
const int WIDTH = 500;
const int HEIGHT = 500;
// Create a memory DC compatible with the screen
HDC hdc = CreateCompatibleDC(0);
if (hdc == 0) cout<<"Could not create memory device context";
// Create a bitmap compatible with the DC
// must use CreateDIBSection(), and this means all pixel ops must be synchronised
// using calls to GdiFlush() (see CreateDIBSection() docs)
BITMAPINFO bmi = {
{ sizeof(BITMAPINFOHEADER), WIDTH, HEIGHT, 1, 32, BI_RGB, 0, 0, 0, 0, 0 },
{ 0 }
};
DWORD *pbits; // pointer to bitmap bits
HBITMAP hbm = CreateDIBSection(hdc, &bmi, DIB_RGB_COLORS, (void **) &pbits,
0, 0);
if (hbm == 0) cout<<"Could not create bitmap";
//HDC hdcScreen = GetDC(0);
//HBITMAP hbm = CreateCompatibleBitmap(hdcScreen,WIDTH,HEIGHT);
// Select the bitmap into the DC
HGDIOBJ r = SelectObject(hdc, hbm);
if (r == 0) cout<<"Could not select bitmap into DC";
// Choose the pixel format
PIXELFORMATDESCRIPTOR pfd = {
sizeof (PIXELFORMATDESCRIPTOR), // struct size
1, // Version number
PFD_DRAW_TO_BITMAP | PFD_SUPPORT_OPENGL, // use OpenGL drawing to BM
PFD_TYPE_RGBA, // RGBA pixel values
32, // color bits
0, 0, 0, // RGB bits shift sizes...
0, 0, 0, // Don't care about them
0, 0, // No alpha buffer info
0, 0, 0, 0, 0, // No accumulation buffer
32, // depth buffer bits
0, // No stencil buffer
0, // No auxiliary buffers
PFD_MAIN_PLANE, // Layer type
0, // Reserved (must be 0)
0, // No layer mask
0, // No visible mask
0 // No damage mask
};
int pfid = ChoosePixelFormat(hdc, &pfd);
if (pfid == 0) cout<<"Pixel format selection failed";
// Set the pixel format
// - must be done *after* the bitmap is selected into DC
BOOL b = SetPixelFormat(hdc, pfid, &pfd);
if (!b) cout<<"Pixel format set failed";
// Create the OpenGL resource context (RC) and make it current to the thread
HGLRC hglrc = wglCreateContext(hdc);
if (hglrc == 0) cout<<"OpenGL resource context creation failed";
wglMakeCurrent(hdc, hglrc);
// Draw using GL - remember to sync with GdiFlush()
GdiFlush();
mGLRender();
SaveBmp(hbm,"output.bmp");
/*
Examining the bitmap bits (pbits) at this point with a debugger will reveal
that the colored triangle has been drawn.
*/
// Clean up
wglDeleteContext(hglrc); // Delete RC
SelectObject(hdc, r); // Remove bitmap from DC
DeleteObject(hbm); // Delete bitmap
DeleteDC(hdc); // Delete DC
return 0;
}好了,编译成功,运行,确实是可以啊!看看步骤是什么样的:
CreateCompatibleDC | 创建 dc |
CreateDIBSection | 创建图像 |
SelectObject | 图像选入 DC |
SetPixelFormat | 设置像元格式 |
wglCreateContext | 创建 RC |
wglMakeCurrent | 选择 RC |
mGLRender | 开始渲染 |
SaveBmp | 保存图像(这段是我从网上随便摘下来的) |
... | 清理 |
好的,既然 C++ 可以,那么 Python……
等等,Python 好像不行!
单单是 OpenGL 的世界乱了,也就算了,偏偏 Python 也来凑热闹。PyWin32 里我死活找不到 CreateDIBSection。好吧,PyWin32 找不到,那么我还有 PIL。里面有个 ImageWin.Dib,我试过,不行。总是在 SetPixelFormat 中出现问题。后来我把 CreateDIBSection 的部分整个注释掉改成类似:
HDC hdcScreen = GetDC(0);
HBITMAP hbm = CreateCompatibleBitmap(hdcScreen,WIDTH,HEIGHT);的代码。当然这是 C++ 的改动,python 改动也类似。因为这两个函数 PyWin32 里有,现在通过了。并且运行到了 wglCreateContext 的步骤。等等,提示空间不够?什么空间不够?我在 C++ 中都运行好好的。对比两个语言的两段代码,完全一样的步骤,居然一个可以一个就是不行!发个邮件给 pyopengl 的邮件列表吧,几天没回应…… 真的晕了。
大概可能是我不懂怎么玩 PyWin32 或者 PyOpenGL,或者 PIL 的 Dib 类我用得不对,但是我在泡了三天的 google 后,我放弃了。与其在这个问题上拖延时间,不如另辟蹊径。(如果你成功得在 Python 下离屏渲染了,一定要告诉我哦!)
既然 C++ 可以,为什么不用 C++ 来做?然后用 Swig 来绑定?不就是创建一个环境吗?我在 C++ 中创建好,然后在 Python 中渲染,然后在 C++ 中关闭环境。反正环境在哪里不是一样创建!
现在我的思路就定下来,用 C++ 写两个函数,用来创建离屏 RC 环境和关闭环境。名字就叫 StartBmpContext 和 EndBmpContext。
创建一个工程。叫 glBmpContext。然后做一些什么取消 stdafx,清空等善前工作。然后写入内容。
#include <windows.h>
#include <iostream>
#include <commctrl.h>
#include <gl/gl.h>
#include <gl/glu.h>
using namespace std;
static HDC hdc;
static HBITMAP hbm;
static HGDIOBJ r;
static HGLRC hglrc;
static DWORD *pbits;// pointer to bitmap bits
static int WIDTH = 120;
static int HEIGHT = 90;
__declspec(dllexport) void StartBmpContext(int width,int height)
{
WIDTH = width;
HEIGHT = height;
// Create a memory DC compatible with the screen
hdc = CreateCompatibleDC(0);
if (hdc == 0) cout<<"Could not create memory device context";
// Create a bitmap compatible with the DC
// must use CreateDIBSection(), and this means all pixel ops must be synchronised
// using calls to GdiFlush() (see CreateDIBSection() docs)
BITMAPINFO bmi = {
{ sizeof(BITMAPINFOHEADER), WIDTH, HEIGHT, 1, 32, BI_RGB, 0, 0, 0, 0, 0 },
{ 0 }
};
hbm = CreateDIBSection(hdc, &bmi, DIB_RGB_COLORS, (void **) &pbits,
0, 0);
/*HBITMAP hbm = CreateCompatibleBitmap(hdc,WIDTH,HEIGHT);*/
if (hbm == 0) cout<<"Could not create bitmap";
// Select the bitmap into the DC
r = SelectObject(hdc, hbm);
if (r == 0) cout<<"Could not select bitmap into DC";
// Choose the pixel format
PIXELFORMATDESCRIPTOR pfd = {
sizeof (PIXELFORMATDESCRIPTOR), // struct size
1, // Version number
PFD_DRAW_TO_BITMAP | PFD_SUPPORT_OPENGL, // use OpenGL drawing to BM
PFD_TYPE_RGBA, // RGBA pixel values
32, // color bits
0, 0, 0, // RGB bits shift sizes...
0, 0, 0, // Don't care about them
0, 0, // No alpha buffer info
0, 0, 0, 0, 0, // No accumulation buffer
32, // depth buffer bits
0, // No stencil buffer
0, // No auxiliary buffers
PFD_MAIN_PLANE, // Layer type
0, // Reserved (must be 0)
0, // No layer mask
0, // No visible mask
0 // No damage mask
};
int pfid = ChoosePixelFormat(hdc, &pfd);
cout<<pfid<<endl;
if (pfid == 0) cout<<"Pixel format selection failed";
// Set the pixel format
// - must be done *after* the bitmap is selected into DC
BOOL b = SetPixelFormat(hdc, pfid, &pfd);
if (!b) cout<<"Pixel format set failed";
// Create the OpenGL resource context (RC) and make it current to the thread
hglrc = wglCreateContext(hdc);
if (hglrc == 0) cout<<"OpenGL resource context creation failed";
wglMakeCurrent(hdc, hglrc);
}
int SaveBmp(HBITMAP hBitmap, char* FileName)
{
HDC hDC;
//当前分辨率下每象素所占字节数
int iBits;
//位图中每象素所占字节数
WORD wBitCount;
//定义调色板大小, 位图中像素字节大小 ,位图文件大小 , 写入文件字节数
DWORD dwPaletteSize=0, dwBmBitsSize=0, dwDIBSize=0, dwWritten=0;
//位图属性结构
BITMAP Bitmap;
//位图文件头结构
BITMAPFILEHEADER bmfHdr;
//位图信息头结构
BITMAPINFOHEADER bi;
//指向位图信息头结构
LPBITMAPINFOHEADER lpbi;
//定义文件,分配内存句柄,调色板句柄
HANDLE fh, hDib, hPal,hOldPal=NULL;
//计算位图文件每个像素所占字节数
hDC = CreateDC("DISPLAY", NULL, NULL, NULL);
iBits = GetDeviceCaps(hDC, BITSPIXEL) * GetDeviceCaps(hDC, PLANES);
DeleteDC(hDC);
if (iBits <= 1) wBitCount = 1;
else if (iBits <= 4) wBitCount = 4;
else if (iBits <= 8) wBitCount = 8;
else wBitCount = 24;
GetObject(hBitmap, sizeof(Bitmap), (LPSTR)&Bitmap);
bi.biSize = sizeof(BITMAPINFOHEADER);
bi.biWidth = Bitmap.bmWidth;
bi.biHeight = Bitmap.bmHeight;
bi.biPlanes = 1;
bi.biBitCount = wBitCount;
bi.biCompression = BI_RGB;
bi.biSizeImage = 0;
bi.biXPelsPerMeter = 0;
bi.biYPelsPerMeter = 0;
bi.biClrImportant = 0;
bi.biClrUsed = 0;
dwBmBitsSize = ((Bitmap.bmWidth * wBitCount + 31) / 32) * 4 * Bitmap.bmHeight;
//为位图内容分配内存
hDib = GlobalAlloc(GHND,dwBmBitsSize + dwPaletteSize + sizeof(BITMAPINFOHEADER));
lpbi = (LPBITMAPINFOHEADER)GlobalLock(hDib);
*lpbi = bi;
// 处理调色板
hPal = GetStockObject(DEFAULT_PALETTE);
if (hPal)
{
hDC = ::GetDC(NULL);
hOldPal = ::SelectPalette(hDC, (HPALETTE)hPal, FALSE);
RealizePalette(hDC);
}
// 获取该调色板下新的像素值
GetDIBits(hDC, hBitmap, 0, (UINT) Bitmap.bmHeight, (LPSTR)lpbi + sizeof(BITMAPINFOHEADER)
+dwPaletteSize, (BITMAPINFO *)lpbi, DIB_RGB_COLORS);
//恢复调色板
if (hOldPal)
{
::SelectPalette(hDC, (HPALETTE)hOldPal, TRUE);
RealizePalette(hDC);
::ReleaseDC(NULL, hDC);
}
//创建位图文件
fh = CreateFile(FileName, GENERIC_WRITE,0, NULL, CREATE_ALWAYS,
FILE_ATTRIBUTE_NORMAL | FILE_FLAG_SEQUENTIAL_SCAN, NULL);
if (fh == INVALID_HANDLE_VALUE) return 1;
// 设置位图文件头
bmfHdr.bfType = 0x4D42; // "BM"
dwDIBSize = sizeof(BITMAPFILEHEADER) + sizeof(BITMAPINFOHEADER) + dwPaletteSize + dwBmBitsSize;
bmfHdr.bfSize = dwDIBSize;
bmfHdr.bfReserved1 = 0;
bmfHdr.bfReserved2 = 0;
bmfHdr.bfOffBits = (DWORD)sizeof(BITMAPFILEHEADER) + (DWORD)sizeof(BITMAPINFOHEADER) + dwPaletteSize;
// 写入位图文件头
WriteFile(fh, (LPSTR)&bmfHdr, sizeof(BITMAPFILEHEADER), &dwWritten, NULL);
// 写入位图文件其余内容
WriteFile(fh, (LPSTR)lpbi, dwDIBSize, &dwWritten, NULL);
//清除
GlobalUnlock(hDib);
GlobalFree(hDib);
CloseHandle(fh);
return 0;
}
__declspec(dllexport) int SaveBmp(char* FileName)
{
return SaveBmp(hbm,FileName);
}
__declspec(dllexport) int GetWidth()
{
return WIDTH;
}
__declspec(dllexport) int GetHeight()
{
return HEIGHT;
}
__declspec(dllexport) void GetMemBmpData(char **s,int *slen)
{
*s = (char*)pbits;
*slen = WIDTH*HEIGHT*4;
}
__declspec(dllexport) void EndBmpContext()
{
// Clean up
wglDeleteContext(hglrc); // Delete RC
SelectObject(hdc, r); // Remove bitmap from DC
DeleteObject(hbm); // Delete bitmap
DeleteDC(hdc); // Delete DC
}其实这里做得事情也就是这样,把前面那段 C++ 代码拆开,把开始渲染前和渲染结束后两个部分单独拆出来,放到 Start 和 End 两个函数里。为了能在最后做清理工作,把一些句柄做成全程静态变量。提到开头而已。
等一下,多了很多函数。
是的。这里多了 SaveBmp,这个是为了测试数据的正确性。用 vc 的方法保存 bmp 图像。但是我并不想在 vc 中保存图像。太麻烦了。我们有 PIL 啊!保存只要一句的 PIL 啊~~~~~所以我需要有个函数读取 bmp 图像的信息。所以我添加了个 GetMemBmpData 函数。用于获取图像数据的二进制表示。当然,渲染图像大小不可以定死,所以我暴露了获取图像大小的函数,并在初始化环境的时候用两个参数定义宽高。
好了,编译,链接,成功。(需要说明的是,这里的 GetMemBmpData 的参数很奇怪,这是因为要返回二进制时 Swig 的特殊要求决定的)
我们现在有了 C++ 的库了。
好,开始定义 glBmpContext.i,这是重点!
%module glBmpContext
%include "cstring.i"
%cstring_output_allocate_size(char **s, int *slen, free(*$1));
%{
#include <windows.h>
#include <iostream>
#include <commctrl.h>
#include <gl/gl.h>
#include <gl/glu.h>
using namespace std;
void StartBmpContext(int w,int h);
int SaveBmp( char* FileName );
void GetMemBmpData(char **s,int *slen);
void EndBmpContext();
int GetWidth();
int GetHeight();
%}
void StartBmpContext(int w,int h);
int SaveBmp( char* FileName );
void GetMemBmpData(char **s,int *slen);
void EndBmpContext();
int GetWidth();
int GetHeight();首先,我们定义模块名称,然后引入一个叫 cstring 的 swig 预定义模块,以及定义一种返回值形式。引入这个模块是因为我们需要在 GetMemBmpData 中返回图像格式的二进制形式给 Python,然后通过 PIL.Image 的 fromstring 函数转化成图像并可以用 save 保存。
Python 中不单单是 int,double,这样的简单类型。一些如数组,指针,字典,等等就比较麻烦了。Swig 定义了很多预定义的模块来处理这些东西。通过 %include 来定义这些数据格式和操作。这才是从 C++ 到 Python 的恶梦。也是 swig 最核心的东西。这些东西是很多的,需要我们慢慢去掌握。
先掌握两个。一个是字符串。在 Python 中字符串是一个很强大的东西,但在 swig 定义中却看起来不是那么强大。因为它被定义成 c 的字符串形式。一个 char* !不错,是 char*。看 SaveBmp 的参数,是一个 char*。这就是 Python 中的字符串!在 Python 中调用就像这样:
SaveBmp(“f:/image/img.bmp”)
好了,再看一个,返回一个二进制数据对象!这个比较复杂,可以看这个,这个解释十分详细。还有好几种类型。我们用的是最后那个。因为 C++/C 不比 Python,可以返回一个列表,它只能返回一个东西。所以在 Python 绑定定义中要用参数来代替返回。
还有更多的东西可以看这里。
函数定义像这样:
void foo(char **s, int *sz) {
*s = (char *) malloc(64);
*sz = 64;
// Write some binary data
...
}在 swig 定义. i 文件中就要这样写:
%cstring_output_allocate_size(char **s, int *slen, free(*$1));
...
void foo(char **s, int *slen);在 Python 中就要这样调:
>>> foo()
'\xa9Y:\xf6\xd7\xe1\x87\xdbH;y\x97\x7f\xd3\x99\x14V\xec\x06\xea\xa2\x88'
>>>呵呵,很奇妙吧!
我也是第一次看到这种做法!
其他应该都看得懂了。
好了,现在我们定义 setup.py:
from distutils.core import setup,Extension
include_dirs = []
libraries = ['glBmpContextD','opengl32','glu32']
library_dirs = ['./glBmpContext/']
extra_link_args = []
glBmpContext_module = Extension('_glBmpContext',
sources = ['glBmpContext_wrap.cpp'],
include_dirs = include_dirs,
libraries = libraries,
library_dirs = library_dirs,
extra_link_args = extra_link_args,
)
setup(name='glBmpContext wrapper',
version='1.0',
py_modules=["glBmpContext"],
ext_modules=[glBmpContext_module],
)这个和前一个例子很像。特别注意的是 Libraries,这里放了 opengl32 和 glu32 是为了能链接通过。
好了,写个脚本来运行 swig 和编译。
@echo off
swig -c++ -python -modern -new_repr -I. -o glBmpContext_wrap.cpp glBmpContext.i
python.exe setup.py build
copy .\build\lib.win32-2.4\*.* .\bin\
pause好了,运行编译通过后就可以了。这个脚本还把生成的 pyd 拷贝到 bin 目录下。
好了,在 bin 目录下建立一个测试脚本
import _glBmpContext
from OpenGL.GL import *
from OpenGL.GLU import *
from Numeric import *
import Image
w = 500
h = 400
_glBmpContext.StartBmpContext(w,h)
glMatrixMode(GL_PROJECTION);
gluPerspective(30.0, w*1.0/h, 1.0, 10.0);
glMatrixMode(GL_MODELVIEW);
gluLookAt(0, 0, -5, 0, 0, 0, 0, 1, 0);
glBegin(GL_TRIANGLES);
glColor3d(1, 0, 0);
glVertex3d(0, 1, 0);
glColor3d(0, 1, 0);
glVertex3d(-1, -1, 0);
glColor3d(0, 0, 1);
glVertex3d(1, -1, 0);
glEnd();
glFlush();
data = _glBmpContext.GetMemBmpData()
#print len(data),type(data)
w = _glBmpContext.GetWidth()
h = _glBmpContext.GetHeight()
arr = fromstring(data,Int8)
arr.shape = (-1,4)
arr = arr[:,0:3]
print arr.shape
img = Image.fromstring("RGB",(w,h),arr.tostring()).transpose(Image.FLIP_TOP_BOTTOM) \
.save("../tt.png","png")
_glBmpContext.SaveBmp("hehe.bmp")
_glBmpContext.EndBmpContext()运行,嗯,一切尽在掌握中。我的目的实现了!可以在 StartBmpContext 后尽情渲染,然后 GetMemBmpData 获得数据,然后用 Image 操作数据保存成各种图片。最后 EndBmpContext 关闭环境。
这里需要注意的是内存中的 HBITMAP 存储的图像是倒着的。要在 Image 中执行 transpose(Image.FLIP_TOP_BOTTOM) 把它转回来。
当然这样做很不安全。可能被恶意地重复创建环境,并且一旦出错,环境就没法释放。可以把_glBmpContext 的东西包装成类,销毁的时候自动释放。
8 demo
目录
demo 的子部分
8.1 异步支持方案
功能示意图
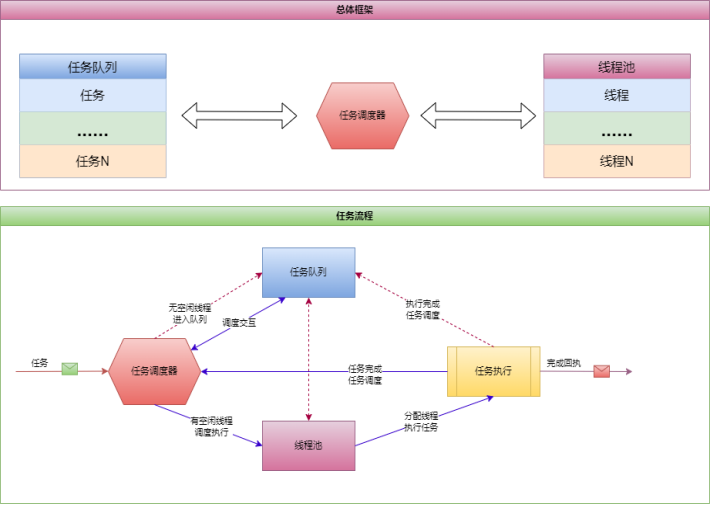
总体框架
线程池是一种可重用线程池,用于执行一系列的任务,而不需要创建和销毁新的线程。异步方案可采用线程池技术,可以将线程池的线程用于执行非阻塞任务,这些任务不需要等待当前线程完成。这种技术可以提高系统的并发性和性能。
线程池的总体框架由三部分组成:任务队列、线程池、任务调度器。
- 任务队列是线程池的核心组成部分,它用于存储和管理任务。任务队列的大小和类型决定了线程池的规模和性能。
- 线程池是任务队列的执行者,它用于执行任务队列中的任务。线程池的大小和类型决定了任务队列的大小和性能。
- 任务调度器是线程池的管理者,它用于控制任务的执行顺序和优先级。任务调度器可以根据任务的优先级和状态来安排线程池中的线程执行任务,从而提高任务的执行效率和并发性。
线程池的总体框架中,任务队列是核心组成部分,它直接决定了线程池的性能和规模。任务队列的大小和类型应该根据实际情况进行选择,以保证线程池的性能和可扩展性。
线程池的大小和类型也应该根据实际情况进行选择,以保证任务队列的大小和性能。任务调度器是线程池的管理者,它应该根据实际情况进行选择,以保证任务的执行顺序和优先级。
线程池的总体框架是一个复杂的系统,需要仔细地设计和实现。在设计和实现线程池时,需要充分考虑各个组成部分之间的关系和依赖性,以保证系统的稳定性和可靠性。
任务调度
任务调度是线程池的核心组成部分之一,它用于控制任务的执行顺序和优先级。任务调度的思想算法通常分为两种:先进先出(FIFO)和优先级调度。
先进先出(FIFO)是最简单的任务调度算法之一,它的思想是按照任务提交的顺序依次执行任务。具体来说,线程池中的任务按照顺序进入任务队列,然后按照顺序从任务队列中取出任务进行执行。先进先出的任务调度算法可以保证每个任务都有机会被执行,但是它无法根据任务的优先级来安排任务的执行顺序,可能会导致低优先级的任务长时间被阻塞,从而影响系统的性能和并发性。
优先级调度是一种更加高效的任务调度算法,它的思想是根据任务的优先级来安排任务的执行顺序。具体来说,线程池中的任务可以被标记为高、中、低三种优先级,然后根据任务的优先级来安排任务的执行顺序。高优先级的任务优先执行,低优先级的任务后执行。优先级调度可以保证高优先级的任务得到更快的执行,从而提高系统的性能和并发性。但是,优先级调度算法也存在一些问题,例如高优先级的任务可能会导致线程池的占用率过高,从而影响系统的性能和稳定性。
因此,在实际应用中,任务调度算法的选择应该根据具体的场景和需求来确定。如果任务的执行顺序对系统的性能和并发性影响较大,可以选择优先级调度算法。如果任务的执行顺序对系统的性能和并发性影响较小,可以选择先进先出的任务调度算法。同时,需要注意任务的优先级应该合理设置,以避免任务之间的冲突和竞争。
优先级调度算法
优先级调度算法是一种根据任务的优先级来安排任务的执行顺序的任务调度算法。
在实际应用中,可以使用一个优先级队列来存储任务,并使用一个优先级栈来存储任务的优先级。
- 任务进入任务队列时,将任务的优先级加入到优先级队列中。
- 线程空闲时,从优先级队列中取出优先级最高的任务,并将其执行。
- 执行完任务后,将任务的优先级从优先级栈中移除,以便在后续的执行中,其他任务可以优先执行。
优先级方案
通常分为两种:
硬编码优先级:硬编码优先级是最简单的优先级确定方案之一,它将任务的优先级直接硬编码在代码中。例如,可以将低优先级的任务的优先级设置为1,中优先级的任务的优先级设置为2,高优先级的任务的优先级设置为3。这种方案的优点是实现简单,易于理解和调试。但是,缺点是当任务数量增多时,需要频繁地修改硬编码的优先级,不够灵活。
动态调整优先级:动态调整优先级是一种更加灵活的优先级确定方案,它可以根据任务的具体需求来动态调整任务的优先级。例如,可以根据任务的重要性、紧急程度、完成时间等因素来确定任务的优先级。这种方案的优点是灵活性强,可以根据具体的需求来动态调整任务的优先级。但是,缺点是需要更多的计算和调试工作,实现起来相对复杂。
在实际应用中,可以根据具体的需求和场景来选择合适的优先级确定方案。
如果任务的优先级比较明确,可以选择硬编码优先级的方案。
如果任务的优先级比较复杂,可以选择动态调整优先级的方案。
同时,需要注意在动态调整优先级时,需要保证优先级的分配合理,避免出现优先级冲突和竞争的问题。
动态调整优先级
动态调整优先级是一种更加灵活的优先级确定方案,它可以根据任务的具体需求来动态调整任务的优先级。
以下是一些常见的动态调整优先级的方案:
优先级堆:优先级堆是一种常见的动态调整优先级的方案。在优先级堆中,任务被赋予一个优先级值,并按照优先级从高到低排序。线程池中的线程从优先级堆中取出优先级最高的任务进行执行。如果有多个任务具有相同的优先级,可以根据任务的创建时间或执行时间等因素来确定优先级。
贪心算法:贪心算法是一种常见的动态调整优先级的方案。在贪心算法中,每次从任务队列中取出一个任务进行执行,并根据任务的状态来更新任务的优先级。如果任务已经完成,可以将其优先级降低;如果任务还未完成,可以将其优先级升高。这种方案的优点是实现简单,易于理解和调试。但是,缺点是可能会导致低优先级的任务长时间被阻塞,从而影响系统的性能和并发性。
模拟器算法:模拟器算法是一种常见的动态调整优先级的方案。在模拟器算法中,任务被赋予一个优先级值,并按照优先级从高到低排序。线程池中的线程从任务队列中取出优先级最高的任务进行执行。如果有多个任务具有相同的优先级,可以根据任务的状态来确定优先级。在模拟器算法中,需要维护一个状态表,记录任务的状态和优先级。每次执行任务时,根据任务的状态更新任务的优先级。
推荐方案
基于优先级和等待时长的方案是一种常见的动态调整优先级的方案。
在这种方案中,任务被赋予一个优先级值和一个等待时长值,并按照优先级从高到低排序。线程池中的线程从任务队列中取出优先级最高的任务进行执行。
如果有多个任务具有相同的优先级,可以根据等待时长来确定优先级。
具体来说,可以定义一个等待时长值,表示任务等待执行的时间长度。在任务进入任务队列时,将其优先级和等待时长值加入到任务的信息中。
当线程池中的线程空闲时,从任务队列中取出优先级最高的任务进行执行。执行完任务后,将任务的信息从任务队列中移除。
如果任务等待的时间超过了其等待时长值,可以将其优先级降低。这样可以保证优先级较高的任务尽快得到执行,并且可以减少等待时间长的任务对系统的影响。
需要注意的是,在实际应用中,等待时长值的设置需要根据具体的场景和需求来确定。
等待时长值过小可能会导致任务执行时间不够准确,等待时长值过大可能会导致任务无法及时得到执行。
因此,在设置等待时长值时,需要进行充分的测试和评估,以保证系统的稳定性和性能。
案列代码
#include <pthread.h>
#include <cstdint>
#include <list>
#include <memory>
#include <atomic>
#include <unistd.h>
//--------------------模型抽象----------------------
// 任务基类
struct ITask
{
// 任务处理入口
virtual void handling() {}
ITask() : mInit(0), mTrue(0) {}
private:
friend struct Scheduler;
uint16_t mInit; // 初始优先级
uint16_t mTrue; // 调度过程中的真实优先级
};
using TaskRef = std::shared_ptr<ITask>;
// 任务调度
struct Scheduler
{
Scheduler();
void lock() { pthread_mutex_lock(&mMutex); }
void unlock() { pthread_mutex_unlock(&mMutex); }
void wait() { pthread_cond_wait(&mCond, &mMutex); }
void notify() { pthread_cond_broadcast(&mCond); }
void stop() { mQuit = true; }
void onstop() { mStopCnt.fetch_add(1); }
void join()
{
while (true)
{
if (mList.empty())
stop();
if (mStopCnt.load() >= 3)
break;
notify();
// sleep(10);
}
}
void addTask(TaskRef task, uint16_t init)
{
// lock();
task->mInit = init;
task->mTrue = init;
mList.push_back(task);
// unlock();
}
bool getTask(TaskRef &task)
{
if (mList.empty() == false)
{
task = mList.front();
mList.pop_front();
for (auto &item : mList)
++item->mTrue; // 更新优先级
return true;
}
return false;
}
private:
std::list<TaskRef> mList; // 任务链表
volatile bool mQuit = false;
// pthread_spinlock_t mSpin; // 调度自旋锁
pthread_mutex_t mMutex;
pthread_cond_t mCond;
pthread_t threads[3];
volatile std::atomic_int32_t mStopCnt;
static void *worker(void *userpoint);
};
Scheduler::Scheduler()
{
mStopCnt = 0;
pthread_attr_t attr;
/* Initialize mutex and condition variable objects */
pthread_mutex_init(&mMutex, NULL);
pthread_cond_init(&mCond, NULL);
/* For portability, explicitly create threads in a joinable state */
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
pthread_create(&threads[0], &attr, worker, this);
pthread_create(&threads[1], &attr, worker, this);
pthread_create(&threads[2], &attr, worker, this);
}
void *Scheduler::worker(void *userpoint)
{
TaskRef task;
Scheduler &domain = *(Scheduler *)userpoint;
while (true)
{
task.reset();
domain.lock();
if (domain.getTask(task) == false)
{
domain.wait();
}
domain.unlock();
if (task.get() != nullptr)
task->handling();
// 判断是否销毁线程池
if (domain.mQuit == true)
break;
}
domain.onstop();
printf("线程[%d] 退出!\n",pthread_self());
return nullptr;
}
//-----------------------------------------测试----------------------------------
struct TaskA : public ITask
{
TaskA(int id, int serial) : mID(id), mSerial(serial) {}
int mID, mSerial;
void handling() override
{
printf("%d: int32 serial number = %d\n", mID, mSerial);
}
};
struct TaskB : public ITask
{
TaskB(int id, float serial) : mID(id), mSerial(serial) {}
int mID;
float mSerial;
void handling() override
{
printf("%d: float serial number = %f\n", mID, mSerial);
}
};
template <typename type, typename... arg>
TaskRef maketask(arg... args)
{
auto tsk = new type(args...);
auto ref = std::make_shared<ITask>();
ref.reset(tsk);
return ref;
}
int main(int argc, char *argv[])
{
Scheduler domain;
int id = 0;
while (true)
{
domain.lock();
domain.addTask(maketask<TaskA>(++id, id * 10), id % 6);
domain.addTask(maketask<TaskA>(++id, id * 100), id % 6);
domain.addTask(maketask<TaskA>(++id, id * 1000), id % 6);
domain.addTask(maketask<TaskB>(++id, id * 3.14159), id % 6);
domain.addTask(maketask<TaskB>(++id, id * 18.2345), id % 6);
domain.addTask(maketask<TaskB>(++id, id * 32.4568), id % 6);
domain.unlock();
domain.notify();
if (id > 100)
break;
}
// domain.stop();
domain.join();
printf("任务全部处理完成\n");
return 0;
}注意事项
实际开发的过程中要使用锁等同步机制。
8.2 深入理解引用计数:原理、实现与应用
在现代编程中,尤其是在处理动态内存管理和对象生命周期控制方面,引用计数是一种极为重要的技术。它为我们提供了一种高效且相对直观的方式来管理对象的创建与销毁,确保资源在不再被使用时能够被正确地释放,避免内存泄漏等问题的发生。本文将深入探讨引用计数的相关知识,并结合一段具体的代码实现来详细解析其工作原理和实际应用场景。
代码未进行运行测试,只是一个原理描述
二、引用计数的基本概念
引用计数的核心思想非常简单:为每个对象维护一个计数器,记录当前有多少个引用指向该对象。当一个新的引用指向对象时,计数器加 1;当一个引用不再指向对象时,计数器减 1。当计数器的值变为 0 时,表示该对象不再被任何引用所指向,此时可以安全地释放该对象所占用的资源。
这种机制的优势在于它能够自动处理对象的生命周期,只要程序员正确地管理引用的增加和减少,就不需要手动去跟踪对象何时应该被销毁。这在复杂的程序结构中,尤其是涉及到对象之间相互引用的情况下,大大降低了内存管理的难度和出错的概率。
三、代码中的引用计数实现
我们来看一段代码示例,它实现了一个包含引用计数和弱引用机制的对象头结构。
(一)对象头结构定义
首先是 ObjectHD 结构体,它作为对象的头部信息,包含了多个重要的成员变量:
struct ObjectHD
{
// 弱引用记录块
struct WeakRefBlk
{
void *mType; // 类型标记
std::atomic<ObjectHD *> mObject; // 对象回访指针
std::atomic_int32_t mWeakRef; // 弱引用计数
std::atomic_flag mSpinlock; // 自旋锁定
};
union
{
WeakRefBlk *mWeakRef;
void *mType; // 类型标记
} mMetaInfo; // 元数据
std::atomic_int32_t mRefCount; // 引用计数
std::atomic_flag mSpinlock; // 自旋锁定
std::atomic_uint8_t mWeakRef; // 存在弱引用
std::atomic_flag mObjlock; // 对象锁
volatile uint8_t arrcols; // 数组维度
};在这个结构中,mRefCount 就是用于记录对象引用计数的变量。mSpinlock 是一个自旋锁,用于在多线程环境下对对象的引用计数操作进行同步,防止并发冲突。WeakRefBlk 结构体则是用于处理弱引用相关信息,包括弱引用计数 mWeakRef 和自旋锁 mSpinlock 等。
(二)引用对象函数 ref_obj
ObjectHD *ref_obj(ObjectHD *objptr)
{
// objref==nullptr 说明本身没有对象,不应该引用
while (objptr!= nullptr)
{
ObjectHD &obj = *objptr;
// 尝试加锁
auto old = obj.mSpinlock.test_and_set();
// 已被锁定
if (old == true)
{
// 可以睡眠一下:后再循环中继续尝试
std::this_thread::sleep_for(std::chrono::microseconds(1));
continue;
}
// 已经加锁成功,进行引用操作
obj.mRefCount.fetch_add(1);
// 解锁
obj.mSpinlock.clear();
// sizeof(std::atomic_flag);
}
return objptr;
}这个函数用于增加对象的引用计数。它首先检查传入的对象指针是否为空,如果不为空,则尝试获取对象的自旋锁。如果锁已经被其他线程获取(old == true),则当前线程睡眠一小段时间后再次尝试获取锁。一旦成功获取锁,就使用 fetch_add 原子操作将引用计数加 1,然后释放锁并返回对象指针。
(三)解引用函数 unref_obj
ObjectHD *unref_obj(ObjectHD *objptr)
{
// objref==nullptr 说明本身没有对象,不应该引用
while (objptr!= nullptr)
{
ObjectHD &obj = *objptr;
// 尝试加锁
auto old = obj.mSpinlock.test_and_set();
// 已被锁定
if (old == true)
{
// 可以睡眠一下:后再循环中继续尝试
std::this_thread::sleep_for(std::chrono::microseconds(1));
continue;
}
// 已经加锁成功,进行引用操作
obj.mRefCount.fetch_sub(1);
// 引用计数为0,可以释放对象了
if (obj.mRefCount.load() == 0)
{
// 判断是否有弱引用
if (obj.mWeakRef!= 0)
{
// 先对弱引用计数块加锁
while (obj.mMetaInfo.mWeakRef->mSpinlock.test_and_set() == true)
;
obj.mMetaInfo.mWeakRef->mObject->store(nullptr);
// 解锁
obj.mMetaInfo.mWeakRef->mSpinlock.clear();
}
delete objptr;
}
// 解锁
obj.mSpinlock.clear();
// sizeof(std::atomic_flag);
}
return objptr;
}unref_obj 函数用于减少对象的引用计数。与 ref_obj 类似,它先获取对象的自旋锁,然后使用 fetch_sub 原子操作将引用计数减 1。如果引用计数减为 0,说明该对象不再被引用,此时需要进一步检查是否存在弱引用。如果存在弱引用,则先对弱引用计数块加锁,将弱引用指向的对象指针设置为空,然后解锁弱引用计数块,最后释放对象本身。
四、弱引用与引用计数的关系
在上述代码中,还涉及到了弱引用的相关操作。弱引用是一种特殊的引用类型,它不会影响对象的引用计数。弱引用主要用于解决对象之间相互引用导致的循环引用问题。例如,对象 A 引用对象 B,同时对象 B 又引用对象 A,如果仅仅使用普通的引用计数,这两个对象的引用计数将永远不会变为 0,从而导致内存泄漏。而弱引用允许对象之间存在这种相互引用关系,同时又不会阻止对象在其他强引用都消失时被正确地释放。
(一)从引用对象中记录弱引用计数函数 weak_ref_form_refobj
ObjectHD::WeakRefBlk *weak_ref_form_refobj(ObjectHD *objptr)
{
ObjectHD::WeakRefBlk *blk = nullptr;
// objref==nullptr 说明本身没有对象,不应该引用
while (objptr!= nullptr)
{
ObjectHD &obj = *objptr;
// 尝试加锁
auto old = obj.mSpinlock.test_and_set();
// 已被锁定
if (old == true)
{
// 可以睡眠一下:后再循环中继续尝试
std::this_thread::sleep_for(std::chrono::microseconds(10));
continue;
}
// 已经加锁成功,进行引用操作
{
// 当前还不存在弱引用,所以该该建立弱引用,分配弱引用记录快
if (obj.mWeakRef == 0)
{
auto type = obj.mMetaInfo.mType;
obj.mMetaInfo.mWeakRef = new ObjectHD::WeakRefBlk();
obj.mMetaInfo.mWeakRef->mType = type;
obj.mMetaInfo.mWeakRef->mObject->store(objptr);
obj.mMetaInfo.mWeakRef->mWeakRef = 1;
obj.mMetaInfo.mWeakRef->mSpinlock.clear();
obj.mWeakRef = 1;
}
// 已经存在弱引用
else
{
// 先对弱引用计数块加锁
while (obj.mMetaInfo.mWeakRef->mSpinlock.test_and_set() == true)
;
obj.mMetaInfo.mWeakRef->mWeakRef++;
// 解锁
obj.mMetaInfo.mWeakRef->mSpinlock.clear();
}
blk = obj.mMetaInfo.mWeakRef;
}
// 解锁
obj.mSpinlock.clear();
}
return blk;
}这个函数用于从一个强引用对象中创建或更新弱引用计数。如果对象当前不存在弱引用,则创建一个新的 WeakRefBlk 结构体,初始化其相关成员变量,并将对象的 mWeakRef 标记设置为 1。如果已经存在弱引用,则对弱引用计数块加锁后将弱引用计数加 1。
(二)从弱引用对象中记录弱引用计数函数 weak_ref_form_weakobj
ObjectHD::WeakRefBlk *weak_ref_form_weakobj(ObjectHD::WeakRefBlk *weakptr)
{
// 注意弱引用锁的优先级低于对象引用锁
while (weakptr!= nullptr)
{
// 先加锁
auto old = weakptr->mSpinlock.test_and_set();
// 已被加锁
if (old == true)
{
// 可以睡眠一下:后再循环中继续尝试
std::this_thread::sleep_for(std::chrono::microseconds(10));
continue;
}
// 加锁成功,进而给对象加锁
if (weakptr->mObject!= nullptr)
{
auto &obj = *weakptr->mObject->load();
auto old = obj.mSpinlock.test_and_set();
// 对象已经加锁,就重新来过
if (old == true)
{
// 释放锁
weakptr->mSpinlock.clear();
continue;
}
// 加锁成功,引用计数加一
weakptr->mWeakRef++;
// 解锁
obj.mSpinlock.clear();
}
// 释放锁
weakptr->mSpinlock.clear();
}
return weakptr;
}该函数用于从一个弱引用对象中增加弱引用计数。它先获取弱引用对象的自旋锁,如果弱引用指向的对象不为空,则进一步获取对象的自旋锁,然后增加弱引用计数,最后依次释放对象锁和弱引用锁。
(三)释放弱引用函数 unref_weak_obj
void unref_weak_obj(ObjectHD::WeakRefBlk *weakptr)
{
if (weakptr == nullptr)
return;
// 注意弱引用锁的优先级低于对象引用锁
while (true)
{
// 先加锁
auto old = weakptr->mSpinlock.test_and_set();
// 已被加锁
if (old == true)
{
// 可以睡眠一下:后再循环中继续尝试
std::this_thread::sleep_for(std::chrono::microseconds(10));
continue;
}
// 加锁成功,进而给对象加锁
if (weakptr->mObject!= nullptr)
{
auto &obj = *weakptr->mObject->load();
auto old = obj.mSpinlock.test_and_set();
// 对象已经加锁,就重新来过
if (old == true)
{
// 释放锁
weakptr->mSpinlock.clear();
continue;
}
// 加锁成功,弱引用计数-1
weakptr->mWeakRef--;
// 弱引用计数为0,释放弱记录块
if (weakptr->mWeakRef == 0)
{
// 重新恢复对象的meta信息
obj.mMetaInfo.mType = weakptr->mType;
obj.mWeakRef.store(0);
// 释放弱记录块对象
delete weakptr;
return;
}
// 解锁
obj.mSpinlock.clear();
}
// 对象已经被释放
else
{ // 加锁成功,弱引用计数-1
weakptr->mWeakRef--;
// 弱引用计数为0,释放弱记录块
if (weakptr->mWeakRef == 0)
{
// 释放弱记录块对象
delete weakptr;
return;
}
}
// 弱引用记录不为0, 释放锁
weakptr->mSpinlock.clear();
}
}unref_weak_obj 函数用于减少弱引用计数。它先获取弱引用对象的自旋锁,如果弱引用指向的对象存在,则获取对象的自旋锁,然后减少弱引用计数。如果弱引用计数变为 0,则恢复对象的元数据信息,将对象的 mWeakRef 标记设置为 0,并释放弱引用记录块对象。
(四)获取对象函数 get_obj_from_weakobj
ObjectHD *get_obj_from_weakobj(ObjectHD::WeakRefBlk *weakptr)
{
ObjectHD *ret = nullptr;
// 注意弱引用锁的优先级低于对象引用锁
while (weakptr!= nullptr)
{
// 先加锁
auto old = weakptr->mSpinlock.test_and_set();
// 已被加锁
if (old == true)
{
// 可以睡眠一下:后再循环中继续尝试
std::this_thread::sleep_for(std::chrono::microseconds(10));
continue;
}
// 加锁成功,进而给对象加锁
if (weakptr->mObject!= nullptr)
{
auto &obj = *weakptr->mObject->load();
auto old = obj.mSpinlock.test_and_set();
// 对象已经加锁,就重新来过
if (old == true)
{
// 释放锁
weakptr->mSpinlock.clear();
continue;
}
// 加锁成功,引用计数加一
weakptr->mWeakRef++;
// 解锁
obj.mSpinlock.clear();
}
// 释放锁
weakptr->mSpinlock.clear();
}
return ret;
}这个函数用于从弱引用对象中获取所指向的对象。它的操作过程与增加弱引用计数类似,先获取弱引用对象的自旋锁,如果弱引用指向的对象存在,则获取对象的自旋锁并增加弱引用计数,最后返回获取到的对象指针(在示例代码中返回值始终为 nullptr,可能是代码尚未完整实现获取对象的逻辑)。
五、多线程环境下的考虑
在多线程环境中,对引用计数和弱引用计数的操作必须是线程安全的。上述代码中使用自旋锁来实现这一点。自旋锁的特点是当线程获取锁失败时,不会立即进入睡眠状态,而是在一个循环中不断尝试获取锁,这样可以减少线程上下文切换的开销。但是,如果自旋时间过长,也会浪费 CPU 资源。因此,在代码中还设置了睡眠等待的逻辑,当自旋一定时间后仍然无法获取锁时,线程会睡眠一小段时间后再次尝试。
例如在 ref_obj、unref_obj 等函数中,都先尝试获取自旋锁,如果锁已经被占用,则根据情况进行睡眠等待,然后再次尝试获取锁,以确保在多线程并发访问对象引用计数和弱引用计数时的正确性和一致性。
六、总结
引用计数是一种强大的内存管理技术,通过对对象引用数量的精确跟踪,能够有效地管理对象的生命周期,避免内存泄漏等问题。在本文所分析的代码中,不仅展示了基本的引用计数实现,还结合了弱引用机制来处理复杂的对象引用关系,并且充分考虑了多线程环境下的同步问题。深入理解引用计数及其相关的弱引用、多线程同步等知识,对于编写高效、稳定且内存安全的程序具有极为重要的意义。无论是在开发大型应用程序还是在深入研究编程语言的底层机制时,引用计数都是一个不可或缺的重要概念。希望通过本文的介绍,读者能够对引用计数有更深入的理解,并能够在实际编程中灵活运用。